 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDissecting Quantization Error: A Concentration-Alignment Perspective
Mar 04, 2026Quantization can drastically increase the efficiency of large language and vision models, but typically incurs an accuracy drop. Recently, function-preserving transforms (e.g. rotations, Hadamard transform, channel-wise scaling) have been successfully applied to reduce post-training quantization error, yet a principled explanation remains elusive. We analyze linear-layer quantization via the signal-to-quantization-noise ratio (SQNR), showing that for uniform integer quantization at a fixed bit width, SQNR decomposes into (i) the concentration of weights and activations (capturing spread and outliers), and (ii) the alignment of their dominant variation directions. This reveals an actionable insight: beyond concentration - the focus of most prior transforms (e.g. rotations or Hadamard) - improving alignment between weight and activation can further reduce quantization error. Motivated by this, we introduce block Concentration-Alignment Transforms (CAT), a lightweight linear transformation that uses a covariance estimate from a small calibration set to jointly improve concentration and alignment, approximately maximizing SQNR. Experiments across several LLMs show that CAT consistently matches or outperforms prior transform-based quantization methods at 4-bit precision, confirming the insights gained in our framework.
STaMP: Sequence Transformation and Mixed Precision for Low-Precision Activation Quantization
Oct 30, 2025Quantization is the key method for reducing inference latency, power and memory footprint of generative AI models. However, accuracy often degrades sharply when activations are quantized below eight bits. Recent work suggests that invertible linear transformations (e.g. rotations) can aid quantization, by reparameterizing feature channels and weights. In this paper, we propose \textit{Sequence Transformation and Mixed Precision} (STaMP) quantization, a novel strategy that applies linear transformations along the \textit{sequence} dimension to exploit the strong local correlation in language and visual data. By keeping a small number of tokens in each intermediate activation at higher precision, we can maintain model accuracy at lower (average) activations bit-widths. We evaluate STaMP on recent LVM and LLM architectures, demonstrating that it significantly improves low bit width activation quantization and complements established activation and weight quantization methods including recent feature transformations.
