 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster VGGT with Block-Sparse Global Attention
Sep 08, 2025Efficient and accurate feed-forward multi-view reconstruction has long been an important task in computer vision. Recent transformer-based models like VGGT and $\pi^3$ have achieved impressive results with simple architectures, yet they face an inherent runtime bottleneck, due to the quadratic complexity of the global attention layers, that limits the scalability to large image sets. In this paper, we empirically analyze the global attention matrix of these models and observe that probability mass concentrates on a small subset of patch-patch interactions that correspond to cross-view geometric matches. Motivated by the structured attention and inspired by recent advancement in large language models, we propose a replacement for the dense global attention operation based on highly optimized block-sparse kernels, yielding up to $4\times$ faster inference with comparable task performance. Our retrofit requires no retraining of the backbone, extends to both VGGT and $\pi^3$, and supports large image collections. Evaluations on a comprehensive suite of multi-view benchmarks demonstrate the effectiveness of our approach.
OpenSplat3D: Open-Vocabulary 3D Instance Segmentation using Gaussian Splatting
Jun 09, 2025
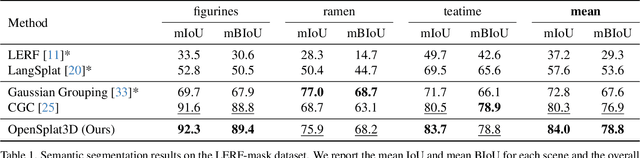

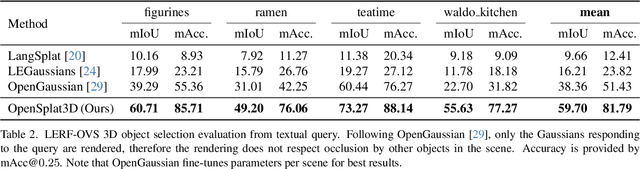
3D Gaussian Splatting (3DGS) has emerged as a powerful representation for neural scene reconstruction, offering high-quality novel view synthesis while maintaining computational efficiency. In this paper, we extend the capabilities of 3DGS beyond pure scene representation by introducing an approach for open-vocabulary 3D instance segmentation without requiring manual labeling, termed OpenSplat3D. Our method leverages feature-splatting techniques to associate semantic information with individual Gaussians, enabling fine-grained scene understanding. We incorporate Segment Anything Model instance masks with a contrastive loss formulation as guidance for the instance features to achieve accurate instance-level segmentation. Furthermore, we utilize language embeddings of a vision-language model, allowing for flexible, text-driven instance identification. This combination enables our system to identify and segment arbitrary objects in 3D scenes based on natural language descriptions. We show results on LERF-mask and LERF-OVS as well as the full ScanNet++ validation set, demonstrating the effectiveness of our approach.
PCA for Enhanced Cross-Dataset Generalizability in Breast Ultrasound Tumor Segmentation
May 29, 2025In medical image segmentation, limited external validity remains a critical obstacle when models are deployed across unseen datasets, an issue particularly pronounced in the ultrasound image domain. Existing solutions-such as domain adaptation and GAN-based style transfer-while promising, often fall short in the medical domain where datasets are typically small and diverse. This paper presents a novel application of principal component analysis (PCA) to address this limitation. PCA preprocessing reduces noise and emphasizes essential features by retaining approximately 90\% of the dataset variance. We evaluate our approach across six diverse breast tumor ultrasound datasets comprising 3,983 B-mode images and corresponding expert tumor segmentation masks. For each dataset, a corresponding dimensionality reduced PCA-dataset is created and U-Net-based segmentation models are trained on each of the twelve datasets. Each model trained on an original dataset was inferenced on the remaining five out-of-domain original datasets (baseline results), while each model trained on a PCA dataset was inferenced on five out-of-domain PCA datasets. Our experimental results indicate that using PCA reconstructed datasets, instead of original images, improves the model's recall and Dice scores, particularly for model-dataset pairs where baseline performance was lowest, achieving statistically significant gains in recall (0.57 $\pm$ 0.07 vs. 0.70 $\pm$ 0.05, $p = 0.0004$) and Dice scores (0.50 $\pm$ 0.06 vs. 0.58 $\pm$ 0.06, $p = 0.03$). Our method reduced the decline in recall values due to external validation by $33\%$. These findings underscore the potential of PCA reconstruction as a safeguard to mitigate declines in segmentation performance, especially in challenging cases, with implications for enhancing external validity in real-world medical applications.
