 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Embodied AI with MuscleMimic: Unlocking full-body musculoskeletal motor learning at scale
Mar 26, 2026Learning motor control for muscle-driven musculoskeletal models is hindered by the computational cost of biomechanically accurate simulation and the scarcity of validated, open full-body models. Here we present MuscleMimic, an open-source framework for scalable motion imitation learning with physiologically realistic, muscle-actuated humanoids. MuscleMimic provides two validated musculoskeletal embodiments - a fixed-root upper-body model (126 muscles) for bimanual manipulation and a full-body model (416 muscles) for locomotion - together with a retargeting pipeline that maps SMPL-format motion capture data onto musculoskeletal structures while preserving kinematic and dynamic consistency. Leveraging massively parallel GPU simulation, the framework achieves order-of-magnitude training speedups over prior CPU-based approaches while maintaining comprehensive collision handling, enabling a single generalist policy to be trained on hundreds of diverse motions within days. The resulting policy faithfully reproduces a broad repertoire of human movements under full muscular control and can be fine-tuned to novel motions within hours. Biomechanical validation against experimental walking and running data demonstrates strong agreement in joint kinematics (mean correlation r = 0.90), while muscle activation analysis reveals both the promise and fundamental challenges of achieving physiological fidelity through kinematic imitation alone. By lowering the computational and data barriers to musculoskeletal simulation, MuscleMimic enables systematic model validation across diverse dynamic movements and broader participation in neuromuscular control research. Code, models, checkpoints, and retargeted datasets are available at: https://github.com/amathislab/musclemimic
Arnold: a generalist muscle transformer policy
Aug 25, 2025

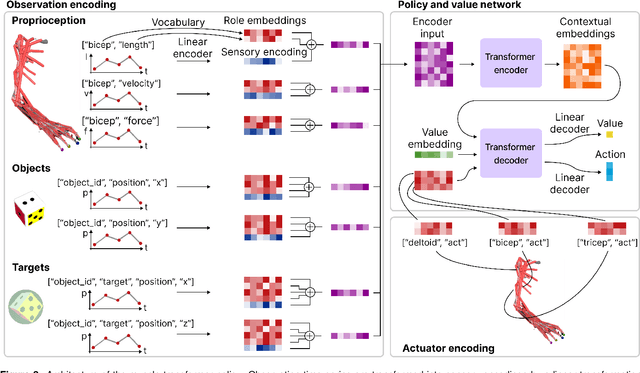

Controlling high-dimensional and nonlinear musculoskeletal models of the human body is a foundational scientific challenge. Recent machine learning breakthroughs have heralded policies that master individual skills like reaching, object manipulation and locomotion in musculoskeletal systems with many degrees of freedom. However, these agents are merely "specialists", achieving high performance for a single skill. In this work, we develop Arnold, a generalist policy that masters multiple tasks and embodiments. Arnold combines behavior cloning and fine-tuning with PPO to achieve expert or super-expert performance in 14 challenging control tasks from dexterous object manipulation to locomotion. A key innovation is Arnold's sensorimotor vocabulary, a compositional representation of the semantics of heterogeneous sensory modalities, objectives, and actuators. Arnold leverages this vocabulary via a transformer architecture to deal with the variable observation and action spaces of each task. This framework supports efficient multi-task, multi-embodiment learning and facilitates rapid adaptation to novel tasks. Finally, we analyze Arnold to provide insights into biological motor control, corroborating recent findings on the limited transferability of muscle synergies across tasks.
