 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaliGemma: A versatile 3B VLM for transfer
Jul 10, 2024



PaliGemma is an open Vision-Language Model (VLM) that is based on the SigLIP-So400m vision encoder and the Gemma-2B language model. It is trained to be a versatile and broadly knowledgeable base model that is effective to transfer. It achieves strong performance on a wide variety of open-world tasks. We evaluate PaliGemma on almost 40 diverse tasks including standard VLM benchmarks, but also more specialized tasks such as remote-sensing and segmentation.
Improving fine-grained understanding in image-text pre-training
Jan 18, 2024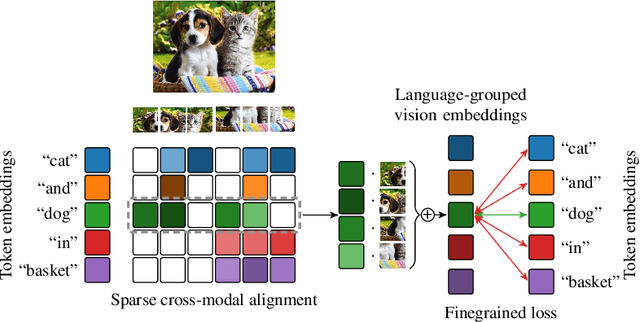
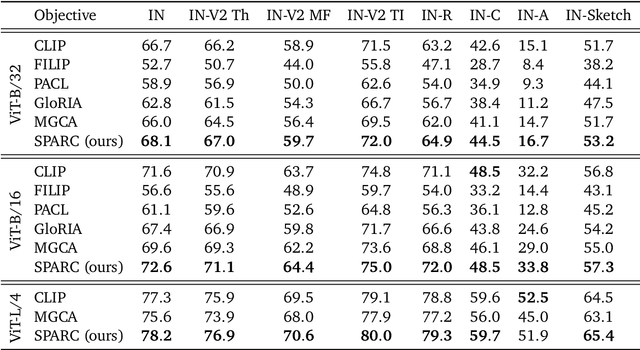
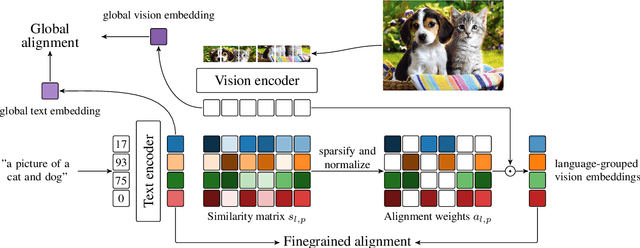
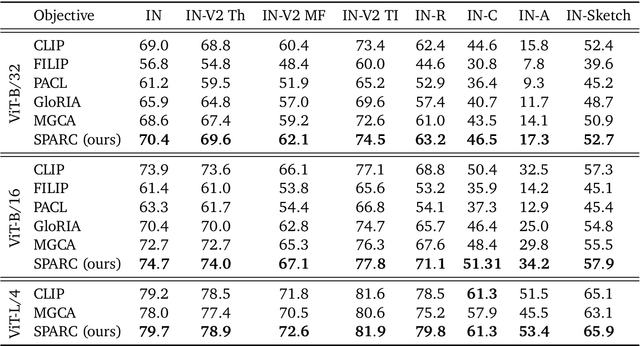
We introduce SPARse Fine-grained Contrastive Alignment (SPARC), a simple method for pretraining more fine-grained multimodal representations from image-text pairs. Given that multiple image patches often correspond to single words, we propose to learn a grouping of image patches for every token in the caption. To achieve this, we use a sparse similarity metric between image patches and language tokens and compute for each token a language-grouped vision embedding as the weighted average of patches. The token and language-grouped vision embeddings are then contrasted through a fine-grained sequence-wise loss that only depends on individual samples and does not require other batch samples as negatives. This enables more detailed information to be learned in a computationally inexpensive manner. SPARC combines this fine-grained loss with a contrastive loss between global image and text embeddings to learn representations that simultaneously encode global and local information. We thoroughly evaluate our proposed method and show improved performance over competing approaches both on image-level tasks relying on coarse-grained information, e.g. classification, as well as region-level tasks relying on fine-grained information, e.g. retrieval, object detection, and segmentation. Moreover, SPARC improves model faithfulness and captioning in foundational vision-language models.
