 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncreasing the Thinking Budget is Not All You Need
Dec 22, 2025Recently, a new wave of thinking-capable Large Language Models has emerged, demonstrating exceptional capabilities across a wide range of reasoning benchmarks. Early studies have begun to explore how the amount of compute in terms of the length of the reasoning process, the so-called thinking budget, impacts model performance. In this work, we propose a systematic investigation of the thinking budget as a key parameter, examining its interaction with various configurations such as self-consistency, reflection, and others. Our goal is to provide an informative, balanced comparison framework that considers both performance outcomes and computational cost. Among our findings, we discovered that simply increasing the thinking budget is not the most effective use of compute. More accurate responses can instead be achieved through alternative configurations, such as self-consistency and self-reflection.
ODE Discovery for Longitudinal Heterogeneous Treatment Effects Inference
Mar 16, 2024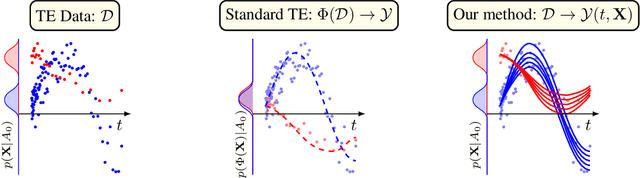

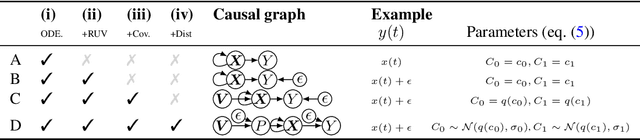
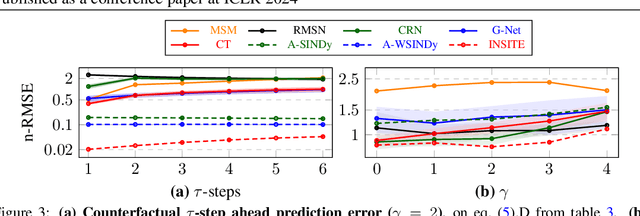
Inferring unbiased treatment effects has received widespread attention in the machine learning community. In recent years, our community has proposed numerous solutions in standard settings, high-dimensional treatment settings, and even longitudinal settings. While very diverse, the solution has mostly relied on neural networks for inference and simultaneous correction of assignment bias. New approaches typically build on top of previous approaches by proposing new (or refined) architectures and learning algorithms. However, the end result -- a neural-network-based inference machine -- remains unchallenged. In this paper, we introduce a different type of solution in the longitudinal setting: a closed-form ordinary differential equation (ODE). While we still rely on continuous optimization to learn an ODE, the resulting inference machine is no longer a neural network. Doing so yields several advantages such as interpretability, irregular sampling, and a different set of identification assumptions. Above all, we consider the introduction of a completely new type of solution to be our most important contribution as it may spark entirely new innovations in treatment effects in general. We facilitate this by formulating our contribution as a framework that can transform any ODE discovery method into a treatment effects method.
DAGnosis: Localized Identification of Data Inconsistencies using Structures
Feb 28, 2024



Identification and appropriate handling of inconsistencies in data at deployment time is crucial to reliably use machine learning models. While recent data-centric methods are able to identify such inconsistencies with respect to the training set, they suffer from two key limitations: (1) suboptimality in settings where features exhibit statistical independencies, due to their usage of compressive representations and (2) lack of localization to pin-point why a sample might be flagged as inconsistent, which is important to guide future data collection. We solve these two fundamental limitations using directed acyclic graphs (DAGs) to encode the training set's features probability distribution and independencies as a structure. Our method, called DAGnosis, leverages these structural interactions to bring valuable and insightful data-centric conclusions. DAGnosis unlocks the localization of the causes of inconsistencies on a DAG, an aspect overlooked by previous approaches. Moreover, we show empirically that leveraging these interactions (1) leads to more accurate conclusions in detecting inconsistencies, as well as (2) provides more detailed insights into why some samples are flagged.
Adaptive Experiment Design with Synthetic Controls
Jan 30, 2024Clinical trials are typically run in order to understand the effects of a new treatment on a given population of patients. However, patients in large populations rarely respond the same way to the same treatment. This heterogeneity in patient responses necessitates trials that investigate effects on multiple subpopulations - especially when a treatment has marginal or no benefit for the overall population but might have significant benefit for a particular subpopulation. Motivated by this need, we propose Syntax, an exploratory trial design that identifies subpopulations with positive treatment effect among many subpopulations. Syntax is sample efficient as it (i) recruits and allocates patients adaptively and (ii) estimates treatment effects by forming synthetic controls for each subpopulation that combines control samples from other subpopulations. We validate the performance of Syntax and provide insights into when it might have an advantage over conventional trial designs through experiments.
Deep Generative Symbolic Regression
Dec 30, 2023



