 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSketch-to-Layout: Sketch-Guided Multimodal Layout Generation
Oct 31, 2025Graphic layout generation is a growing research area focusing on generating aesthetically pleasing layouts ranging from poster designs to documents. While recent research has explored ways to incorporate user constraints to guide the layout generation, these constraints often require complex specifications which reduce usability. We introduce an innovative approach exploiting user-provided sketches as intuitive constraints and we demonstrate empirically the effectiveness of this new guidance method, establishing the sketch-to-layout problem as a promising research direction, which is currently under-explored. To tackle the sketch-to-layout problem, we propose a multimodal transformer-based solution using the sketch and the content assets as inputs to produce high quality layouts. Since collecting sketch training data from human annotators to train our model is very costly, we introduce a novel and efficient method to synthetically generate training sketches at scale. We train and evaluate our model on three publicly available datasets: PubLayNet, DocLayNet and SlidesVQA, demonstrating that it outperforms state-of-the-art constraint-based methods, while offering a more intuitive design experience. In order to facilitate future sketch-to-layout research, we release O(200k) synthetically-generated sketches for the public datasets above. The datasets are available at https://github.com/google-deepmind/sketch_to_layout.
Representing Online Handwriting for Recognition in Large Vision-Language Models
Feb 23, 2024



The adoption of tablets with touchscreens and styluses is increasing, and a key feature is converting handwriting to text, enabling search, indexing, and AI assistance. Meanwhile, vision-language models (VLMs) are now the go-to solution for image understanding, thanks to both their state-of-the-art performance across a variety of tasks and the simplicity of a unified approach to training, fine-tuning, and inference. While VLMs obtain high performance on image-based tasks, they perform poorly on handwriting recognition when applied naively, i.e., by rendering handwriting as an image and performing optical character recognition (OCR). In this paper, we study online handwriting recognition with VLMs, going beyond naive OCR. We propose a novel tokenized representation of digital ink (online handwriting) that includes both a time-ordered sequence of strokes as text, and as image. We show that this representation yields results comparable to or better than state-of-the-art online handwriting recognizers. Wide applicability is shown through results with two different VLM families, on multiple public datasets. Our approach can be applied to off-the-shelf VLMs, does not require any changes in their architecture, and can be used in both fine-tuning and parameter-efficient tuning. We perform a detailed ablation study to identify the key elements of the proposed representation.
InkSight: Offline-to-Online Handwriting Conversion by Learning to Read and Write
Feb 21, 2024



Digital note-taking is gaining popularity, offering a durable, editable, and easily indexable way of storing notes in the vectorized form, known as digital ink. However, a substantial gap remains between this way of note-taking and traditional pen-and-paper note-taking, a practice still favored by a vast majority. Our work, InkSight, aims to bridge the gap by empowering physical note-takers to effortlessly convert their work (offline handwriting) to digital ink (online handwriting), a process we refer to as Derendering. Prior research on the topic has focused on the geometric properties of images, resulting in limited generalization beyond their training domains. Our approach combines reading and writing priors, allowing training a model in the absence of large amounts of paired samples, which are difficult to obtain. To our knowledge, this is the first work that effectively derenders handwritten text in arbitrary photos with diverse visual characteristics and backgrounds. Furthermore, it generalizes beyond its training domain into simple sketches. Our human evaluation reveals that 87% of the samples produced by our model on the challenging HierText dataset are considered as a valid tracing of the input image and 67% look like a pen trajectory traced by a human. Interactive visualizations of 100 word-level model outputs for each of the three public datasets are available in our Hugging Face space: https://huggingface.co/spaces/Derendering/Model-Output-Playground. Model release is in progress.
Three Towers: Flexible Contrastive Learning with Pretrained Image Models
May 29, 2023



