 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow do Foundation Models Compare to Skeleton-Based Approaches for Gesture Recognition in Human-Robot Interaction?
Jun 25, 2025Gestures enable non-verbal human-robot communication, especially in noisy environments like agile production. Traditional deep learning-based gesture recognition relies on task-specific architectures using images, videos, or skeletal pose estimates as input. Meanwhile, Vision Foundation Models (VFMs) and Vision Language Models (VLMs) with their strong generalization abilities offer potential to reduce system complexity by replacing dedicated task-specific modules. This study investigates adapting such models for dynamic, full-body gesture recognition, comparing V-JEPA (a state-of-the-art VFM), Gemini Flash 2.0 (a multimodal VLM), and HD-GCN (a top-performing skeleton-based approach). We introduce NUGGET, a dataset tailored for human-robot communication in intralogistics environments, to evaluate the different gesture recognition approaches. In our experiments, HD-GCN achieves best performance, but V-JEPA comes close with a simple, task-specific classification head - thus paving a possible way towards reducing system complexity, by using it as a shared multi-task model. In contrast, Gemini struggles to differentiate gestures based solely on textual descriptions in the zero-shot setting, highlighting the need of further research on suitable input representations for gestures.
Systematic Comparison of Projection Methods for Monocular 3D Human Pose Estimation on Fisheye Images
Jun 24, 2025Fisheye cameras offer robots the ability to capture human movements across a wider field of view (FOV) than standard pinhole cameras, making them particularly useful for applications in human-robot interaction and automotive contexts. However, accurately detecting human poses in fisheye images is challenging due to the curved distortions inherent to fisheye optics. While various methods for undistorting fisheye images have been proposed, their effectiveness and limitations for poses that cover a wide FOV has not been systematically evaluated in the context of absolute human pose estimation from monocular fisheye images. To address this gap, we evaluate the impact of pinhole, equidistant and double sphere camera models, as well as cylindrical projection methods, on 3D human pose estimation accuracy. We find that in close-up scenarios, pinhole projection is inadequate, and the optimal projection method varies with the FOV covered by the human pose. The usage of advanced fisheye models like the double sphere model significantly enhances 3D human pose estimation accuracy. We propose a heuristic for selecting the appropriate projection model based on the detection bounding box to enhance prediction quality. Additionally, we introduce and evaluate on our novel dataset FISHnCHIPS, which features 3D human skeleton annotations in fisheye images, including images from unconventional angles, such as extreme close-ups, ground-mounted cameras, and wide-FOV poses, available at: https://www.vision.rwth-aachen.de/fishnchips
OpenSplat3D: Open-Vocabulary 3D Instance Segmentation using Gaussian Splatting
Jun 09, 20253D Gaussian Splatting (3DGS) has emerged as a powerful representation for neural scene reconstruction, offering high-quality novel view synthesis while maintaining computational efficiency. In this paper, we extend the capabilities of 3DGS beyond pure scene representation by introducing an approach for open-vocabulary 3D instance segmentation without requiring manual labeling, termed OpenSplat3D. Our method leverages feature-splatting techniques to associate semantic information with individual Gaussians, enabling fine-grained scene understanding. We incorporate Segment Anything Model instance masks with a contrastive loss formulation as guidance for the instance features to achieve accurate instance-level segmentation. Furthermore, we utilize language embeddings of a vision-language model, allowing for flexible, text-driven instance identification. This combination enables our system to identify and segment arbitrary objects in 3D scenes based on natural language descriptions. We show results on LERF-mask and LERF-OVS as well as the full ScanNet++ validation set, demonstrating the effectiveness of our approach.