HadaNorm: Diffusion Transformer Quantization through Mean-Centered Transformations
Jun 11, 2025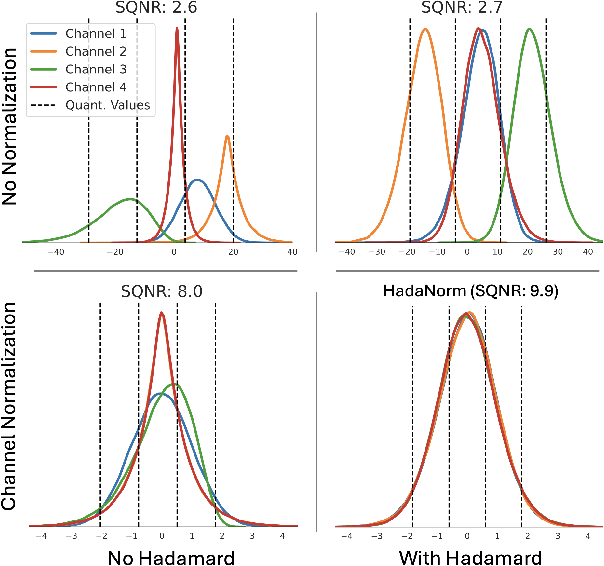
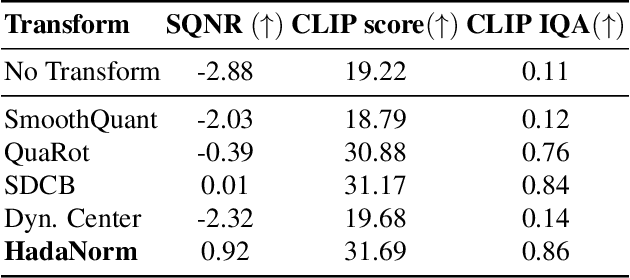
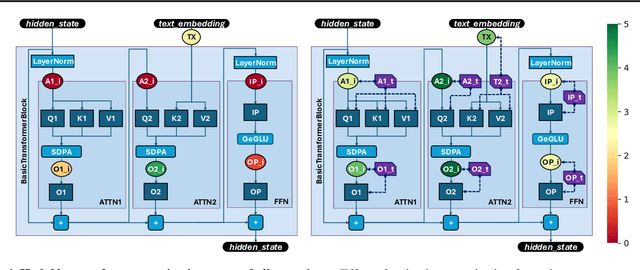
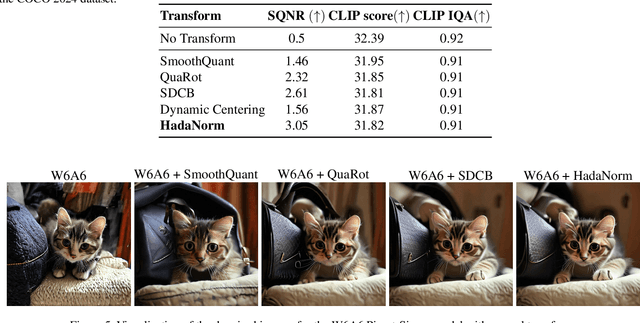
Diffusion models represent the cutting edge in image generation, but their high memory and computational demands hinder deployment on resource-constrained devices. Post-Training Quantization (PTQ) offers a promising solution by reducing the bitwidth of matrix operations. However, standard PTQ methods struggle with outliers, and achieving higher compression often requires transforming model weights and activations before quantization. In this work, we propose HadaNorm, a novel linear transformation that extends existing approaches and effectively mitigates outliers by normalizing activations feature channels before applying Hadamard transformations, enabling more aggressive activation quantization. We demonstrate that HadaNorm consistently reduces quantization error across the various components of transformer blocks, achieving superior efficiency-performance trade-offs when compared to state-of-the-art methods.
FPTQuant: Function-Preserving Transforms for LLM Quantization
Jun 05, 2025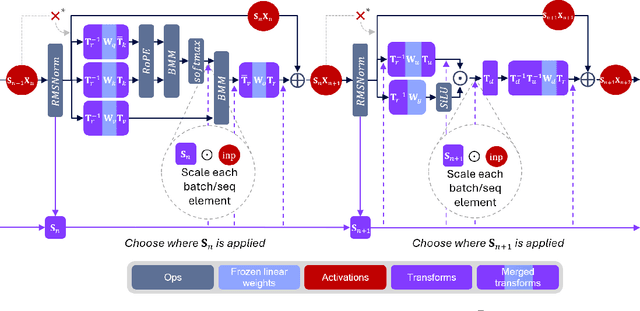
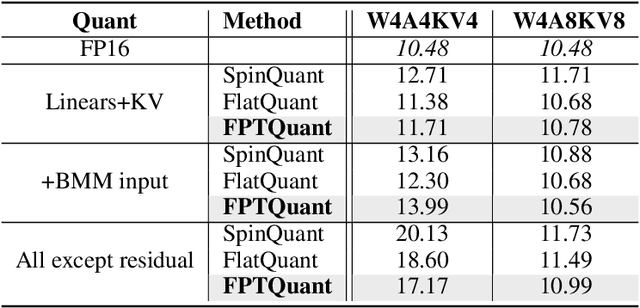
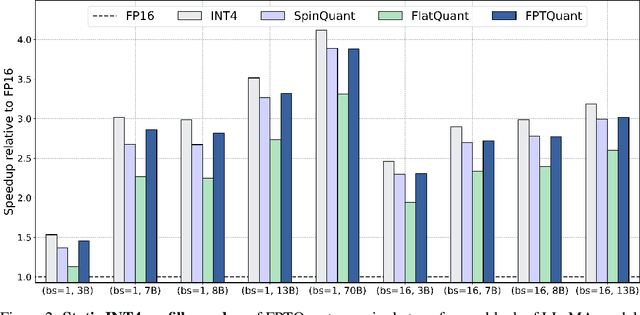
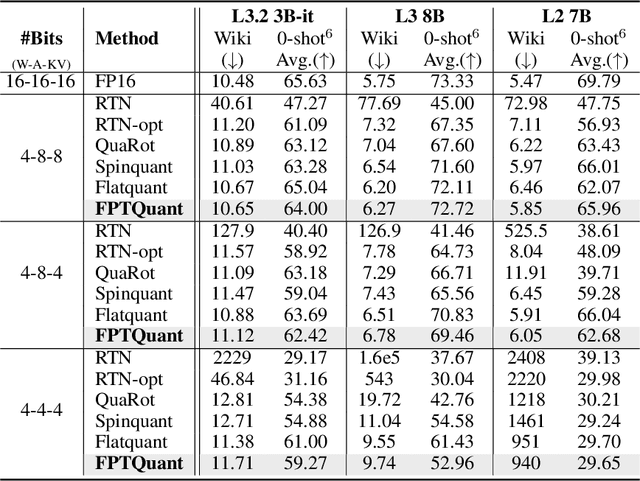
Large language models (LLMs) require substantial compute, and thus energy, at inference time. While quantizing weights and activations is effective at improving efficiency, naive quantization of LLMs can significantly degrade performance due to large magnitude outliers. This paper describes FPTQuant, which introduces four novel, lightweight, and expressive function-preserving transforms (FPTs) to facilitate quantization of transformers: (1) a mergeable pre-RoPE transform for queries and keys, (2) a mergeable transform for values, (3) a mergeable scaling transform within the MLP block, and (4) a cheap, dynamic scaling transform. By leveraging the equivariances and independencies inherent to canonical transformer operation, we designed these FPTs to maintain the model's function while shaping the intermediate activation distributions to be more quantization friendly. FPTQuant requires no custom kernels and adds virtually no overhead during inference. The FPTs are trained both locally to reduce