ClipGS: Clippable Gaussian Splatting for Interactive Cinematic Visualization of Volumetric Medical Data
Jul 09, 2025The visualization of volumetric medical data is crucial for enhancing diagnostic accuracy and improving surgical planning and education. Cinematic rendering techniques significantly enrich this process by providing high-quality visualizations that convey intricate anatomical details, thereby facilitating better understanding and decision-making in medical contexts. However, the high computing cost and low rendering speed limit the requirement of interactive visualization in practical applications. In this paper, we introduce ClipGS, an innovative Gaussian splatting framework with the clipping plane supported, for interactive cinematic visualization of volumetric medical data. To address the challenges posed by dynamic interactions, we propose a learnable truncation scheme that automatically adjusts the visibility of Gaussian primitives in response to the clipping plane. Besides, we also design an adaptive adjustment model to dynamically adjust the deformation of Gaussians and refine the rendering performance. We validate our method on five volumetric medical data (including CT and anatomical slice data), and reach an average 36.635 PSNR rendering quality with 156 FPS and 16.1 MB model size, outperforming state-of-the-art methods in rendering quality and efficiency.
Normalizing Flow Regression for Bayesian Inference with Offline Likelihood Evaluations
Apr 15, 2025Bayesian inference with computationally expensive likelihood evaluations remains a significant challenge in many scientific domains. We propose normalizing flow regression (NFR), a novel offline inference method for approximating posterior distributions. Unlike traditional surrogate approaches that require additional sampling or inference steps, NFR directly yields a tractable posterior approximation through regression on existing log-density evaluations. We introduce training techniques specifically for flow regression, such as tailored priors and likelihood functions, to achieve robust posterior and model evidence estimation. We demonstrate NFR's effectiveness on synthetic benchmarks and real-world applications from neuroscience and biology, showing superior or comparable performance to existing methods. NFR represents a promising approach for Bayesian inference when standard methods are computationally prohibitive or existing model evaluations can be recycled.
Stacking Variational Bayesian Monte Carlo
Apr 08, 2025Variational Bayesian Monte Carlo (VBMC) is a sample-efficient method for approximate Bayesian inference with computationally expensive likelihoods. While VBMC's local surrogate approach provides stable approximations, its conservative exploration strategy and limited evaluation budget can cause it to miss regions of complex posteriors. In this work, we introduce Stacking Variational Bayesian Monte Carlo (S-VBMC), a method that constructs global posterior approximations by merging independent VBMC runs through a principled and inexpensive post-processing step. Our approach leverages VBMC's mixture posterior representation and per-component evidence estimates, requiring no additional likelihood evaluations while being naturally parallelizable. We demonstrate S-VBMC's effectiveness on two synthetic problems designed to challenge VBMC's exploration capabilities and two real-world applications from computational neuroscience, showing substantial improvements in posterior approximation quality across all cases.
Amortized Bayesian Workflow (Extended Abstract)
Sep 06, 2024



Bayesian inference often faces a trade-off between computational speed and sampling accuracy. We propose an adaptive workflow that integrates rapid amortized inference with gold-standard MCMC techniques to achieve both speed and accuracy when performing inference on many observed datasets. Our approach uses principled diagnostics to guide the choice of inference method for each dataset, moving along the Pareto front from fast amortized sampling to slower but guaranteed-accurate MCMC when necessary. By reusing computations across steps, our workflow creates synergies between amortized and MCMC-based inference. We demonstrate the effectiveness of this integrated approach on a generalized extreme value task with 1000 observed data sets, showing 90x time efficiency gains while maintaining high posterior quality.
InkSight: Offline-to-Online Handwriting Conversion by Learning to Read and Write
Feb 21, 2024



Digital note-taking is gaining popularity, offering a durable, editable, and easily indexable way of storing notes in the vectorized form, known as digital ink. However, a substantial gap remains between this way of note-taking and traditional pen-and-paper note-taking, a practice still favored by a vast majority. Our work, InkSight, aims to bridge the gap by empowering physical note-takers to effortlessly convert their work (offline handwriting) to digital ink (online handwriting), a process we refer to as Derendering. Prior research on the topic has focused on the geometric properties of images, resulting in limited generalization beyond their training domains. Our approach combines reading and writing priors, allowing training a model in the absence of large amounts of paired samples, which are difficult to obtain. To our knowledge, this is the first work that effectively derenders handwritten text in arbitrary photos with diverse visual characteristics and backgrounds. Furthermore, it generalizes beyond its training domain into simple sketches. Our human evaluation reveals that 87% of the samples produced by our model on the challenging HierText dataset are considered as a valid tracing of the input image and 67% look like a pen trajectory traced by a human. Interactive visualizations of 100 word-level model outputs for each of the three public datasets are available in our Hugging Face space: https://huggingface.co/spaces/Derendering/Model-Output-Playground. Model release is in progress.
