 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features
Feb 20, 2025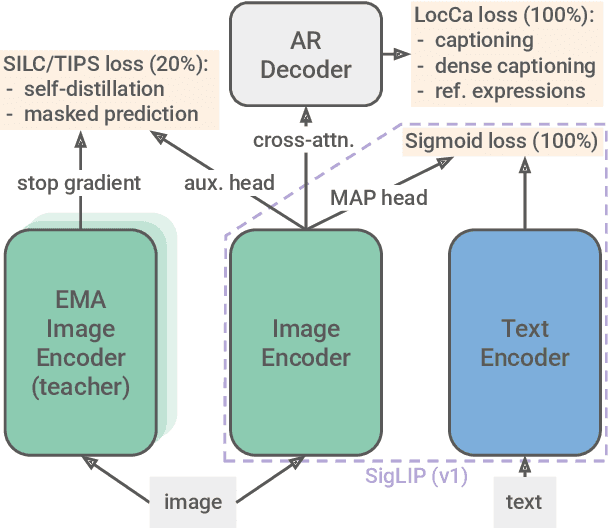
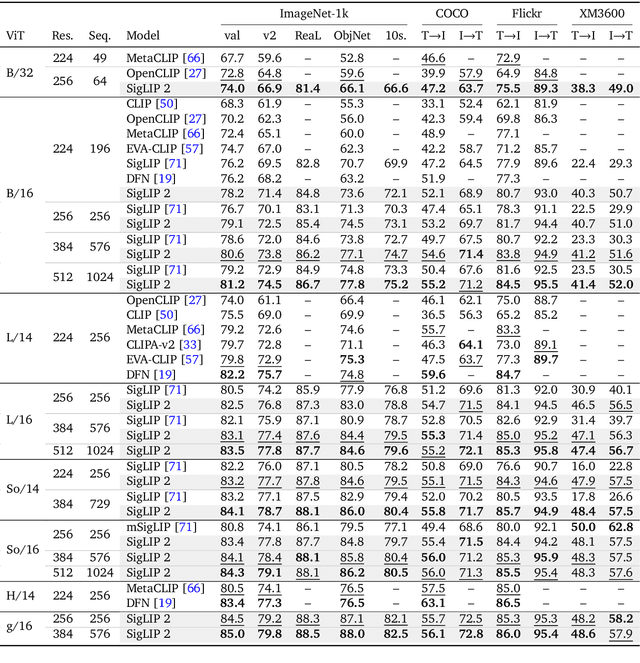
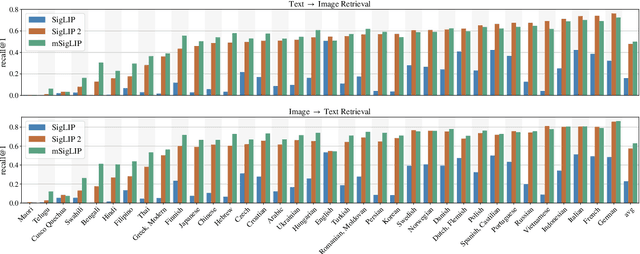
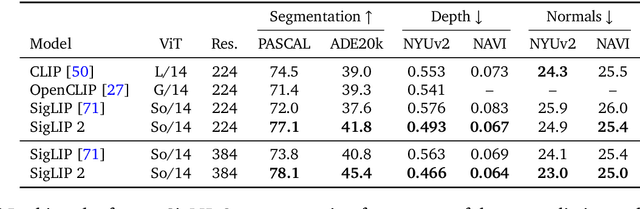
We introduce SigLIP 2, a family of new multilingual vision-language encoders that build on the success of the original SigLIP. In this second iteration, we extend the original image-text training objective with several prior, independently developed techniques into a unified recipe -- this includes captioning-based pretraining, self-supervised losses (self-distillation, masked prediction) and online data curation. With these changes, SigLIP 2 models outperform their SigLIP counterparts at all model scales in core capabilities, including zero-shot classification, image-text retrieval, and transfer performance when extracting visual representations for Vision-Language Models (VLMs). Furthermore, the new training recipe leads to significant improvements on localization and dense prediction tasks. We also train variants which support multiple resolutions and preserve the input's native aspect ratio. Finally, we train on a more diverse data-mixture that includes de-biasing techniques, leading to much better multilingual understanding and improved fairness. To allow users to trade off inference cost with performance, we release model checkpoints at four sizes: ViT-B (86M), L (303M), So400m (400M), and g (1B).
PaliGemma 2: A Family of Versatile VLMs for Transfer
Dec 04, 2024



PaliGemma 2 is an upgrade of the PaliGemma open Vision-Language Model (VLM) based on the Gemma 2 family of language models. We combine the SigLIP-So400m vision encoder that was also used by PaliGemma with the whole range of Gemma 2 models, from the 2B one all the way up to the 27B model. We train these models at three resolutions (224px, 448px, and 896px) in multiple stages to equip them with broad knowledge for transfer via fine-tuning. The resulting family of base models covering different model sizes and resolutions allows us to investigate factors impacting transfer performance (such as learning rate) and to analyze the interplay between the type of task, model size, and resolution. We further increase the number and breadth of transfer tasks beyond the scope of PaliGemma including different OCR-related tasks such as table structure recognition, molecular structure recognition, music score recognition, as well as long fine-grained captioning and radiography report generation, on which PaliGemma 2 obtains state-of-the-art results.
PaliGemma: A versatile 3B VLM for transfer
Jul 10, 2024