outliers, and end-to-end such that the outputs of the quantized and full-precision models match. FPTQuant enables static INT4 quantization with minimal overhead and shows SOTA speed-up of up to 3.9 times over FP. Empirically, FPTQuant has an excellent accuracy-speed trade-off -- it is performing on par or exceeding most prior work and only shows slightly lower accuracy compared to a method that is up to 29% slower.
Position: All Current Generative Fidelity and Diversity Metrics are Flawed
May 28, 2025Any method's development and practical application is limited by our ability to measure its reliability. The popularity of generative modeling emphasizes the importance of good synthetic data metrics. Unfortunately, previous works have found many failure cases in current metrics, for example lack of outlier robustness and unclear lower and upper bounds. We propose a list of desiderata for synthetic data metrics, and a suite of sanity checks: carefully chosen simple experiments that aim to detect specific and known generative modeling failure modes. Based on these desiderata and the results of our checks, we arrive at our position: all current generative fidelity and diversity metrics are flawed. This significantly hinders practical use of synthetic data. Our aim is to convince the research community to spend more effort in developing metrics, instead of models. Additionally, through analyzing how current metrics fail, we provide practitioners with guidelines on how these metrics should (not) be used.
LaTable: Towards Large Tabular Models
Jun 25, 2024



Tabular data is one of the most ubiquitous modalities, yet the literature on tabular generative foundation models is lagging far behind its text and vision counterparts. Creating such a model is hard, due to the heterogeneous feature spaces of different tabular datasets, tabular metadata (e.g. dataset description and feature headers), and tables lacking prior knowledge (e.g. feature order). In this work we propose LaTable: a novel tabular diffusion model that addresses these challenges and can be trained across different datasets. Through extensive experiments we find that LaTable outperforms baselines on in-distribution generation, and that finetuning LaTable can generate out-of-distribution datasets better with fewer samples. On the other hand, we explore the poor zero-shot performance of LaTable, and what it may teach us about building generative tabular foundation models with better zero- and few-shot generation capabilities.