Time-series Generation by Contrastive Imitation
Nov 02, 2023



Consider learning a generative model for time-series data. The sequential setting poses a unique challenge: Not only should the generator capture the conditional dynamics of (stepwise) transitions, but its open-loop rollouts should also preserve the joint distribution of (multi-step) trajectories. On one hand, autoregressive models trained by MLE allow learning and computing explicit transition distributions, but suffer from compounding error during rollouts. On the other hand, adversarial models based on GAN training alleviate such exposure bias, but transitions are implicit and hard to assess. In this work, we study a generative framework that seeks to combine the strengths of both: Motivated by a moment-matching objective to mitigate compounding error, we optimize a local (but forward-looking) transition policy, where the reinforcement signal is provided by a global (but stepwise-decomposable) energy model trained by contrastive estimation. At training, the two components are learned cooperatively, avoiding the instabilities typical of adversarial objectives. At inference, the learned policy serves as the generator for iterative sampling, and the learned energy serves as a trajectory-level measure for evaluating sample quality. By expressly training a policy to imitate sequential behavior of time-series features in a dataset, this approach embodies "generation by imitation". Theoretically, we illustrate the correctness of this formulation and the consistency of the algorithm. Empirically, we evaluate its ability to generate predictively useful samples from real-world datasets, verifying that it performs at the standard of existing benchmarks.
Invariant Causal Imitation Learning for Generalizable Policies
Nov 02, 2023Consider learning an imitation policy on the basis of demonstrated behavior from multiple environments, with an eye towards deployment in an unseen environment. Since the observable features from each setting may be different, directly learning individual policies as mappings from features to actions is prone to spurious correlations -- and may not generalize well. However, the expert's policy is often a function of a shared latent structure underlying those observable features that is invariant across settings. By leveraging data from multiple environments, we propose Invariant Causal Imitation Learning (ICIL), a novel technique in which we learn a feature representation that is invariant across domains, on the basis of which we learn an imitation policy that matches expert behavior. To cope with transition dynamics mismatch, ICIL learns a shared representation of causal features (for all training environments), that is disentangled from the specific representations of noise variables (for each of those environments). Moreover, to ensure that the learned policy matches the observation distribution of the expert's policy, ICIL estimates the energy of the expert's observations and uses a regularization term that minimizes the imitator policy's next state energy. Experimentally, we compare our methods against several benchmarks in control and healthcare tasks and show its effectiveness in learning imitation policies capable of generalizing to unseen environments.
Clairvoyance: A Pipeline Toolkit for Medical Time Series
Oct 28, 2023Time-series learning is the bread and butter of data-driven *clinical decision support*, and the recent explosion in ML research has demonstrated great potential in various healthcare settings. At the same time, medical time-series problems in the wild are challenging due to their highly *composite* nature: They entail design choices and interactions among components that preprocess data, impute missing values, select features, issue predictions, estimate uncertainty, and interpret models. Despite exponential growth in electronic patient data, there is a remarkable gap between the potential and realized utilization of ML for clinical research and decision support. In particular, orchestrating a real-world project lifecycle poses challenges in engineering (i.e. hard to build), evaluation (i.e. hard to assess), and efficiency (i.e. hard to optimize). Designed to address these issues simultaneously, Clairvoyance proposes a unified, end-to-end, autoML-friendly pipeline that serves as a (i) software toolkit, (ii) empirical standard, and (iii) interface for optimization. Our ultimate goal lies in facilitating transparent and reproducible experimentation with complex inference workflows, providing integrated pathways for (1) personalized prediction, (2) treatment-effect estimation, and (3) information acquisition. Through illustrative examples on real-world data in outpatient, general wards, and intensive-care settings, we illustrate the applicability of the pipeline paradigm on core tasks in the healthcare journey. To the best of our knowledge, Clairvoyance is the first to demonstrate viability of a comprehensive and automatable pipeline for clinical time-series ML.
Neural Algorithmic Reasoning with Causal Regularisation
Feb 20, 2023



Recent work on neural algorithmic reasoning has investigated the reasoning capabilities of neural networks, effectively demonstrating they can learn to execute classical algorithms on unseen data coming from the train distribution. However, the performance of existing neural reasoners significantly degrades on out-of-distribution (OOD) test data, where inputs have larger sizes. In this work, we make an important observation: there are many \emph{different} inputs for which an algorithm will perform certain intermediate computations \emph{identically}. This insight allows us to develop data augmentation procedures that, given an algorithm's intermediate trajectory, produce inputs for which the target algorithm would have \emph{exactly} the same next trajectory step. Then, we employ a causal framework to design a corresponding self-supervised objective, and we prove that it improves the OOD generalisation capabilities of the reasoner. We evaluate our method on the CLRS algorithmic reasoning benchmark, where we show up to 3$\times$ improvements on the OOD test data.
