 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features
Feb 20, 2025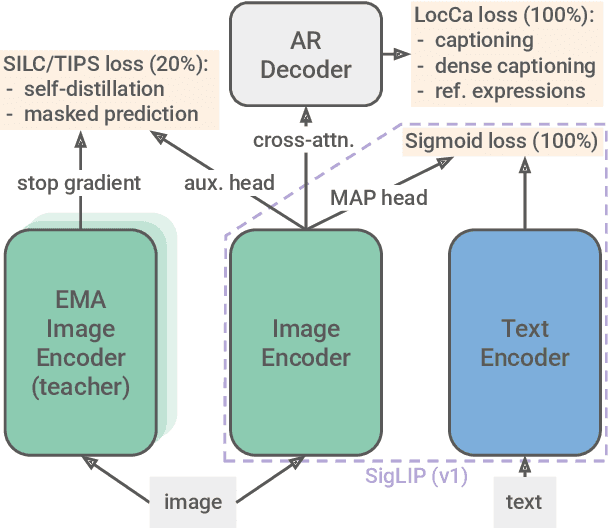
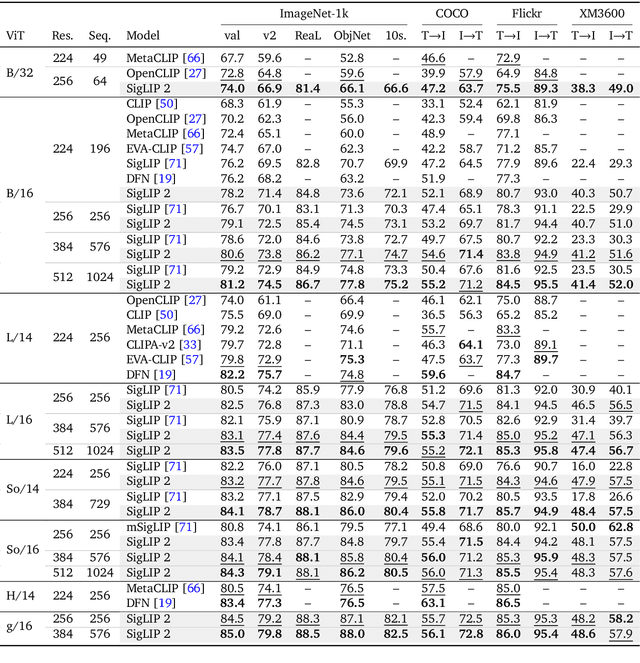
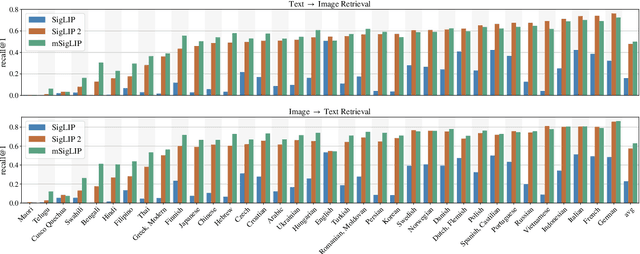
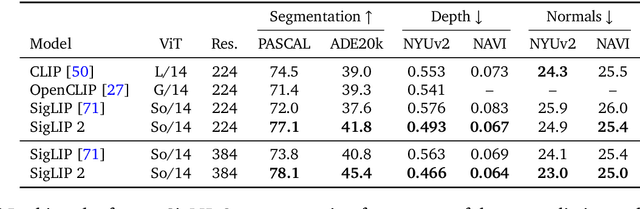
We introduce SigLIP 2, a family of new multilingual vision-language encoders that build on the success of the original SigLIP. In this second iteration, we extend the original image-text training objective with several prior, independently developed techniques into a unified recipe -- this includes captioning-based pretraining, self-supervised losses (self-distillation, masked prediction) and online data curation. With these changes, SigLIP 2 models outperform their SigLIP counterparts at all model scales in core capabilities, including zero-shot classification, image-text retrieval, and transfer performance when extracting visual representations for Vision-Language Models (VLMs). Furthermore, the new training recipe leads to significant improvements on localization and dense prediction tasks. We also train variants which support multiple resolutions and preserve the input's native aspect ratio. Finally, we train on a more diverse data-mixture that includes de-biasing techniques, leading to much better multilingual understanding and improved fairness. To allow users to trade off inference cost with performance, we release model checkpoints at four sizes: ViT-B (86M), L (303M), So400m (400M), and g (1B).
A Tale of Two Structures: Do LLMs Capture the Fractal Complexity of Language?
Feb 19, 2025Language exhibits a fractal structure in its information-theoretic complexity (i.e. bits per token), with self-similarity across scales and long-range dependence (LRD). In this work, we investigate whether large language models (LLMs) can replicate such fractal characteristics and identify conditions-such as temperature setting and prompting method-under which they may fail. Moreover, we find that the fractal parameters observed in natural language are contained within a narrow range, whereas those of LLMs' output vary widely, suggesting that fractal parameters might prove helpful in detecting a non-trivial portion of LLM-generated texts. Notably, these findings, and many others reported in this work, are robust to the choice of the architecture; e.g. Gemini 1.0 Pro, Mistral-7B and Gemma-2B. We also release a dataset comprising of over 240,000 articles generated by various LLMs (both pretrained and instruction-tuned) with different decoding temperatures and prompting methods, along with their corresponding human-generated texts. We hope that this work highlights the complex interplay between fractal properties, prompting, and statistical mimicry in LLMs, offering insights for generating, evaluating and detecting synthetic texts.
Harnessing Language's Fractal Geometry with Recursive Inference Scaling
Feb 11, 2025