Symbolic regression (SR) aims to discover concise closed-form mathematical equations from data, a task fundamental to scientific discovery. However, the problem is highly challenging because closed-form equations lie in a complex combinatorial search space. Existing methods, ranging from heuristic search to reinforcement learning, fail to scale with the number of input variables. We make the observation that closed-form equations often have structural characteristics and invariances (e.g., the commutative law) that could be further exploited to build more effective symbolic regression solutions. Motivated by this observation, our key contribution is to leverage pre-trained deep generative models to capture the intrinsic regularities of equations, thereby providing a solid foundation for subsequent optimization steps. We show that our novel formalism unifies several prominent approaches of symbolic regression and offers a new perspective to justify and improve on the previous ad hoc designs, such as the usage of cross-entropy loss during pre-training. Specifically, we propose an instantiation of our framework, Deep Generative Symbolic Regression (DGSR). In our experiments, we show that DGSR achieves a higher recovery rate of true equations in the setting of a larger number of input variables, and it is more computationally efficient at inference time than state-of-the-art RL symbolic regression solutions.
* In the proceedings of the Eleventh International Conference on Learning Representations (ICLR 2023). https://iclr.cc/virtual/2023/poster/11782
TRIAGE: Characterizing and auditing training data for improved regression
Oct 29, 2023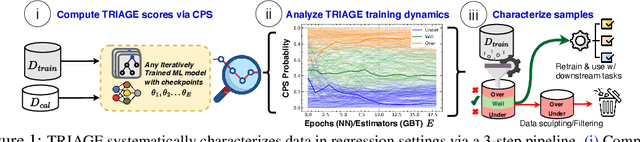

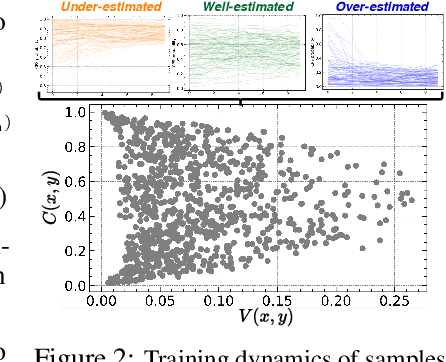

Data quality is crucial for robust machine learning algorithms, with the recent interest in data-centric AI emphasizing the importance of training data characterization. However, current data characterization methods are largely focused on classification settings, with regression settings largely understudied. To address this, we introduce TRIAGE, a novel data characterization framework tailored to regression tasks and compatible with a broad class of regressors. TRIAGE utilizes conformal predictive distributions to provide a model-agnostic scoring method, the TRIAGE score. We operationalize the score to analyze individual samples' training dynamics and characterize samples as under-, over-, or well-estimated by the model. We show that TRIAGE's characterization is consistent and highlight its utility to improve performance via data sculpting/filtering, in multiple regression settings. Additionally, beyond sample level, we show TRIAGE enables new approaches to dataset selection and feature acquisition. Overall, TRIAGE highlights the value unlocked by data characterization in real-world regression applications
Clairvoyance: A Pipeline Toolkit for Medical Time Series
Oct 28, 2023Time-series learning is the bread and butter of data-driven *clinical decision support*, and the recent explosion in ML research has demonstrated great potential in various healthcare settings. At the same time, medical time-series problems in the wild are challenging due to their highly *composite* nature: They entail design choices and interactions among components that preprocess data, impute missing values, select features, issue predictions, estimate uncertainty, and interpret models. Despite exponential growth in electronic patient data, there is a remarkable gap between the potential and realized utilization of ML for clinical research and decision support. In particular, orchestrating a real-world project lifecycle poses challenges in engineering (i.e. hard to build), evaluation (i.e. hard to assess), and efficiency (i.e. hard to optimize). Designed to address these issues simultaneously, Clairvoyance proposes a unified, end-to-end, autoML-friendly pipeline that serves as a (i) software toolkit, (ii) empirical standard, and (iii) interface for optimization. Our ultimate goal lies in facilitating transparent and reproducible experimentation with complex inference workflows, providing integrated pathways for (1) personalized prediction, (2) treatment-effect estimation, and (3) information acquisition. Through illustrative examples on real-world data in outpatient, general wards, and intensive-care settings, we illustrate the applicability of the pipeline paradigm on core tasks in the healthcare journey. To the best of our knowledge, Clairvoyance is the first to demonstrate viability of a comprehensive and automatable pipeline for clinical time-series ML.
Do Diffusion Models Suffer Error Propagation? Theoretical Analysis and Consistency Regularization
Aug 09, 2023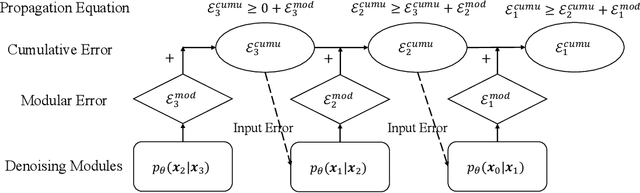