Look Gauss, No Pose: Novel View Synthesis using Gaussian Splatting without Accurate Pose Initialization
Oct 11, 2024

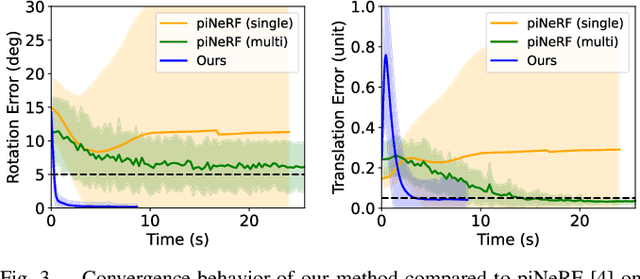
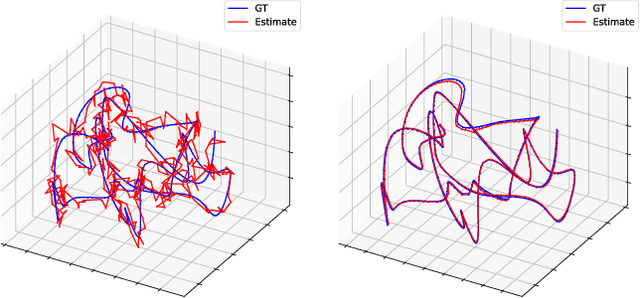
3D Gaussian Splatting has recently emerged as a powerful tool for fast and accurate novel-view synthesis from a set of posed input images. However, like most novel-view synthesis approaches, it relies on accurate camera pose information, limiting its applicability in real-world scenarios where acquiring accurate camera poses can be challenging or even impossible. We propose an extension to the 3D Gaussian Splatting framework by optimizing the extrinsic camera parameters with respect to photometric residuals. We derive the analytical gradients and integrate their computation with the existing high-performance CUDA implementation. This enables downstream tasks such as 6-DoF camera pose estimation as well as joint reconstruction and camera refinement. In particular, we achieve rapid convergence and high accuracy for pose estimation on real-world scenes. Our method enables fast reconstruction of 3D scenes without requiring accurate pose information by jointly optimizing geometry and camera poses, while achieving state-of-the-art results in novel-view synthesis. Our approach is considerably faster to optimize than most competing methods, and several times faster in rendering. We show results on real-world scenes and complex trajectories through simulated environments, achieving state-of-the-art results on LLFF while reducing runtime by two to four times compared to the most efficient competing method. Source code will be available at https://github.com/Schmiddo/noposegs .
Fine-Tuning Image-Conditional Diffusion Models is Easier than You Think
Sep 17, 2024



Recent work showed that large diffusion models can be reused as highly precise monocular depth estimators by casting depth estimation as an image-conditional image generation task. While the proposed model achieved state-of-the-art results, high computational demands due to multi-step inference limited its use in many scenarios. In this paper, we show that the perceived inefficiency was caused by a flaw in the inference pipeline that has so far gone unnoticed. The fixed model performs comparably to the best previously reported configuration while being more than 200$\times$ faster. To optimize for downstream task performance, we perform end-to-end fine-tuning on top of the single-step model with task-specific losses and get a deterministic model that outperforms all other diffusion-based depth and normal estimation models on common zero-shot benchmarks. We surprisingly find that this fine-tuning protocol also works directly on Stable Diffusion and achieves comparable performance to current state-of-the-art diffusion-based depth and normal estimation models, calling into question some of the conclusions drawn from prior works.