UPTor: Unified 3D Human Pose Dynamics and Trajectory Prediction for Human-Robot Interaction
May 20, 2025



We introduce a unified approach to forecast the dynamics of human keypoints along with the motion trajectory based on a short sequence of input poses. While many studies address either full-body pose prediction or motion trajectory prediction, only a few attempt to merge them. We propose a motion transformation technique to simultaneously predict full-body pose and trajectory key-points in a global coordinate frame. We utilize an off-the-shelf 3D human pose estimation module, a graph attention network to encode the skeleton structure, and a compact, non-autoregressive transformer suitable for real-time motion prediction for human-robot interaction and human-aware navigation. We introduce a human navigation dataset ``DARKO'' with specific focus on navigational activities that are relevant for human-aware mobile robot navigation. We perform extensive evaluation on Human3.6M, CMU-Mocap, and our DARKO dataset. In comparison to prior work, we show that our approach is compact, real-time, and accurate in predicting human navigation motion across all datasets. Result animations, our dataset, and code will be available at https://nisarganc.github.io/UPTor-page/
Acquisition of high-quality images for camera calibration in robotics applications via speech prompts
Apr 15, 2025


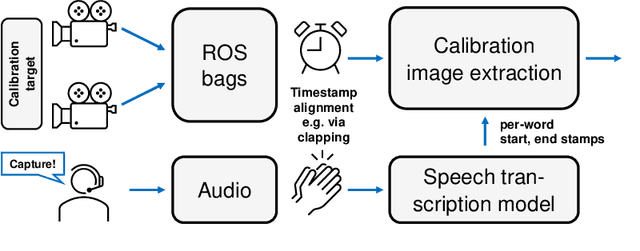
Accurate intrinsic and extrinsic camera calibration can be an important prerequisite for robotic applications that rely on vision as input. While there is ongoing research on enabling camera calibration using natural images, many systems in practice still rely on using designated calibration targets with e.g. checkerboard patterns or April tag grids. Once calibration images from different perspectives have been acquired and feature descriptors detected, those are typically used in an optimization process to minimize the geometric reprojection error. For this optimization to converge, input images need to be of sufficient quality and particularly sharpness; they should neither contain motion blur nor rolling-shutter artifacts that can arise when the calibration board was not static during image capture. In this work, we present a novel calibration image acquisition technique controlled via voice commands recorded with a clip-on microphone, that can be more robust and user-friendly than e.g. triggering capture with a remote control, or filtering out blurry frames from a video sequence in postprocessing. To achieve this, we use a state-of-the-art speech-to-text transcription model with accurate per-word timestamping to capture trigger words with precise temporal alignment. Our experiments show that the proposed method improves user experience by being fast and efficient, allowing us to successfully calibrate complex multi-camera setups.
DINO in the Room: Leveraging 2D Foundation Models for 3D Segmentation
Mar 24, 2025Vision foundation models (VFMs) trained on large-scale image datasets provide high-quality features that have significantly advanced 2D visual recognition. However, their potential in 3D vision remains largely untapped, despite the common availability of 2D images alongside 3D point cloud datasets. While significant research has been dedicated to 2D-3D fusion, recent state-of-the-art 3D methods predominantly focus on 3D data, leaving the integration of VFMs into 3D models underexplored. In this work, we challenge this trend by introducing DITR, a simple yet effective approach that extracts 2D foundation model features, projects them to 3D, and finally injects them into a 3D point cloud segmentation model. DITR achieves state-of-the-art results on both indoor and outdoor 3D semantic segmentation benchmarks. To enable the use of VFMs even when images are unavailable during inference, we further propose to distill 2D foundation models into a 3D backbone as a pretraining task. By initializing the 3D backbone with knowledge distilled from 2D VFMs, we create a strong basis for downstream 3D segmentation tasks, ultimately boosting performance across various datasets.
