 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperparameters in Score-Based Membership Inference Attacks
Feb 10, 2025



Membership Inference Attacks (MIAs) have emerged as a valuable framework for evaluating privacy leakage by machine learning models. Score-based MIAs are distinguished, in particular, by their ability to exploit the confidence scores that the model generates for particular inputs. Existing score-based MIAs implicitly assume that the adversary has access to the target model's hyperparameters, which can be used to train the shadow models for the attack. In this work, we demonstrate that the knowledge of target hyperparameters is not a prerequisite for MIA in the transfer learning setting. Based on this, we propose a novel approach to select the hyperparameters for training the shadow models for MIA when the attacker has no prior knowledge about them by matching the output distributions of target and shadow models. We demonstrate that using the new approach yields hyperparameters that lead to an attack near indistinguishable in performance from an attack that uses target hyperparameters to train the shadow models. Furthermore, we study the empirical privacy risk of unaccounted use of training data for hyperparameter optimization (HPO) in differentially private (DP) transfer learning. We find no statistically significant evidence that performing HPO using training data would increase vulnerability to MIA.
NeurIPS 2023 Competition: Privacy Preserving Federated Learning Document VQA
Nov 06, 2024



The Privacy Preserving Federated Learning Document VQA (PFL-DocVQA) competition challenged the community to develop provably private and communication-efficient solutions in a federated setting for a real-life use case: invoice processing. The competition introduced a dataset of real invoice documents, along with associated questions and answers requiring information extraction and reasoning over the document images. Thereby, it brings together researchers and expertise from the document analysis, privacy, and federated learning communities. Participants fine-tuned a pre-trained, state-of-the-art Document Visual Question Answering model provided by the organizers for this new domain, mimicking a typical federated invoice processing setup. The base model is a multi-modal generative language model, and sensitive information could be exposed through either the visual or textual input modality. Participants proposed elegant solutions to reduce communication costs while maintaining a minimum utility threshold in track 1 and to protect all information from each document provider using differential privacy in track 2. The competition served as a new testbed for developing and testing private federated learning methods, simultaneously raising awareness about privacy within the document image analysis and recognition community. Ultimately, the competition analysis provides best practices and recommendations for successfully running privacy-focused federated learning challenges in the future.
Towards Efficient and Scalable Training of Differentially Private Deep Learning
Jun 25, 2024



Differentially private stochastic gradient descent (DP-SGD) is the standard algorithm for training machine learning models under differential privacy (DP). The major drawback of DP-SGD is the drop in utility which prior work has comprehensively studied. However, in practice another major drawback that hinders the large-scale deployment is the significantly higher computational cost. We conduct a comprehensive empirical study to quantify the computational cost of training deep learning models under DP and benchmark methods that aim at reducing the cost. Among these are more efficient implementations of DP-SGD and training with lower precision. Finally, we study the scaling behaviour using up to 80 GPUs.
Noise-Aware Differentially Private Regression via Meta-Learning
Jun 12, 2024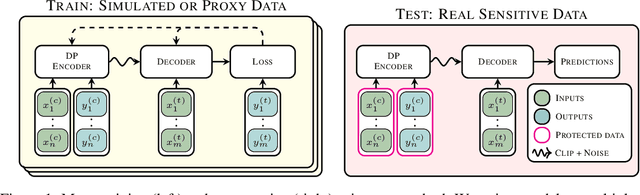
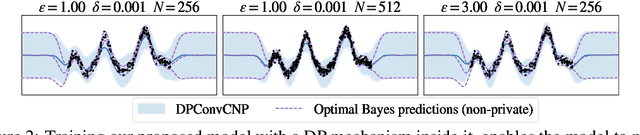