Impact of PCA-based preprocessing and different CNN structures on deformable registration of sonograms
Jan 20, 2023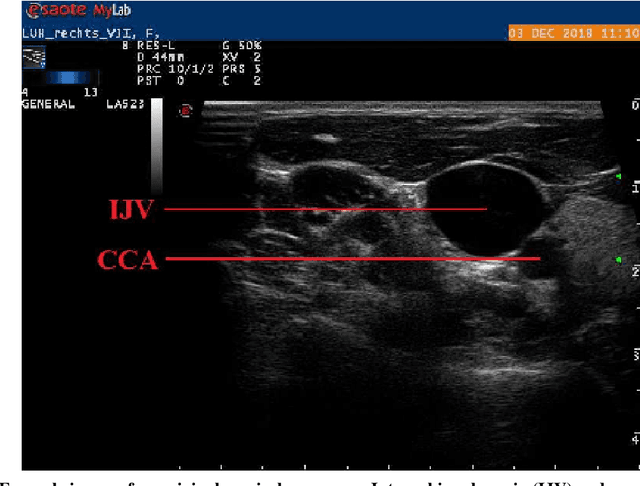
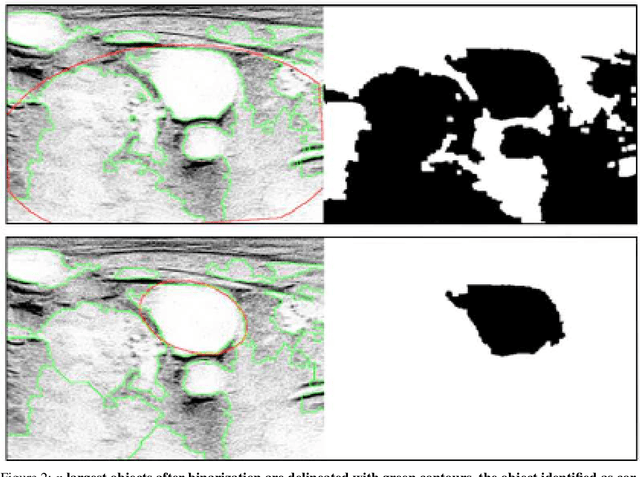
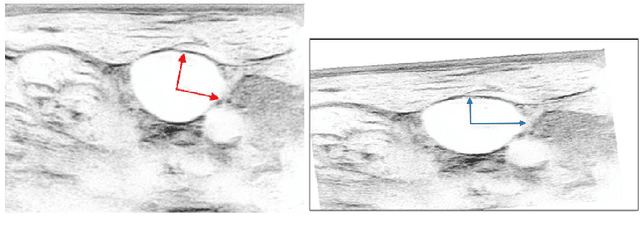
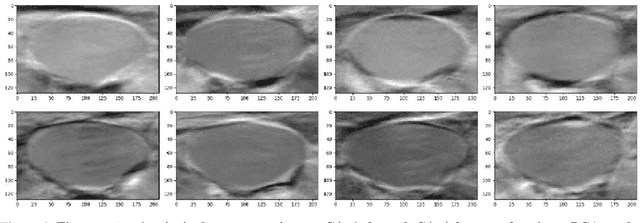
Central venous catheters (CVC) are commonly inserted into the large veins of the neck, e.g. the internal jugular vein (IJV). CVC insertion may cause serious complications like misplacement into an artery or perforation of cervical vessels. Placing a CVC under sonographic guidance is an appropriate method to reduce such adverse events, if anatomical landmarks like venous and arterial vessels can be detected reliably. This task shall be solved by registration of patient individual images vs. an anatomically labelled reference image. In this work, a linear, affine transformation is performed on cervical sonograms, followed by a non-linear transformation to achieve a more precise registration. Voxelmorph (VM), a learning-based library for deformable image registration using a convolutional neural network (CNN) with U-Net structure was used for non-linear transformation. The impact of principal component analysis (PCA)-based pre-denoising of patient individual images, as well as the impact of modified net structures with differing complexities on registration results were examined visually and quantitatively, the latter using metrics for deformation and image similarity. Using the PCA-approximated cervical sonograms resulted in decreased mean deformation lengths between 18% and 66% compared to their original image counterparts, depending on net structure. In addition, reducing the number of convolutional layers led to improved image similarity with PCA images, while worsening in original images. Despite a large reduction of network parameters, no overall decrease in registration quality was observed, leading to the conclusion that the original net structure is oversized for the task at hand.