Recent research in language modeling reveals two scaling effects: the well-known improvement from increased training compute, and a lesser-known boost from applying more sophisticated or computationally intensive inference methods. Inspired by recent findings on the fractal geometry of language, we introduce Recursive INference Scaling (RINS) as a complementary, plug-in recipe for scaling inference time. For a given fixed model architecture and training compute budget, RINS substantially improves language modeling performance. It also generalizes beyond pure language tasks, delivering gains in multimodal systems, including a +2% improvement in 0-shot ImageNet accuracy for SigLIP-B/16. Additionally, by deriving data scaling laws, we show that RINS improves both the asymptotic performance limits and the scaling exponents. These advantages are maintained even when compared to state-of-the-art recursive techniques like the "repeat-all-over" (RAO) strategy in Mobile LLM. Finally, stochastic RINS not only can enhance performance further but also provides the flexibility to optionally forgo increased inference computation at test time with minimal performance degradation.
Scaling Pre-training to One Hundred Billion Data for Vision Language Models
Feb 11, 2025We provide an empirical investigation of the potential of pre-training vision-language models on an unprecedented scale: 100 billion examples. We find that model performance tends to saturate at this scale on many common Western-centric classification and retrieval benchmarks, such as COCO Captions. Nevertheless, tasks of cultural diversity achieve more substantial gains from the 100-billion scale web data, thanks to its coverage of long-tail concepts. Furthermore, we analyze the model's multilinguality and show gains in low-resource languages as well. In addition, we observe that reducing the size of the pretraining dataset via quality filters like using CLIP, typically used to enhance performance, may inadvertently reduce the cultural diversity represented even in large-scale datasets. Our results highlight that while traditional benchmarks may not benefit significantly from scaling noisy, raw web data to 100 billion examples, this data scale is vital for building truly inclusive multimodal systems.
PaliGemma 2: A Family of Versatile VLMs for Transfer
Dec 04, 2024



PaliGemma 2 is an upgrade of the PaliGemma open Vision-Language Model (VLM) based on the Gemma 2 family of language models. We combine the SigLIP-So400m vision encoder that was also used by PaliGemma with the whole range of Gemma 2 models, from the 2B one all the way up to the 27B model. We train these models at three resolutions (224px, 448px, and 896px) in multiple stages to equip them with broad knowledge for transfer via fine-tuning. The resulting family of base models covering different model sizes and resolutions allows us to investigate factors impacting transfer performance (such as learning rate) and to analyze the interplay between the type of task, model size, and resolution. We further increase the number and breadth of transfer tasks beyond the scope of PaliGemma including different OCR-related tasks such as table structure recognition, molecular structure recognition, music score recognition, as well as long fine-grained captioning and radiography report generation, on which PaliGemma 2 obtains state-of-the-art results.
PaliGemma: A versatile 3B VLM for transfer
Jul 10, 2024