PyVBMC: Efficient Bayesian inference in Python
Mar 16, 2023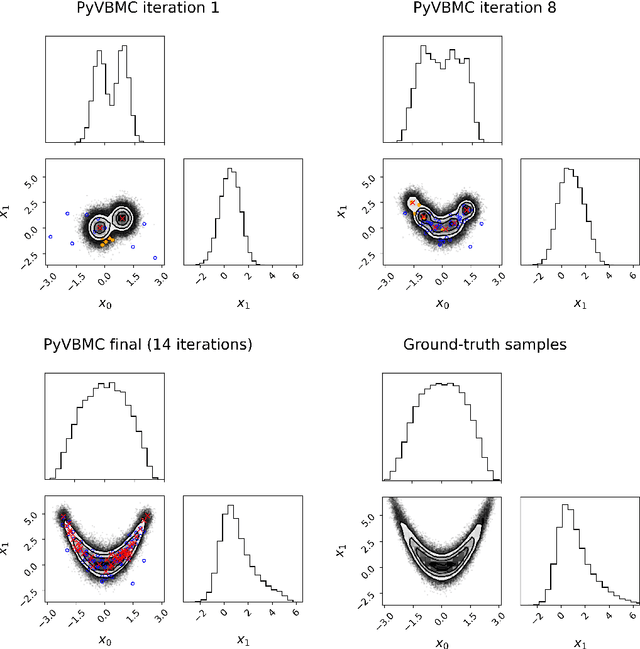
PyVBMC is a Python implementation of the Variational Bayesian Monte Carlo (VBMC) algorithm for posterior and model inference for black-box computational models (Acerbi, 2018, 2020). VBMC is an approximate inference method designed for efficient parameter estimation and model assessment when model evaluations are mildly-to-very expensive (e.g., a second or more) and/or noisy. Specifically, VBMC computes: - a flexible (non-Gaussian) approximate posterior distribution of the model parameters, from which statistics and posterior samples can be easily extracted; - an approximation of the model evidence or marginal likelihood, a metric used for Bayesian model selection. PyVBMC can be applied to any computational or statistical model with up to roughly 10-15 continuous parameters, with the only requirement that the user can provide a Python function that computes the target log likelihood of the model, or an approximation thereof (e.g., an estimate of the likelihood obtained via simulation or Monte Carlo methods). PyVBMC is particularly effective when the model takes more than about a second per evaluation, with dramatic speed-ups of 1-2 orders of magnitude when compared to traditional approximate inference methods. Extensive benchmarks on both artificial test problems and a large number of real models from the computational sciences, particularly computational and cognitive neuroscience, show that VBMC generally - and often vastly - outperforms alternative methods for sample-efficient Bayesian inference, and is applicable to both exact and simulator-based models (Acerbi, 2018, 2019, 2020). PyVBMC brings this state-of-the-art inference algorithm to Python, along with an easy-to-use Pythonic interface for running the algorithm and manipulating and visualizing its results.