We introduce Three Towers (3T), a flexible method to improve the contrastive learning of vision-language models by incorporating pretrained image classifiers. While contrastive models are usually trained from scratch, LiT (Zhai et al., 2022) has recently shown performance gains from using pretrained classifier embeddings. However, LiT directly replaces the image tower with the frozen embeddings, excluding any potential benefits of contrastively training the image tower. With 3T, we propose a more flexible strategy that allows the image tower to benefit from both pretrained embeddings and contrastive training. To achieve this, we introduce a third tower that contains the frozen pretrained embeddings, and we encourage alignment between this third tower and the main image-text towers. Empirically, 3T consistently improves over LiT and the CLIP-style from-scratch baseline for retrieval tasks. For classification, 3T reliably improves over the from-scratch baseline, and while it underperforms relative to LiT for JFT-pretrained models, it outperforms LiT for ImageNet-21k and Places365 pretraining.
When does Privileged Information Explain Away Label Noise?
Mar 03, 2023
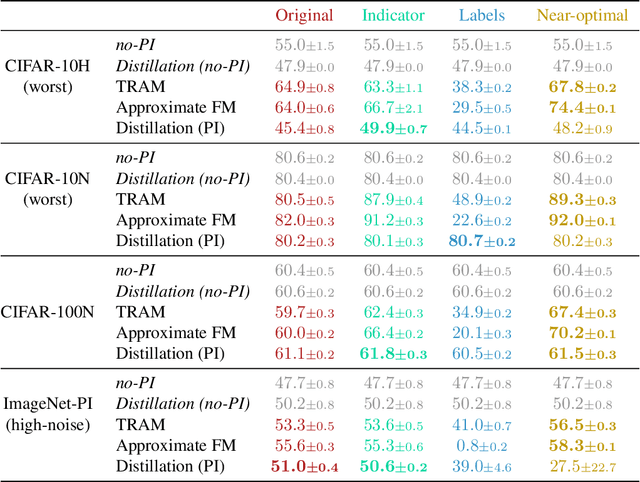
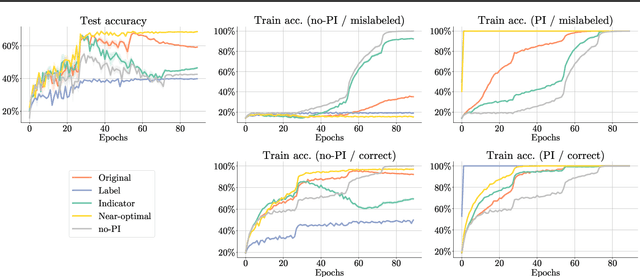

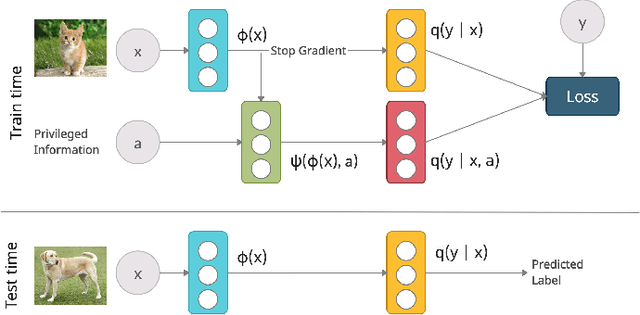
Leveraging privileged information (PI), or features available during training but not at test time, has recently been shown to be an effective method for addressing label noise. However, the reasons for its effectiveness are not well understood. In this study, we investigate the role played by different properties of the PI in explaining away label noise. Through experiments on multiple datasets with real PI (CIFAR-N/H) and a new large-scale benchmark ImageNet-PI, we find that PI is most helpful when it allows networks to easily distinguish clean from noisy data, while enabling a learning shortcut to memorize the noisy examples. Interestingly, when PI becomes too predictive of the target label, PI methods often perform worse than their no-PI baselines. Based on these findings, we propose several enhancements to the state-of-the-art PI methods and demonstrate the potential of PI as a means of tackling label noise. Finally, we show how we can easily combine the resulting PI approaches with existing no-PI techniques designed to deal with label noise.
Massively Scaling Heteroscedastic Classifiers
Jan 30, 2023