PaliGemma is an open Vision-Language Model (VLM) that is based on the SigLIP-So400m vision encoder and the Gemma-2B language model. It is trained to be a versatile and broadly knowledgeable base model that is effective to transfer. It achieves strong performance on a wide variety of open-world tasks. We evaluate PaliGemma on almost 40 diverse tasks including standard VLM benchmarks, but also more specialized tasks such as remote-sensing and segmentation.
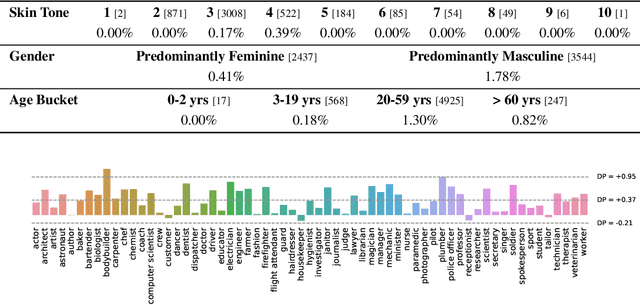
No Filter: Cultural and Socioeconomic Diversityin Contrastive Vision-Language Models
May 22, 2024We study cultural and socioeconomic diversity in contrastive vision-language models (VLMs). Using a broad range of benchmark datasets and evaluation metrics, we bring to attention several important findings. First, the common filtering of training data to English image-text pairs disadvantages communities of lower socioeconomic status and negatively impacts cultural understanding. Notably, this performance gap is not captured by -- and even at odds with -- the currently popular evaluation metrics derived from the Western-centric ImageNet and COCO datasets. Second, pretraining with global, unfiltered data before fine-tuning on English content can improve cultural understanding without sacrificing performance on said popular benchmarks. Third, we introduce the task of geo-localization as a novel evaluation metric to assess cultural diversity in VLMs. Our work underscores the value of using diverse data to create more inclusive multimodal systems and lays the groundwork for developing VLMs that better represent global perspectives.
LocCa: Visual Pretraining with Location-aware Captioners
Mar 28, 2024



Image captioning has been shown as an effective pretraining method similar to contrastive pretraining. However, the incorporation of location-aware information into visual pretraining remains an area with limited research. In this paper, we propose a simple visual pretraining method with location-aware captioners (LocCa). LocCa uses a simple image captioner task interface, to teach a model to read out rich information, i.e. bounding box coordinates, and captions, conditioned on the image pixel input. Thanks to the multitask capabilities of an encoder-decoder architecture, we show that an image captioner can easily handle multiple tasks during pretraining. Our experiments demonstrate that LocCa outperforms standard captioners significantly on localization downstream tasks while maintaining comparable performance on holistic tasks.
PaLI-3 Vision Language Models: Smaller, Faster, Stronger
Oct 17, 2023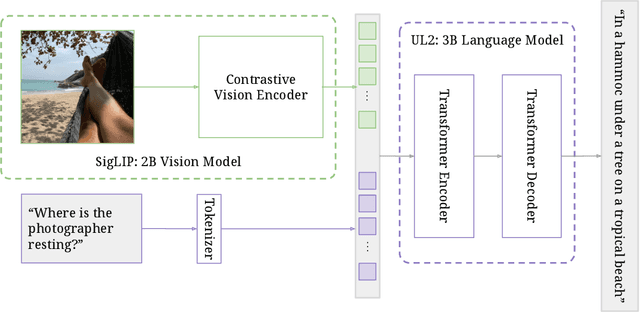
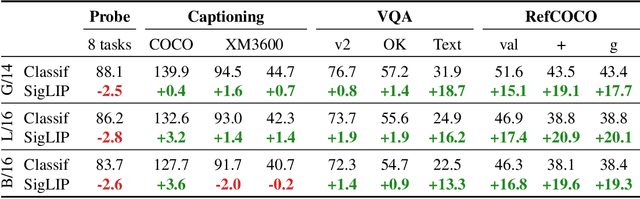
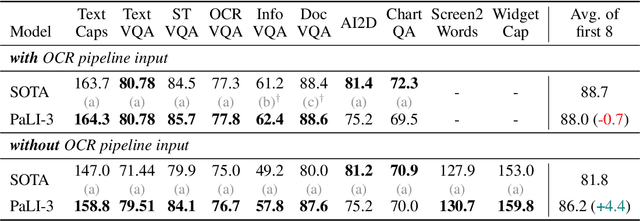
This paper presents PaLI-3, a smaller, faster, and stronger vision language model (VLM) that compares favorably to similar models that are 10x larger. As part of arriving at this strong performance, we compare Vision Transformer (ViT) models pretrained using classification objectives to contrastively (SigLIP) pretrained ones. We find that, while slightly underperforming on standard image classification benchmarks, SigLIP-based PaLI shows superior performance across various multimodal benchmarks, especially on localization and visually-situated text understanding. We scale the SigLIP image encoder up to 2 billion parameters, and achieves a new state-of-the-art on multilingual cross-modal retrieval. We hope that PaLI-3, at only 5B parameters, rekindles research on fundamental pieces of complex VLMs, and could fuel a new generation of scaled-up models.
Image Captioners Are Scalable Vision Learners Too
Jun 13, 2023
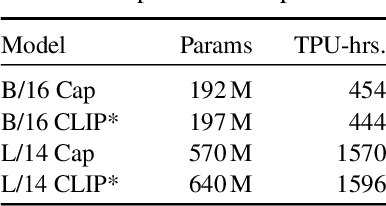
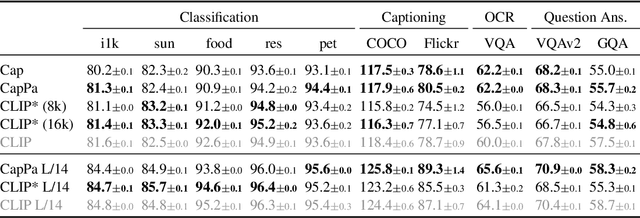