Cross-Modal Analysis of Human Detection for Robotics: An Industrial Case Study
Aug 03, 2021
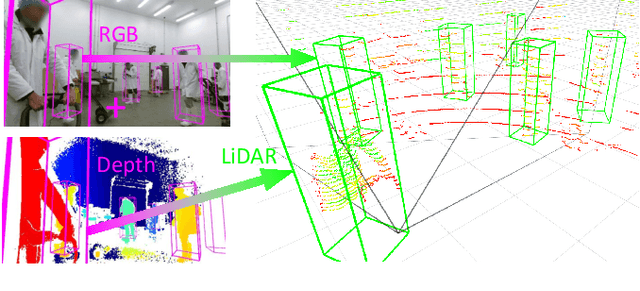
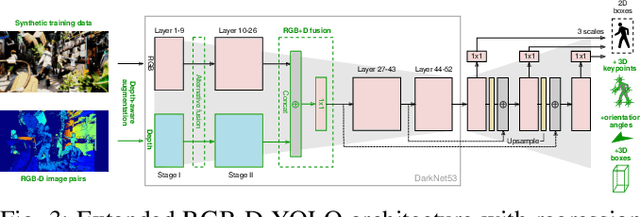
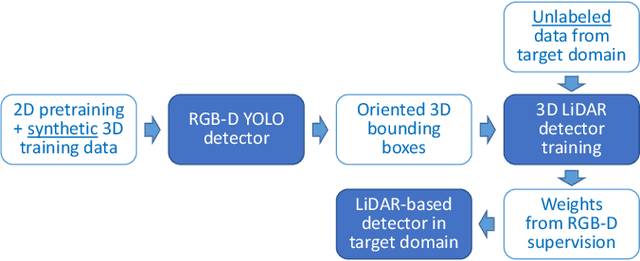
Advances in sensing and learning algorithms have led to increasingly mature solutions for human detection by robots, particularly in selected use-cases such as pedestrian detection for self-driving cars or close-range person detection in consumer settings. Despite this progress, the simple question "which sensor-algorithm combination is best suited for a person detection task at hand?" remains hard to answer. In this paper, we tackle this issue by conducting a systematic cross-modal analysis of sensor-algorithm combinations typically used in robotics. We compare the performance of state-of-the-art person detectors for 2D range data, 3D lidar, and RGB-D data as well as selected combinations thereof in a challenging industrial use-case. We further address the related problems of data scarcity in the industrial target domain, and that recent research on human detection in 3D point clouds has mostly focused on autonomous driving scenarios. To leverage these methodological advances for robotics applications, we utilize a simple, yet effective multi-sensor transfer learning strategy by extending a strong image-based RGB-D detector to provide cross-modal supervision for lidar detectors in the form of weak 3D bounding box labels. Our results show a large variance among the different approaches in terms of detection performance, generalization, frame rates and computational requirements. As our use-case contains difficulties representative for a wide range of service robot applications, we believe that these results point to relevant open challenges for further research and provide valuable support to practitioners for the design of their robot system.
MeTRAbs: Metric-Scale Truncation-Robust Heatmaps for Absolute 3D Human Pose Estimation
Jul 12, 2020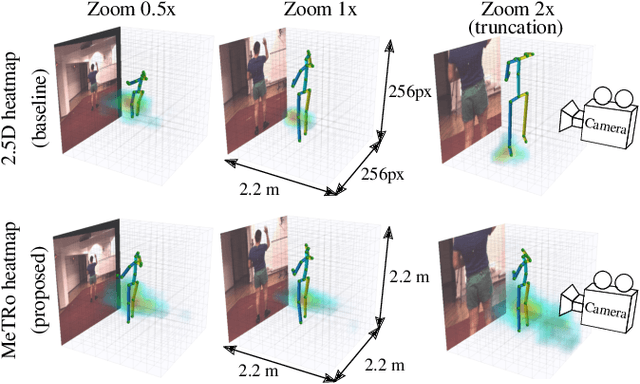
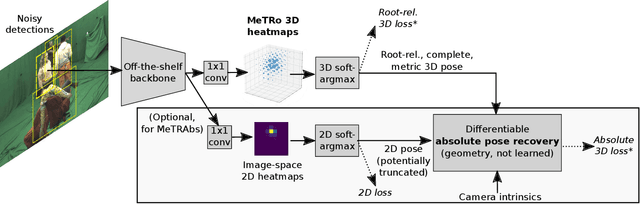
Heatmap representations have formed the basis of human pose estimation systems for many years, and their extension to 3D has been a fruitful line of recent research. This includes 2.5D volumetric heatmaps, whose X and Y axes correspond to image space and Z to metric depth around the subject. To obtain metric-scale predictions, 2.5D methods need a separate post-processing step to resolve scale ambiguity. Further, they cannot localize body joints outside the image boundaries, leading to incomplete estimates for truncated images. To address these limitations, we propose metric-scale truncation-robust (MeTRo) volumetric heatmaps, whose dimensions are all defined in metric 3D space, instead of being aligned with image space. This reinterpretation of heatmap dimensions allows us to directly estimate complete, metric-scale poses without test-time knowledge of distance or relying on anthropometric heuristics, such as bone lengths. To further demonstrate the utility our representation, we present a differentiable combination of our 3D metric-scale heatmaps with 2D image-space ones to estimate absolute 3D pose (our MeTRAbs architecture). We find that supervision via absolute pose loss is crucial for accurate non-root-relative localization. Using a ResNet-50 backbone without further learned layers, we obtain state-of-the-art results on Human3.6M, MPI-INF-3DHP and MuPoTS-3D. Our code will be made publicly available to facilitate further research.