Data-IQ: Characterizing subgroups with heterogeneous outcomes in tabular data
Oct 24, 2022High model performance, on average, can hide that models may systematically underperform on subgroups of the data. We consider the tabular setting, which surfaces the unique issue of outcome heterogeneity - this is prevalent in areas such as healthcare, where patients with similar features can have different outcomes, thus making reliable predictions challenging. To tackle this, we propose Data-IQ, a framework to systematically stratify examples into subgroups with respect to their outcomes. We do this by analyzing the behavior of individual examples during training, based on their predictive confidence and, importantly, the aleatoric (data) uncertainty. Capturing the aleatoric uncertainty permits a principled characterization and then subsequent stratification of data examples into three distinct subgroups (Easy, Ambiguous, Hard). We experimentally demonstrate the benefits of Data-IQ on four real-world medical datasets. We show that Data-IQ's characterization of examples is most robust to variation across similarly performant (yet different) models, compared to baselines. Since Data-IQ can be used with any ML model (including neural networks, gradient boosting etc.), this property ensures consistency of data characterization, while allowing flexible model selection. Taking this a step further, we demonstrate that the subgroups enable us to construct new approaches to both feature acquisition and dataset selection. Furthermore, we highlight how the subgroups can inform reliable model usage, noting the significant impact of the Ambiguous subgroup on model generalization.
Transfer Learning on Heterogeneous Feature Spaces for Treatment Effects Estimation
Oct 08, 2022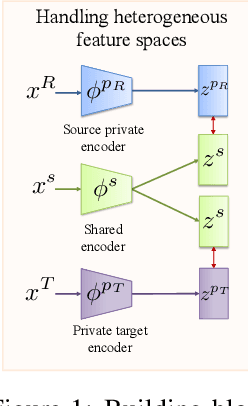

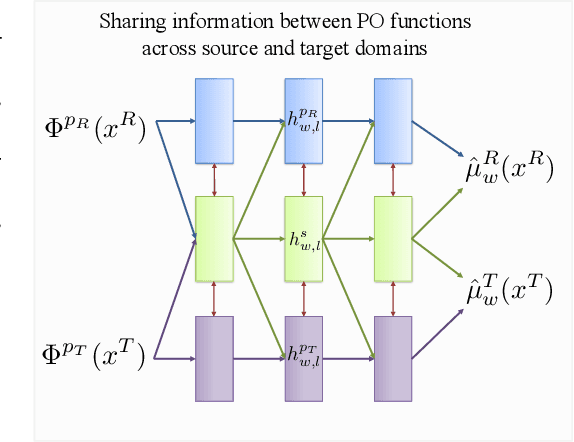

Consider the problem of improving the estimation of conditional average treatment effects (CATE) for a target domain of interest by leveraging related information from a source domain with a different feature space. This heterogeneous transfer learning problem for CATE estimation is ubiquitous in areas such as healthcare where we may wish to evaluate the effectiveness of a treatment for a new patient population for which different clinical covariates and limited data are available. In this paper, we address this problem by introducing several building blocks that use representation learning to handle the heterogeneous feature spaces and a flexible multi-task architecture with shared and private layers to transfer information between potential outcome functions across domains. Then, we show how these building blocks can be used to recover transfer learning equivalents of the standard CATE learners. On a new semi-synthetic data simulation benchmark for heterogeneous transfer learning we not only demonstrate performance improvements of our heterogeneous transfer causal effect learners across datasets, but also provide insights into the differences between these learners from a transfer perspective.