Contrastive pretraining on image-text pairs from the web is one of the most popular large-scale pretraining strategies for vision backbones, especially in the context of large multimodal models. At the same time, image captioning on this type of data is commonly considered an inferior pretraining strategy. In this paper, we perform a fair comparison of these two pretraining strategies, carefully matching training data, compute, and model capacity. Using a standard encoder-decoder transformer, we find that captioning alone is surprisingly effective: on classification tasks, captioning produces vision encoders competitive with contrastively pretrained encoders, while surpassing them on vision & language tasks. We further analyze the effect of the model architecture and scale, as well as the pretraining data on the representation quality, and find that captioning exhibits the same or better scaling behavior along these axes. Overall our results show that plain image captioning is a more powerful pretraining strategy than was previously believed.
PaLI-X: On Scaling up a Multilingual Vision and Language Model
May 29, 2023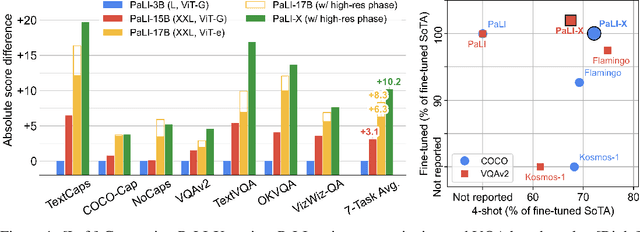
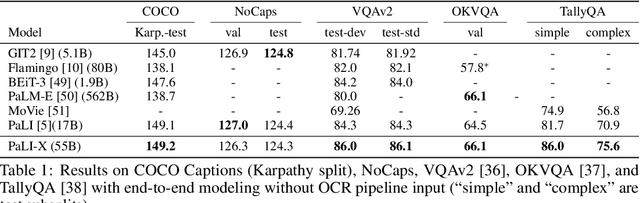
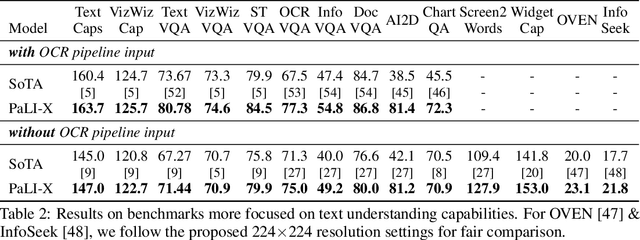

We present the training recipe and results of scaling up PaLI-X, a multilingual vision and language model, both in terms of size of the components and the breadth of its training task mixture. Our model achieves new levels of performance on a wide-range of varied and complex tasks, including multiple image-based captioning and question-answering tasks, image-based document understanding and few-shot (in-context) learning, as well as object detection, video question answering, and video captioning. PaLI-X advances the state-of-the-art on most vision-and-language benchmarks considered (25+ of them). Finally, we observe emerging capabilities, such as complex counting and multilingual object detection, tasks that are not explicitly in the training mix.
Three Towers: Flexible Contrastive Learning with Pretrained Image Models
May 29, 2023



We introduce Three Towers (3T), a flexible method to improve the contrastive learning of vision-language models by incorporating pretrained image classifiers. While contrastive models are usually trained from scratch, LiT (Zhai et al., 2022) has recently shown performance gains from using pretrained classifier embeddings. However, LiT directly replaces the image tower with the frozen embeddings, excluding any potential benefits of contrastively training the image tower. With 3T, we propose a more flexible strategy that allows the image tower to benefit from both pretrained embeddings and contrastive training. To achieve this, we introduce a third tower that contains the frozen pretrained embeddings, and we encourage alignment between this third tower and the main image-text towers. Empirically, 3T consistently improves over LiT and the CLIP-style from-scratch baseline for retrieval tasks. For classification, 3T reliably improves over the from-scratch baseline, and while it underperforms relative to LiT for JFT-pretrained models, it outperforms LiT for ImageNet-21k and Places365 pretraining.