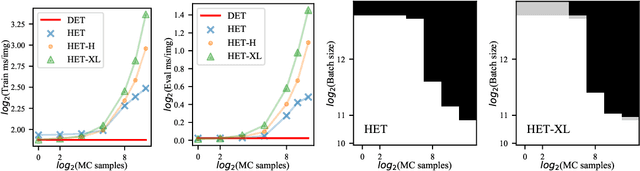
Heteroscedastic classifiers, which learn a multivariate Gaussian distribution over prediction logits, have been shown to perform well on image classification problems with hundreds to thousands of classes. However, compared to standard classifiers, they introduce extra parameters that scale linearly with the number of classes. This makes them infeasible to apply to larger-scale problems. In addition heteroscedastic classifiers introduce a critical temperature hyperparameter which must be tuned. We propose HET-XL, a heteroscedastic classifier whose parameter count when compared to a standard classifier scales independently of the number of classes. In our large-scale settings, we show that we can remove the need to tune the temperature hyperparameter, by directly learning it on the training data. On large image classification datasets with up to 4B images and 30k classes our method requires 14X fewer additional parameters, does not require tuning the temperature on a held-out set and performs consistently better than the baseline heteroscedastic classifier. HET-XL improves ImageNet 0-shot classification in a multimodal contrastive learning setup which can be viewed as a 3.5 billion class classification problem.
Inkorrect: Online Handwriting Spelling Correction
Feb 28, 2022
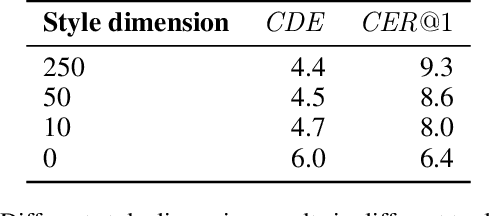
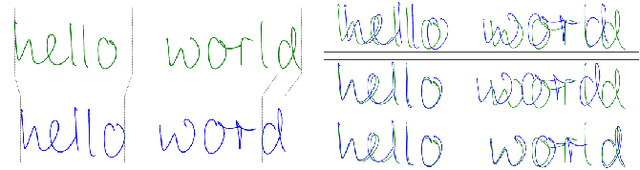