DAPDAG: Domain Adaptation via Perturbed DAG Reconstruction
Aug 02, 2022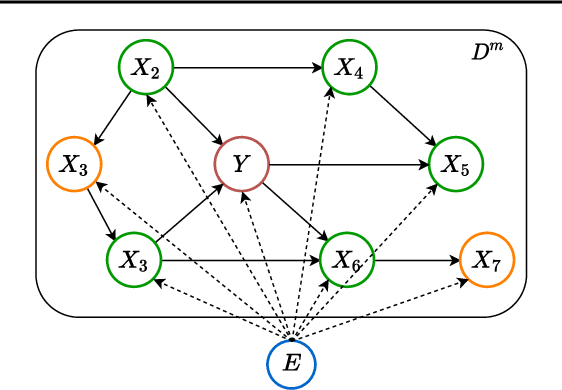
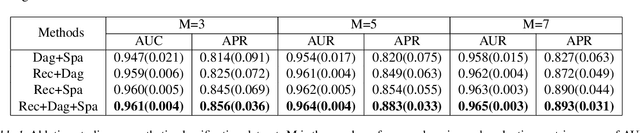
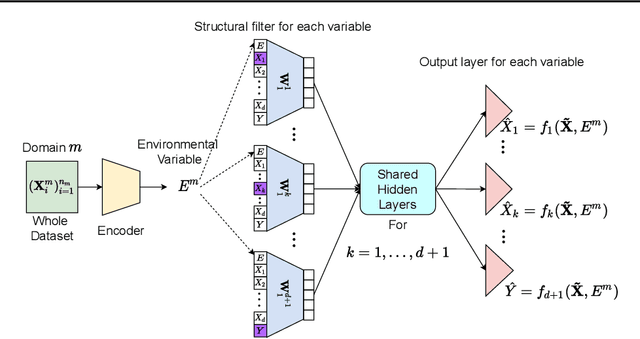
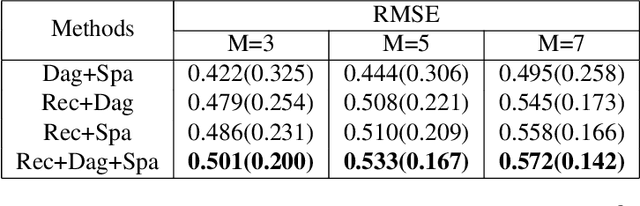
Leveraging labelled data from multiple domains to enable prediction in another domain without labels is a significant, yet challenging problem. To address this problem, we introduce the framework DAPDAG (\textbf{D}omain \textbf{A}daptation via \textbf{P}erturbed \textbf{DAG} Reconstruction) and propose to learn an auto-encoder that undertakes inference on population statistics given features and reconstructing a directed acyclic graph (DAG) as an auxiliary task. The underlying DAG structure is assumed invariant among observed variables whose conditional distributions are allowed to vary across domains led by a latent environmental variable $E$. The encoder is designed to serve as an inference device on $E$ while the decoder reconstructs each observed variable conditioned on its graphical parents in the DAG and the inferred $E$. We train the encoder and decoder jointly in an end-to-end manner and conduct experiments on synthetic and real datasets with mixed variables. Empirical results demonstrate that reconstructing the DAG benefits the approximate inference. Furthermore, our approach can achieve competitive performance against other benchmarks in prediction tasks, with better adaptation ability, especially in the target domain significantly different from the source domains.
Benchmarking Heterogeneous Treatment Effect Models through the Lens of Interpretability
Jun 16, 2022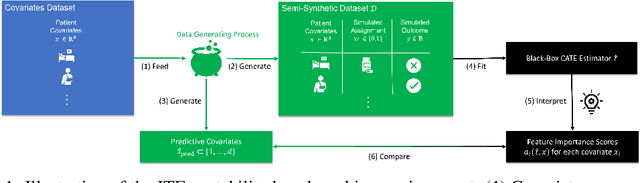


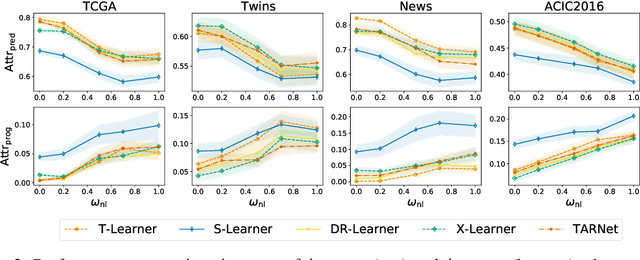
Estimating personalized effects of treatments is a complex, yet pervasive problem. To tackle it, recent developments in the machine learning (ML) literature on heterogeneous treatment effect estimation gave rise to many sophisticated, but opaque, tools: due to their flexibility, modularity and ability to learn constrained representations, neural networks in particular have become central to this literature. Unfortunately, the assets of such black boxes come at a cost: models typically involve countless nontrivial operations, making it difficult to understand what they have learned. Yet, understanding these models can be crucial -- in a medical context, for example, discovered knowledge on treatment effect heterogeneity could inform treatment prescription in clinical practice. In this work, we therefore use post-hoc feature importance methods to identify features that influence the model's predictions. This allows us to evaluate treatment effect estimators along a new and important dimension that has been overlooked in previous work: We construct a benchmarking environment to empirically investigate the ability of personalized treatment effect models to identify predictive covariates -- covariates that determine differential responses to treatment. Our benchmarking environment then enables us to provide new insight into the strengths and weaknesses of different types of treatment effects models as we modulate different challenges specific to treatment effect estimation -- e.g. the ratio of prognostic to predictive information, the possible nonlinearity of potential outcomes and the presence and type of confounding.