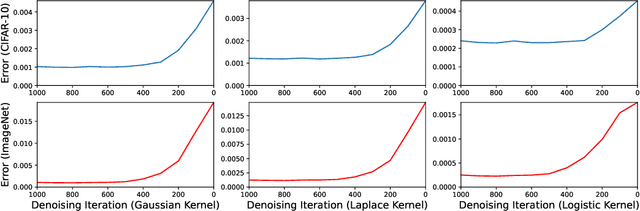

While diffusion models have achieved promising performances in data synthesis, they might suffer error propagation because of their cascade structure, where the distributional mismatch spreads and magnifies through the chain of denoising modules. However, a strict analysis is expected since many sequential models such as Conditional Random Field (CRF) are free from error propagation. In this paper, we empirically and theoretically verify that diffusion models are indeed affected by error propagation and we then propose a regularization to address this problem. Our theoretical analysis reveals that the question can be reduced to whether every denoising module of the diffusion model is fault-tolerant. We derive insightful transition equations, indicating that the module can't recover from input errors and even propagates additional errors to the next module. Our analysis directly leads to a consistency regularization scheme for diffusion models, which explicitly reduces the distribution gap between forward and backward processes. We further introduce a bootstrapping algorithm to reduce the computation cost of the regularizer. Our experimental results on multiple image datasets show that our regularization effectively handles error propagation and significantly improves the performance of vanilla diffusion models.
Learning Representations without Compositional Assumptions
May 31, 2023



This paper addresses unsupervised representation learning on tabular data containing multiple views generated by distinct sources of measurement. Traditional methods, which tackle this problem using the multi-view framework, are constrained by predefined assumptions that assume feature sets share the same information and representations should learn globally shared factors. However, this assumption is not always valid for real-world tabular datasets with complex dependencies between feature sets, resulting in localized information that is harder to learn. To overcome this limitation, we propose a data-driven approach that learns feature set dependencies by representing feature sets as graph nodes and their relationships as learnable edges. Furthermore, we introduce LEGATO, a novel hierarchical graph autoencoder that learns a smaller, latent graph to aggregate information from multiple views dynamically. This approach results in latent graph components that specialize in capturing localized information from different regions of the input, leading to superior downstream performance.
Synthetic data, real errors: how to publish and use synthetic data
May 16, 2023Generating synthetic data through generative models is gaining interest in the ML community and beyond, promising a future where datasets can be tailored to individual needs. Unfortunately, synthetic data is usually not perfect, resulting in potential errors in downstream tasks. In this work we explore how the generative process affects the downstream ML task. We show that the naive synthetic data approach -- using synthetic data as if it is real -- leads to downstream models and analyses that do not generalize well to real data. As a first step towards better ML in the synthetic data regime, we introduce Deep Generative Ensemble (DGE) -- a framework inspired by Deep Ensembles that aims to implicitly approximate the posterior distribution over the generative process model parameters. DGE improves downstream model training, evaluation, and uncertainty quantification, vastly outperforming the naive approach on average. The largest improvements are achieved for minority classes and low-density regions of the original data, for which the generative uncertainty is largest.