Many high-stakes applications require machine learning models that protect user privacy and provide well-calibrated, accurate predictions. While Differential Privacy (DP) is the gold standard for protecting user privacy, standard DP mechanisms typically significantly impair performance. One approach to mitigating this issue is pre-training models on simulated data before DP learning on the private data. In this work we go a step further, using simulated data to train a meta-learning model that combines the Convolutional Conditional Neural Process (ConvCNP) with an improved functional DP mechanism of Hall et al. [2013] yielding the DPConvCNP. DPConvCNP learns from simulated data how to map private data to a DP predictive model in one forward pass, and then provides accurate, well-calibrated predictions. We compare DPConvCNP with a DP Gaussian Process (GP) baseline with carefully tuned hyperparameters. The DPConvCNP outperforms the GP baseline, especially on non-Gaussian data, yet is much faster at test time and requires less tuning.
Understanding Practical Membership Privacy of Deep Learning
Feb 07, 2024



We apply a state-of-the-art membership inference attack (MIA) to systematically test the practical privacy vulnerability of fine-tuning large image classification models.We focus on understanding the properties of data sets and samples that make them vulnerable to membership inference. In terms of data set properties, we find a strong power law dependence between the number of examples per class in the data and the MIA vulnerability, as measured by true positive rate of the attack at a low false positive rate. For an individual sample, large gradients at the end of training are strongly correlated with MIA vulnerability.
Privacy-Aware Document Visual Question Answering
Dec 15, 2023