* 8 pages, 7 figures Presented at WSCG 2022
Estimation of mitral valve hinge point coordinates -- deep neural net for echocardiogram segmentation
Jan 20, 2023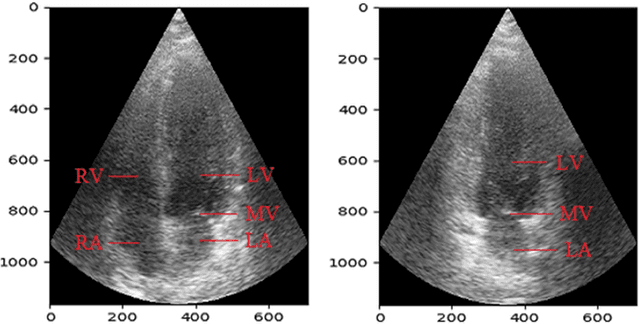
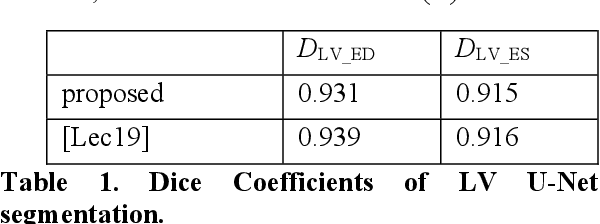
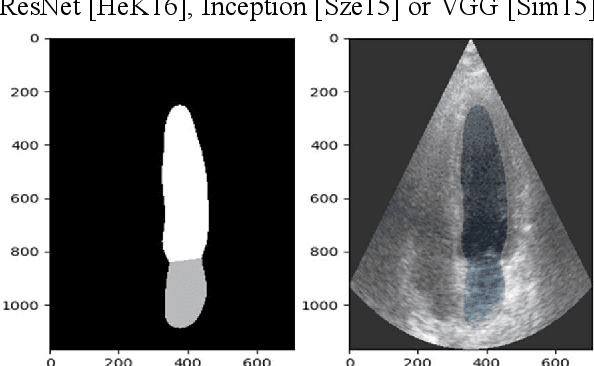
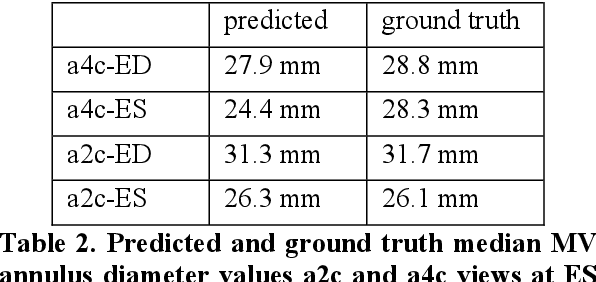
Cardiac image segmentation is a powerful tool in regard to diagnostics and treatment of cardiovascular diseases. Purely feature-based detection of anatomical structures like the mitral valve is a laborious task due to specifically required feature engineering and is especially challenging in echocardiograms, because of their inherently low contrast and blurry boundaries between some anatomical structures. With the publication of further annotated medical datasets and the increase in GPU processing power, deep learning-based methods in medical image segmentation became more feasible in the past years. We propose a fully automatic detection method for mitral valve hinge points, which uses a U-Net based deep neural net to segment cardiac chambers in echocardiograms in a first step, and subsequently extracts the mitral valve hinge points from the resulting segmentations in a second step. Results measured with this automatic detection method were compared to reference coordinate values, which with median absolute hinge point coordinate errors of 1.35 mm for the x- (15-85 percentile range: [0.3 mm; 3.15 mm]) and 0.75 mm for the y- coordinate (15-85 percentile range: [0.15 mm; 1.88 mm]).