Fast post-process Bayesian inference with Sparse Variational Bayesian Monte Carlo
Mar 09, 2023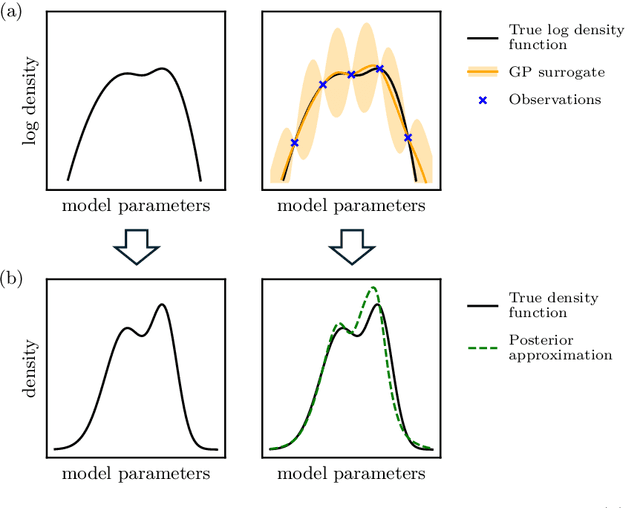
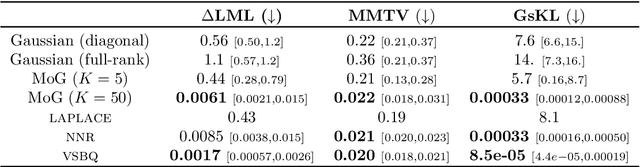
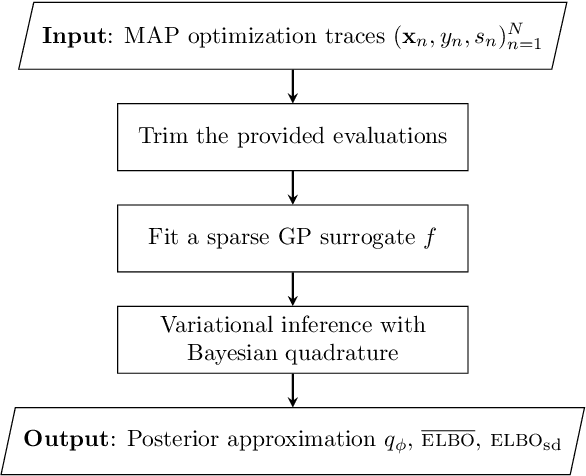
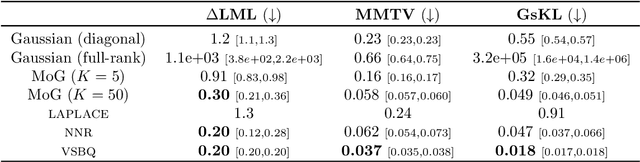
We introduce Sparse Variational Bayesian Monte Carlo (SVBMC), a method for fast "post-process" Bayesian inference for models with black-box and potentially noisy likelihoods. SVBMC reuses all existing target density evaluations -- for example, from previous optimizations or partial Markov Chain Monte Carlo runs -- to build a sparse Gaussian process (GP) surrogate model of the log posterior density. Uncertain regions of the surrogate are then refined via active learning as needed. Our work builds on the Variational Bayesian Monte Carlo (VBMC) framework for sample-efficient inference, with several novel contributions. First, we make VBMC scalable to a large number of pre-existing evaluations via sparse GP regression, deriving novel Bayesian quadrature formulae and acquisition functions for active learning with sparse GPs. Second, we introduce noise shaping, a general technique to induce the sparse GP approximation to focus on high posterior density regions. Third, we prove theoretical results in support of the SVBMC refinement procedure. We validate our method on a variety of challenging synthetic scenarios and real-world applications. We find that SVBMC consistently builds good posterior approximations by post-processing of existing model evaluations from different sources, often requiring only a small number of additional density evaluations.