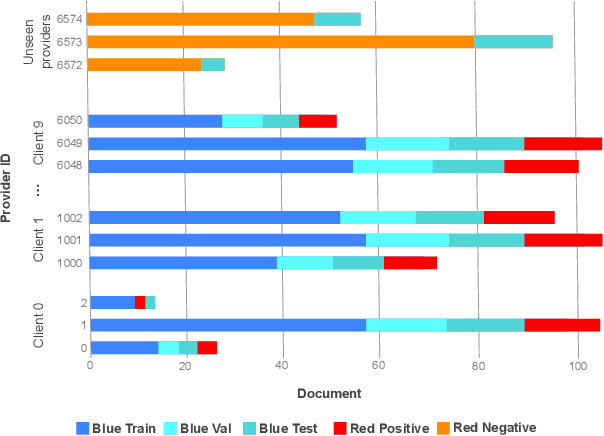

Document Visual Question Answering (DocVQA) is a fast growing branch of document understanding. Despite the fact that documents contain sensitive or copyrighted information, none of the current DocVQA methods offers strong privacy guarantees. In this work, we explore privacy in the domain of DocVQA for the first time. We highlight privacy issues in state of the art multi-modal LLM models used for DocVQA, and explore possible solutions. Specifically, we focus on the invoice processing use case as a realistic, widely used scenario for document understanding, and propose a large scale DocVQA dataset comprising invoice documents and associated questions and answers. We employ a federated learning scheme, that reflects the real-life distribution of documents in different businesses, and we explore the use case where the ID of the invoice issuer is the sensitive information to be protected. We demonstrate that non-private models tend to memorise, behaviour that can lead to exposing private information. We then evaluate baseline training schemes employing federated learning and differential privacy in this multi-modal scenario, where the sensitive information might be exposed through any of the two input modalities: vision (document image) or language (OCR tokens). Finally, we design an attack exploiting the memorisation effect of the model, and demonstrate its effectiveness in probing different DocVQA models.
PyVBMC: Efficient Bayesian inference in Python
Mar 16, 2023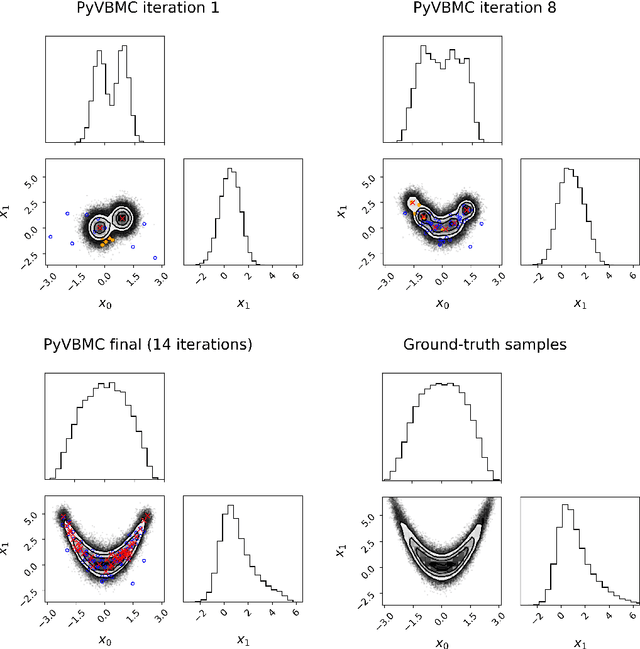
PyVBMC is a Python implementation of the Variational Bayesian Monte Carlo (VBMC) algorithm for posterior and model inference for black-box computational models (Acerbi, 2018, 2020). VBMC is an approximate inference method designed for efficient parameter estimation and model assessment when model evaluations are mildly-to-very expensive (e.g., a second or more) and/or noisy. Specifically, VBMC computes: - a flexible (non-Gaussian) approximate posterior distribution of the model parameters, from which statistics and posterior samples can be easily extracted; - an approximation of the model evidence or marginal likelihood, a metric used for Bayesian model selection. PyVBMC can be applied to any computational or statistical model with up to roughly 10-15 continuous parameters, with the only requirement that the user can provide a Python function that computes the target log likelihood of the model, or an approximation thereof (e.g., an estimate of the likelihood obtained via simulation or Monte Carlo methods). PyVBMC is particularly effective when the model takes more than about a second per evaluation, with dramatic speed-ups of 1-2 orders of magnitude when compared to traditional approximate inference methods. Extensive benchmarks on both artificial test problems and a large number of real models from the computational sciences, particularly computational and cognitive neuroscience, show that VBMC generally - and often vastly - outperforms alternative methods for sample-efficient Bayesian inference, and is applicable to both exact and simulator-based models (Acerbi, 2018, 2019, 2020). PyVBMC brings this state-of-the-art inference algorithm to Python, along with an easy-to-use Pythonic interface for running the algorithm and manipulating and visualizing its results.