We introduce Inkorrect, a data- and label-efficient approach for online handwriting (Digital Ink) spelling correction - DISC. Unlike previous work, the proposed method does not require multiple samples from the same writer, or access to character level segmentation. We show that existing automatic evaluation metrics do not fully capture and are not correlated with the human perception of the quality of the spelling correction, and propose new ones that correlate with human perception. We additionally surface an interesting phenomenon: a trade-off between the similarity and recognizability of the spell-corrected inks. We further create a family of models corresponding to different points on the Pareto frontier between those two axes. We show that Inkorrect's Pareto frontier dominates the points that correspond to prior work.
Transfer and Marginalize: Explaining Away Label Noise with Privileged Information
Feb 18, 2022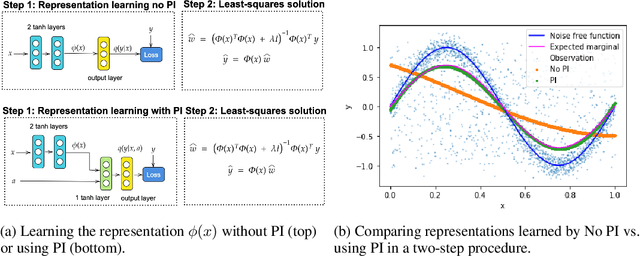
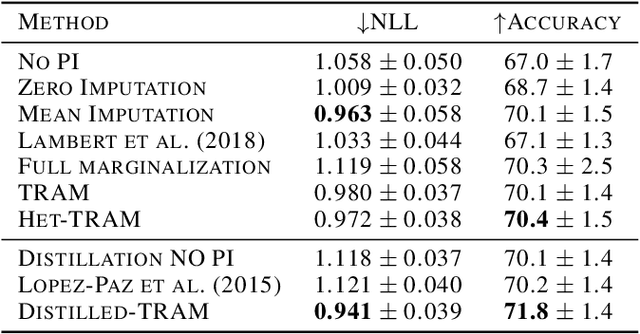
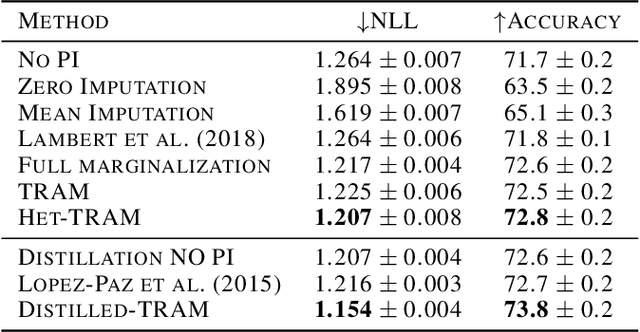
Supervised learning datasets often have privileged information, in the form of features which are available at training time but are not available at test time e.g. the ID of the annotator that provided the label. We argue that privileged information is useful for explaining away label noise, thereby reducing the harmful impact of noisy labels. We develop a simple and efficient method for supervised neural networks: it transfers via weight sharing the knowledge learned with privileged information and approximately marginalizes over privileged information at test time. Our method, TRAM (TRansfer and Marginalize), has minimal training time overhead and has the same test time cost as not using privileged information. TRAM performs strongly on CIFAR-10H, ImageNet and Civil Comments benchmarks.
Deep Classifiers with Label Noise Modeling and Distance Awareness
Oct 06, 2021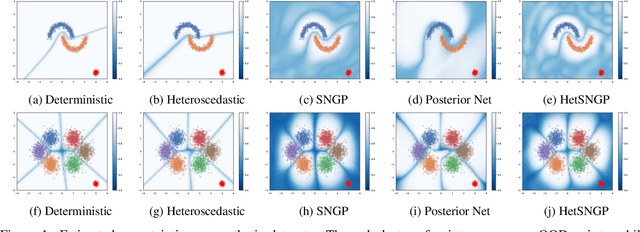



Uncertainty estimation in deep learning has recently emerged as a crucial area of interest to advance reliability and robustness in safety-critical applications. While there have been many proposed methods that either focus on distance-aware model uncertainties for out-of-distribution detection or on input-dependent label uncertainties for in-distribution calibration, both of these types of uncertainty are often necessary. In this work, we propose the HetSNGP method for jointly modeling the model and data uncertainty. We show that our proposed model affords a favorable combination between these two complementary types of uncertainty and thus outperforms the baseline methods on some challenging out-of-distribution datasets, including CIFAR-100C, Imagenet-C, and Imagenet-A. Moreover, we propose HetSNGP Ensemble, an ensembled version of our method which adds an additional type of uncertainty and also outperforms other ensemble baselines.
Correlated Input-Dependent Label Noise in Large-Scale Image Classification
May 19, 2021



Large scale image classification datasets often contain noisy labels. We take a principled probabilistic approach to modelling input-dependent, also known as heteroscedastic, label noise in these datasets. We place a multivariate Normal distributed latent variable on the final hidden layer of a neural network classifier. The covariance matrix of this latent variable, models the aleatoric uncertainty due to label noise. We demonstrate that the learned covariance structure captures known sources of label noise between semantically similar and co-occurring classes. Compared to standard neural network training and other baselines, we show significantly improved accuracy on Imagenet ILSVRC 2012 79.3% (+2.6%), Imagenet-21k 47.0% (+1.1%) and JFT 64.7% (+1.6%). We set a new state-of-the-art result on WebVision 1.0 with 76.6% top-1 accuracy. These datasets range from over 1M to over 300M training examples and from 1k classes to more than 21k classes. Our method is simple to use, and we provide an implementation that is a drop-in replacement for the final fully-connected layer in a deep classifier.