Why Tabular Foundation Models Should Be a Research Priority
May 02, 2024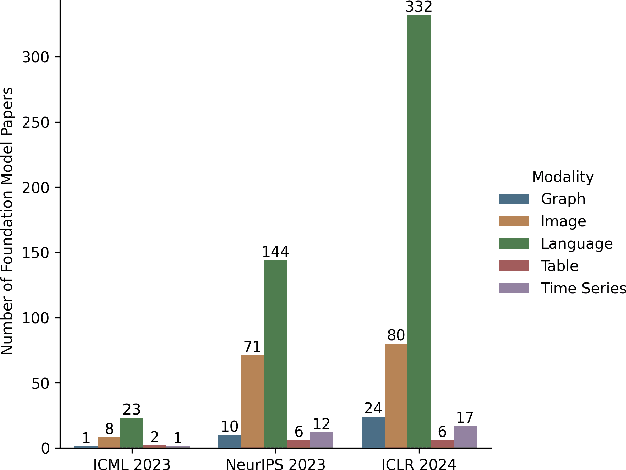

Recent text and image foundation models are incredibly impressive, and these models are attracting an ever-increasing portion of research resources. In this position piece we aim to shift the ML research community's priorities ever so slightly to a different modality: tabular data. Tabular data is the dominant modality in many fields, yet it is given hardly any research attention and significantly lags behind in terms of scale and power. We believe the time is now to start developing tabular foundation models, or what we coin a Large Tabular Model (LTM). LTMs could revolutionise the way science and ML use tabular data: not as single datasets that are analyzed in a vacuum, but contextualized with respect to related datasets. The potential impact is far-reaching: from few-shot tabular models to automating data science; from out-of-distribution synthetic data to empowering multidisciplinary scientific discovery. We intend to excite reflections on the modalities we study, and convince some researchers to study large tabular models.
RadEdit: stress-testing biomedical vision models via diffusion image editing
Dec 21, 2023Biomedical imaging datasets are often small and biased, meaning that real-world performance of predictive models can be substantially lower than expected from internal testing. This work proposes using generative image editing to simulate dataset shifts and diagnose failure modes of biomedical vision models; this can be used in advance of deployment to assess readiness, potentially reducing cost and patient harm. Existing editing methods can produce undesirable changes, with spurious correlations learned due to the co-occurrence of disease and treatment interventions, limiting practical applicability. To address this, we train a text-to-image diffusion model on multiple chest X-ray datasets and introduce a new editing method RadEdit that uses multiple masks, if present, to constrain changes and ensure consistency in the edited images. We consider three types of dataset shifts: acquisition shift, manifestation shift, and population shift, and demonstrate that our approach can diagnose failures and quantify model robustness without additional data collection, complementing more qualitative tools for explainable AI.
Curated LLM: Synergy of LLMs and Data Curation for tabular augmentation in ultra low-data regimes
Dec 19, 2023Machine Learning (ML) in low-data settings remains an underappreciated yet crucial problem. This challenge is pronounced in low-to-middle income countries where access to large datasets is often limited or even absent. Hence, data augmentation methods to increase the sample size of datasets needed for ML are key to unlocking the transformative potential of ML in data-deprived regions and domains. Unfortunately, the limited training set constrains traditional tabular synthetic data generators in their ability to generate a large and diverse augmented dataset needed for ML tasks. To address this technical challenge, we introduce CLLM, which leverages the prior knowledge of Large Language Models (LLMs) for data augmentation in the low-data regime. While diverse, not all the data generated by LLMs will help increase utility for a downstream task, as for any generative model. Consequently, we introduce a principled curation process, leveraging learning dynamics, coupled with confidence and uncertainty metrics, to obtain a high-quality dataset. Empirically, on multiple real-world datasets, we demonstrate the superior performance of LLMs in the low-data regime compared to conventional generators. We further show our curation mechanism improves the downstream performance for all generators, including LLMs. Additionally, we provide insights and understanding into the LLM generation and curation mechanism, shedding light on the features that enable them to output high-quality augmented datasets. CLLM paves the way for wider usage of ML in data scarce domains and regions, by allying the strengths of LLMs with a robust data-centric approach.
Can You Rely on Your Model Evaluation? Improving Model Evaluation with Synthetic Test Data
Oct 25, 2023Evaluating the performance of machine learning models on diverse and underrepresented subgroups is essential for ensuring fairness and reliability in real-world applications. However, accurately assessing model performance becomes challenging due to two main issues: (1) a scarcity of test data, especially for small subgroups, and (2) possible distributional shifts in the model's deployment setting, which may not align with the available test data. In this work, we introduce 3S Testing, a deep generative modeling framework to facilitate model evaluation by generating synthetic test sets for small subgroups and simulating distributional shifts. Our experiments demonstrate that 3S Testing outperforms traditional baselines -- including real test data alone -- in estimating model performance on minority subgroups and under plausible distributional shifts. In addition, 3S offers intervals around its performance estimates, exhibiting superior coverage of the ground truth compared to existing approaches. Overall, these results raise the question of whether we need a paradigm shift away from limited real test data towards synthetic test data.