Metric-Scale Truncation-Robust Heatmaps for 3D Human Pose Estimation
Mar 05, 2020


Heatmap representations have formed the basis of 2D human pose estimation systems for many years, but their generalizations for 3D pose have only recently been considered. This includes 2.5D volumetric heatmaps, whose X and Y axes correspond to image space and the Z axis to metric depth around the subject. To obtain metric-scale predictions, these methods must include a separate, explicit post-processing step to resolve scale ambiguity. Further, they cannot encode body joint positions outside of the image boundaries, leading to incomplete pose estimates in case of image truncation. We address these limitations by proposing metric-scale truncation-robust (MeTRo) volumetric heatmaps, whose dimensions are defined in metric 3D space near the subject, instead of being aligned with image space. We train a fully-convolutional network to estimate such heatmaps from monocular RGB in an end-to-end manner. This reinterpretation of the heatmap dimensions allows us to estimate complete metric-scale poses without test-time knowledge of the focal length or person distance and without relying on anthropometric heuristics in post-processing. Furthermore, as the image space is decoupled from the heatmap space, the network can learn to reason about joints beyond the image boundary. Using ResNet-50 without any additional learned layers, we obtain state-of-the-art results on the Human3.6M and MPI-INF-3DHP benchmarks. As our method is simple and fast, it can become a useful component for real-time top-down multi-person pose estimation systems. We make our code publicly available to facilitate further research (see https://vision.rwth-aachen.de/metro-pose3d).
Synthetic Occlusion Augmentation with Volumetric Heatmaps for the 2018 ECCV PoseTrack Challenge on 3D Human Pose Estimation
Nov 06, 2018
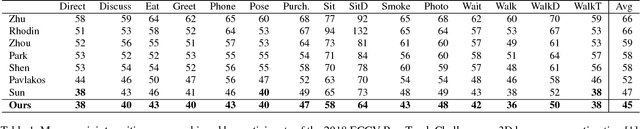
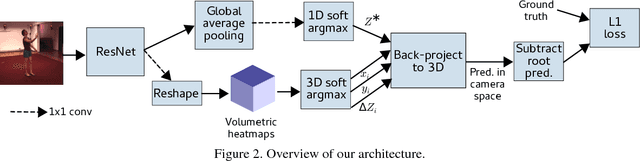
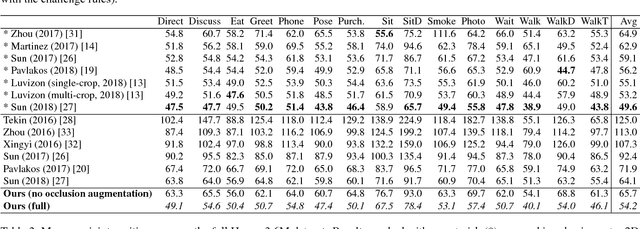
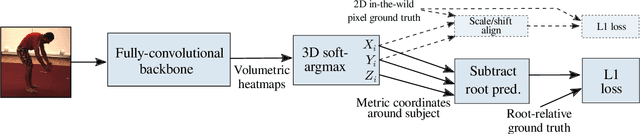
In this paper we present our winning entry at the 2018 ECCV PoseTrack Challenge on 3D human pose estimation. Using a fully-convolutional backbone architecture, we obtain volumetric heatmaps per body joint, which we convert to coordinates using soft-argmax. Absolute person center depth is estimated by a 1D heatmap prediction head. The coordinates are back-projected to 3D camera space, where we minimize the L1 loss. Key to our good results is the training data augmentation with randomly placed occluders from the Pascal VOC dataset. In addition to reaching first place in the Challenge, our method also surpasses the state-of-the-art on the full Human3.6M benchmark among methods that use no additional pose datasets in training. Code for applying synthetic occlusions is availabe at https://github.com/isarandi/synthetic-occlusion.