On the Efficacy of Differentially Private Few-shot Image Classification
Feb 02, 2023There has been significant recent progress in training differentially private (DP) models which achieve accuracy that approaches the best non-private models. These DP models are typically pretrained on large public datasets and then fine-tuned on downstream datasets that are (i) relatively large, and (ii) similar in distribution to the pretraining data. However, in many applications including personalization, it is crucial to perform well in the few-shot setting, as obtaining large amounts of labeled data may be problematic; and on images from a wide variety of domains for use in various specialist settings. To understand under which conditions few-shot DP can be effective, we perform an exhaustive set of experiments that reveals how the accuracy and vulnerability to attack of few-shot DP image classification models are affected as the number of shots per class, privacy level, model architecture, dataset, and subset of learnable parameters in the model vary. We show that to achieve DP accuracy on par with non-private models, the shots per class must be increased as the privacy level increases by as much as 32$\times$ for CIFAR-100 at $\epsilon=1$. We also find that few-shot non-private models are highly susceptible to membership inference attacks. DP provides clear mitigation against the attacks, but a small $\epsilon$ is required to effectively prevent them. Finally, we evaluate DP federated learning systems and establish state-of-the-art performance on the challenging FLAIR federated learning benchmark.
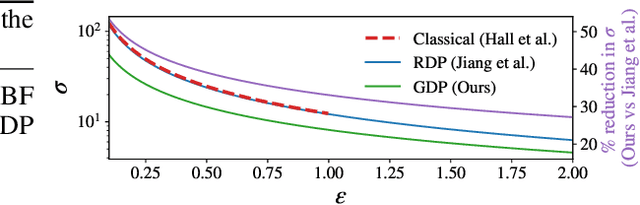
Individual Privacy Accounting with Gaussian Differential Privacy
Sep 30, 2022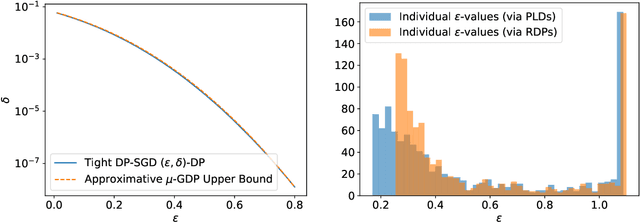
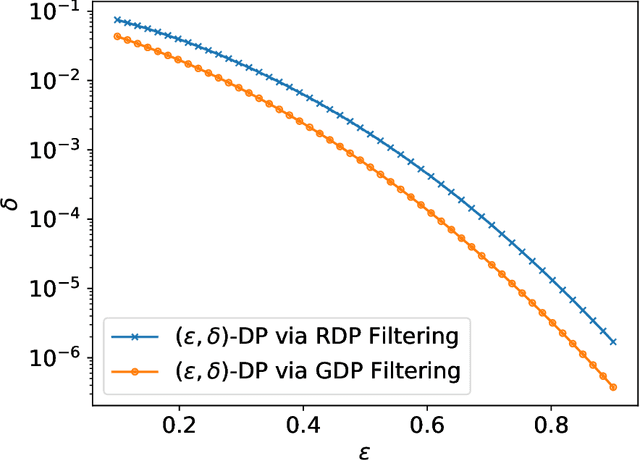
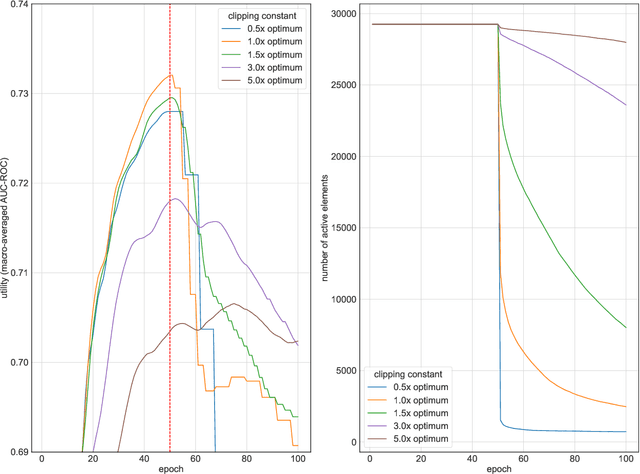
Individual privacy accounting enables bounding differential privacy (DP) loss individually for each participant involved in the analysis. This can be informative as often the individual privacy losses are considerably smaller than those indicated by the DP bounds that are based on considering worst-case bounds at each data access. In order to account for the individual privacy losses in a principled manner, we need a privacy accountant for adaptive compositions of randomised mechanisms, where the loss incurred at a given data access is allowed to be smaller than the worst-case loss. This kind of analysis has been carried out for the R\'enyi differential privacy (RDP) by Feldman and Zrnic (2021), however not yet for the so-called optimal privacy accountants. We make first steps in this direction by providing a careful analysis using the Gaussian differential privacy which gives optimal bounds for the Gaussian mechanism, one of the most versatile DP mechanisms. This approach is based on determining a certain supermartingale for the hockey-stick divergence and on extending the R\'enyi divergence-based fully adaptive composition results by Feldman and Zrnic (2021). We also consider measuring the individual $(\varepsilon,\delta)$-privacy losses using the so-called privacy loss distributions. With the help of the Blackwell theorem, we can then make use of the RDP analysis to construct an approximative individual $(\varepsilon,\delta)$-accountant.