* 8 Pages, 11 figures Presented at WSCG 2022
D^2Conv3D: Dynamic Dilated Convolutions for Object Segmentation in Videos
Nov 15, 2021
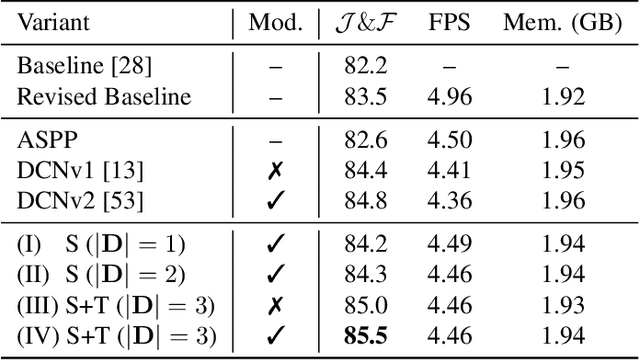
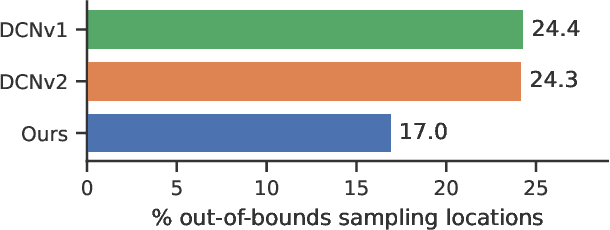
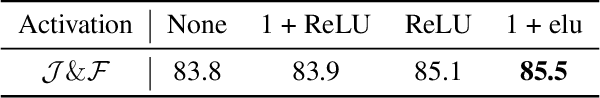
Despite receiving significant attention from the research community, the task of segmenting and tracking objects in monocular videos still has much room for improvement. Existing works have simultaneously justified the efficacy of dilated and deformable convolutions for various image-level segmentation tasks. This gives reason to believe that 3D extensions of such convolutions should also yield performance improvements for video-level segmentation tasks. However, this aspect has not yet been explored thoroughly in existing literature. In this paper, we propose Dynamic Dilated Convolutions (D^2Conv3D): a novel type of convolution which draws inspiration from dilated and deformable convolutions and extends them to the 3D (spatio-temporal) domain. We experimentally show that D^2Conv3D can be used to improve the performance of multiple 3D CNN architectures across multiple video segmentation related benchmarks by simply employing D^2Conv3D as a drop-in replacement for standard convolutions. We further show that D^2Conv3D out-performs trivial extensions of existing dilated and deformable convolutions to 3D. Lastly, we set a new state-of-the-art on the DAVIS 2016 Unsupervised Video Object Segmentation benchmark. Code is made publicly available at https://github.com/Schmiddo/d2conv3d .
Deep Deterministic Portfolio Optimization
Apr 09, 2020
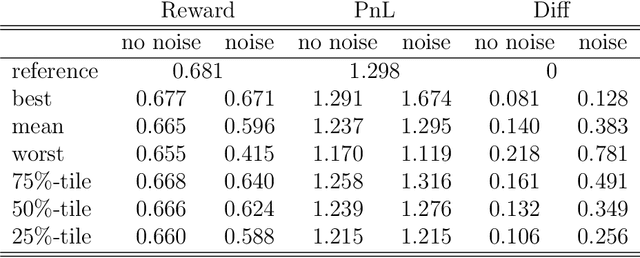
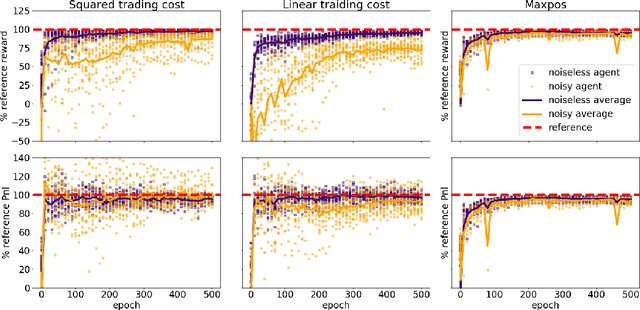
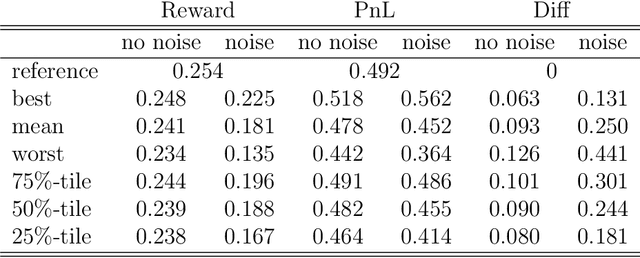
Can deep reinforcement learning algorithms be exploited as solvers for optimal trading strategies? The aim of this work is to test reinforcement learning algorithms on conceptually simple, but mathematically non-trivial, trading environments. The environments are chosen such that an optimal or close-to-optimal trading strategy is known. We study the deep deterministic policy gradient algorithm and show that such a reinforcement learning agent can successfully recover the essential features of the optimal trading strategies and achieve close-to-optimal rewards.