Model Generalization: A Sharpness Aware Optimization Perspective
Aug 14, 2022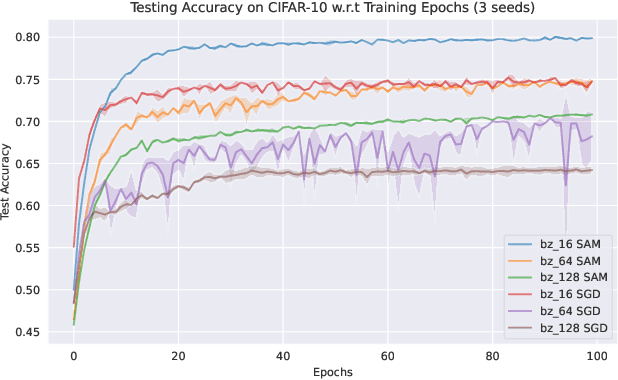
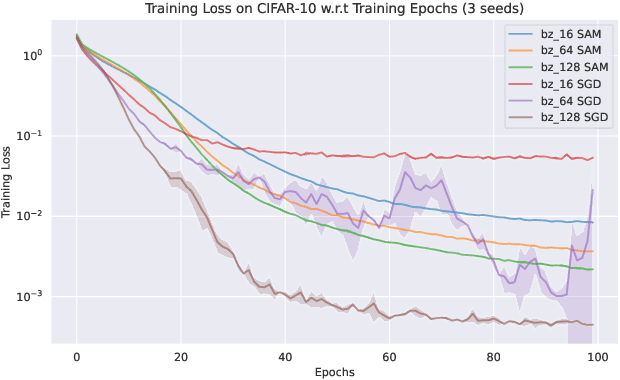
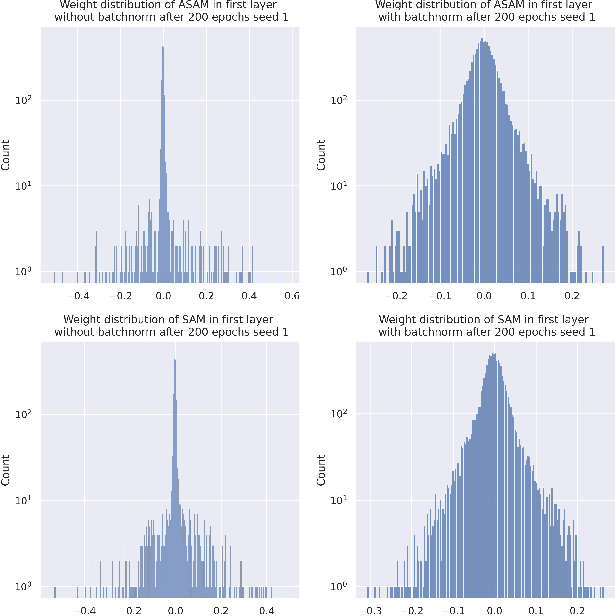
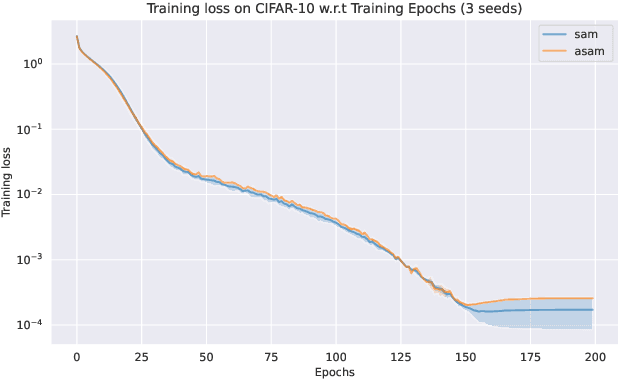
Sharpness-Aware Minimization (SAM) and adaptive sharpness-aware minimization (ASAM) aim to improve the model generalization. And in this project, we proposed three experiments to valid their generalization from the sharpness aware perspective. And our experiments show that sharpness aware-based optimization techniques could help to provide models with strong generalization ability. Our experiments also show that ASAM could improve the generalization performance on un-normalized data, but further research is needed to confirm this.