 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: All Current Generative Fidelity and Diversity Metrics are Flawed
May 28, 2025Any method's development and practical application is limited by our ability to measure its reliability. The popularity of generative modeling emphasizes the importance of good synthetic data metrics. Unfortunately, previous works have found many failure cases in current metrics, for example lack of outlier robustness and unclear lower and upper bounds. We propose a list of desiderata for synthetic data metrics, and a suite of sanity checks: carefully chosen simple experiments that aim to detect specific and known generative modeling failure modes. Based on these desiderata and the results of our checks, we arrive at our position: all current generative fidelity and diversity metrics are flawed. This significantly hinders practical use of synthetic data. Our aim is to convince the research community to spend more effort in developing metrics, instead of models. Additionally, through analyzing how current metrics fail, we provide practitioners with guidelines on how these metrics should (not) be used.
Noise-Aware Differentially Private Regression via Meta-Learning
Jun 12, 2024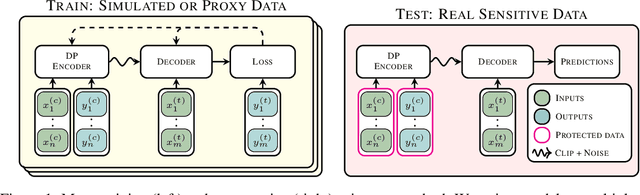
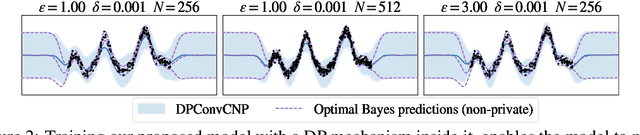

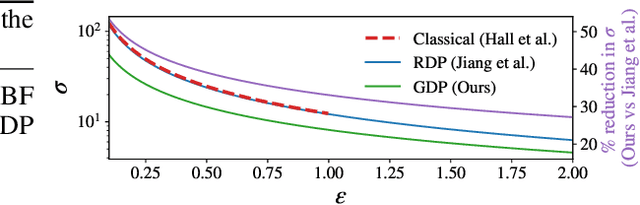
Many high-stakes applications require machine learning models that protect user privacy and provide well-calibrated, accurate predictions. While Differential Privacy (DP) is the gold standard for protecting user privacy, standard DP mechanisms typically significantly impair performance. One approach to mitigating this issue is pre-training models on simulated data before DP learning on the private data. In this work we go a step further, using simulated data to train a meta-learning model that combines the Convolutional Conditional Neural Process (ConvCNP) with an improved functional DP mechanism of Hall et al. [2013] yielding the DPConvCNP. DPConvCNP learns from simulated data how to map private data to a DP predictive model in one forward pass, and then provides accurate, well-calibrated predictions. We compare DPConvCNP with a DP Gaussian Process (GP) baseline with carefully tuned hyperparameters. The DPConvCNP outperforms the GP baseline, especially on non-Gaussian data, yet is much faster at test time and requires less tuning.
A Bias-Variance Decomposition for Ensembles over Multiple Synthetic Datasets
Feb 06, 2024



Recent studies have highlighted the benefits of generating multiple synthetic datasets for supervised learning, from increased accuracy to more effective model selection and uncertainty estimation. These benefits have clear empirical support, but the theoretical understanding of them is currently very light. We seek to increase the theoretical understanding by deriving bias-variance decompositions for several settings of using multiple synthetic datasets. Our theory predicts multiple synthetic datasets to be especially beneficial for high-variance downstream predictors, and yields a simple rule of thumb to select the appropriate number of synthetic datasets in the case of mean-squared error and Brier score. We investigate how our theory works in practice by evaluating the performance of an ensemble over many synthetic datasets for several real datasets and downstream predictors. The results follow our theory, showing that our insights are also practically relevant.
Subsampling is not Magic: Why Large Batch Sizes Work for Differentially Private Stochastic Optimisation
Feb 06, 2024

We study the effect of the batch size to the total gradient variance in differentially private stochastic gradient descent (DP-SGD), seeking a theoretical explanation for the usefulness of large batch sizes. As DP-SGD is the basis of modern DP deep learning, its properties have been widely studied, and recent works have empirically found large batch sizes to be beneficial. However, theoretical explanations of this benefit are currently heuristic at best. We first observe that the total gradient variance in DP-SGD can be decomposed into subsampling-induced and noise-induced variances. We then prove that in the limit of an infinite number of iterations, the effective noise-induced variance is invariant to the batch size. The remaining subsampling-induced variance decreases with larger batch sizes, so large batches reduce the effective total gradient variance. We confirm numerically that the asymptotic regime is relevant in practical settings when the batch size is not small, and find that outside the asymptotic regime, the total gradient variance decreases even more with large batch sizes. We also find a sufficient condition that implies that large batch sizes similarly reduce effective DP noise variance for one iteration of DP-SGD.
Noise-Aware Statistical Inference with Differentially Private Synthetic Data
May 28, 2022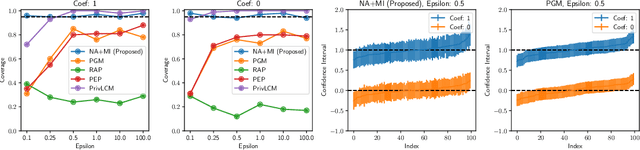
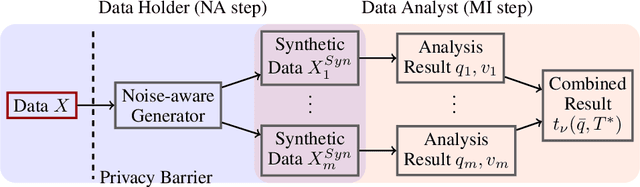
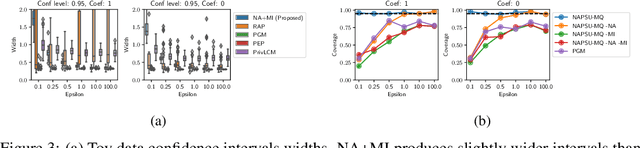
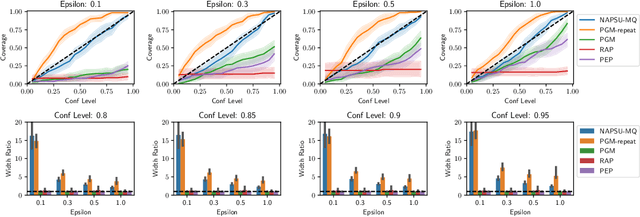
While generation of synthetic data under differential privacy (DP) has received a lot of attention in the data privacy community, analysis of synthetic data has received much less. Existing work has shown that simply analysing DP synthetic data as if it were real does not produce valid inferences of population-level quantities. For example, confidence intervals become too narrow, which we demonstrate with a simple experiment. We tackle this problem by combining synthetic data analysis techniques from the field of multiple imputation, and synthetic data generation using noise-aware Bayesian modeling into a pipeline NA+MI that allows computing accurate uncertainty estimates for population-level quantities from DP synthetic data. To implement NA+MI for discrete data generation from marginal queries, we develop a novel noise-aware synthetic data generation algorithm NAPSU-MQ using the principle of maximum entropy. Our experiments demonstrate that the pipeline is able to produce accurate confidence intervals from DP synthetic data. The intervals become wider with tighter privacy to accurately capture the additional uncertainty stemming from DP noise.