Dense Limit of the Dawid-Skene Model for Crowdsourcing and Regions of Sub-optimality of Message Passing Algorithms
Mar 15, 2018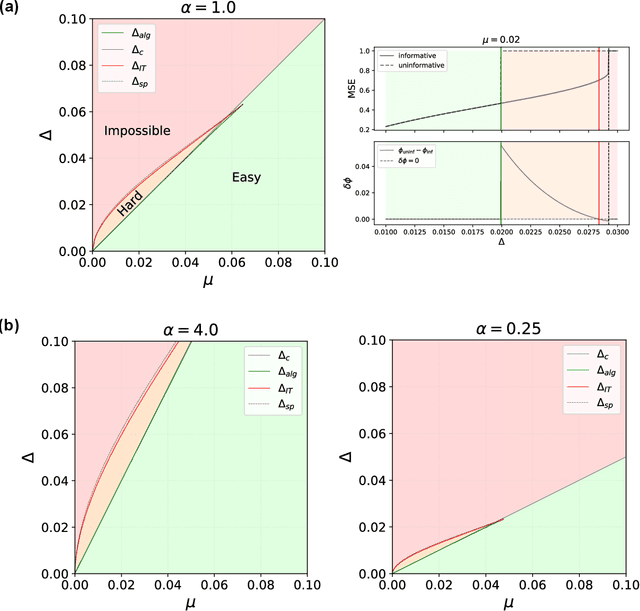
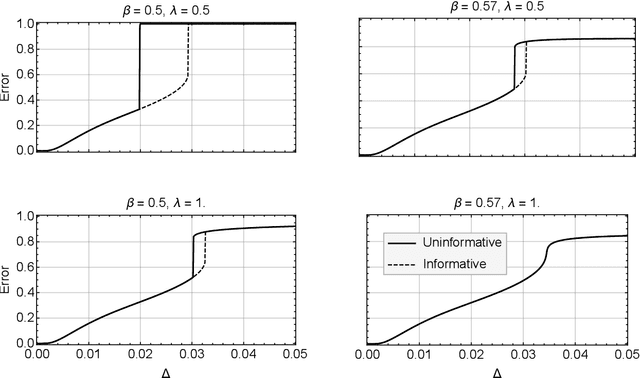
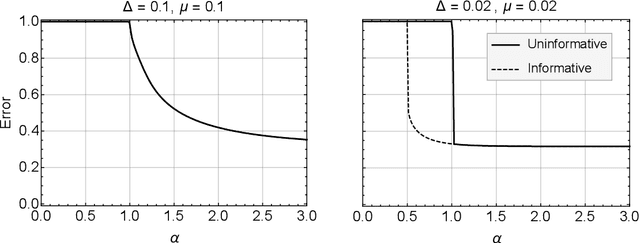
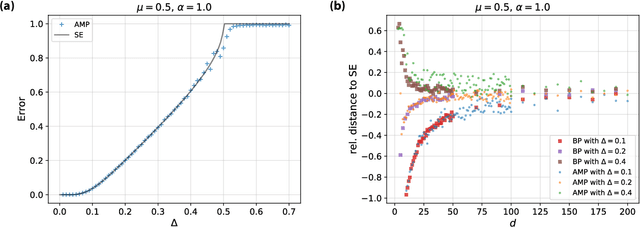
Crowdsourcing is a strategy to categorize data through the contribution of many individuals. A wide range of theoretical and algorithmic contributions are based on the model of Dawid and Skene [1]. Recently it was shown in [2,3] that, in certain regimes, belief propagation is asymptotically optimal for data generated from the Dawid-Skene model. This paper is motivated by this recent progress. We analyze the dense limit of the Dawid-Skene model. It is shown that it belongs to a larger class of low-rank matrix estimation problems for which it is possible to express the asymptotic, Bayes-optimal, performance in a simple closed form. In the dense limit the mapping to a low-rank matrix estimation problem provides an approximate message passing algorithm that solves the problem algorithmically. We identify the regions where the algorithm efficiently computes the Bayes-optimal estimates. Our analysis refines the results of [2,3] about optimality of message passing algorithms by characterizing regions of parameters where these algorithms do not match the Bayes-optimal performance. We further study numerically the performance of approximate message passing, derived in the dense limit, on sparse instances and carry out experiments on a real world dataset.