PaliGemma is an open Vision-Language Model (VLM) that is based on the SigLIP-So400m vision encoder and the Gemma-2B language model. It is trained to be a versatile and broadly knowledgeable base model that is effective to transfer. It achieves strong performance on a wide variety of open-world tasks. We evaluate PaliGemma on almost 40 diverse tasks including standard VLM benchmarks, but also more specialized tasks such as remote-sensing and segmentation.
No Filter: Cultural and Socioeconomic Diversityin Contrastive Vision-Language Models
May 22, 2024We study cultural and socioeconomic diversity in contrastive vision-language models (VLMs). Using a broad range of benchmark datasets and evaluation metrics, we bring to attention several important findings. First, the common filtering of training data to English image-text pairs disadvantages communities of lower socioeconomic status and negatively impacts cultural understanding. Notably, this performance gap is not captured by -- and even at odds with -- the currently popular evaluation metrics derived from the Western-centric ImageNet and COCO datasets. Second, pretraining with global, unfiltered data before fine-tuning on English content can improve cultural understanding without sacrificing performance on said popular benchmarks. Third, we introduce the task of geo-localization as a novel evaluation metric to assess cultural diversity in VLMs. Our work underscores the value of using diverse data to create more inclusive multimodal systems and lays the groundwork for developing VLMs that better represent global perspectives.
LocCa: Visual Pretraining with Location-aware Captioners
Mar 28, 2024



Image captioning has been shown as an effective pretraining method similar to contrastive pretraining. However, the incorporation of location-aware information into visual pretraining remains an area with limited research. In this paper, we propose a simple visual pretraining method with location-aware captioners (LocCa). LocCa uses a simple image captioner task interface, to teach a model to read out rich information, i.e. bounding box coordinates, and captions, conditioned on the image pixel input. Thanks to the multitask capabilities of an encoder-decoder architecture, we show that an image captioner can easily handle multiple tasks during pretraining. Our experiments demonstrate that LocCa outperforms standard captioners significantly on localization downstream tasks while maintaining comparable performance on holistic tasks.
CLIP the Bias: How Useful is Balancing Data in Multimodal Learning?
Mar 07, 2024



We study the effectiveness of data-balancing for mitigating biases in contrastive language-image pretraining (CLIP), identifying areas of strength and limitation. First, we reaffirm prior conclusions that CLIP models can inadvertently absorb societal stereotypes. To counter this, we present a novel algorithm, called Multi-Modal Moment Matching (M4), designed to reduce both representation and association biases (i.e. in first- and second-order statistics) in multimodal data. We use M4 to conduct an in-depth analysis taking into account various factors, such as the model, representation, and data size. Our study also explores the dynamic nature of how CLIP learns and unlearns biases. In particular, we find that fine-tuning is effective in countering representation biases, though its impact diminishes for association biases. Also, data balancing has a mixed impact on quality: it tends to improve classification but can hurt retrieval. Interestingly, data and architectural improvements seem to mitigate the negative impact of data balancing on performance; e.g. applying M4 to SigLIP-B/16 with data quality filters improves COCO image-to-text retrieval @5 from 86% (without data balancing) to 87% and ImageNet 0-shot classification from 77% to 77.5%! Finally, we conclude with recommendations for improving the efficacy of data balancing in multimodal systems.
* 32 pages, 20 figures, 7 tables
Fractal Patterns May Unravel the Intelligence in Next-Token Prediction
Feb 02, 2024We study the fractal structure of language, aiming to provide a precise formalism for quantifying properties that may have been previously suspected but not formally shown. We establish that language is: (1) self-similar, exhibiting complexities at all levels of granularity, with no particular characteristic context length, and (2) long-range dependent (LRD), with a Hurst parameter of approximately H=0.70. Based on these findings, we argue that short-term patterns/dependencies in language, such as in paragraphs, mirror the patterns/dependencies over larger scopes, like entire documents. This may shed some light on how next-token prediction can lead to a comprehension of the structure of text at multiple levels of granularity, from words and clauses to broader contexts and intents. We also demonstrate that fractal parameters improve upon perplexity-based bits-per-byte (BPB) in predicting downstream performance. We hope these findings offer a fresh perspective on language and the mechanisms underlying the success of LLMs.