 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCheXPO: Preference Optimization for Chest X-ray VLMs with Counterfactual Rationale
Jul 09, 2025Vision-language models (VLMs) are prone to hallucinations that critically compromise reliability in medical applications. While preference optimization can mitigate these hallucinations through clinical feedback, its implementation faces challenges such as clinically irrelevant training samples, imbalanced data distributions, and prohibitive expert annotation costs. To address these challenges, we introduce CheXPO, a Chest X-ray Preference Optimization strategy that combines confidence-similarity joint mining with counterfactual rationale. Our approach begins by synthesizing a unified, fine-grained multi-task chest X-ray visual instruction dataset across different question types for supervised fine-tuning (SFT). We then identify hard examples through token-level confidence analysis of SFT failures and use similarity-based retrieval to expand hard examples for balancing preference sample distributions, while synthetic counterfactual rationales provide fine-grained clinical preferences, eliminating the need for additional expert input. Experiments show that CheXPO achieves 8.93% relative performance gain using only 5% of SFT samples, reaching state-of-the-art performance across diverse clinical tasks and providing a scalable, interpretable solution for real-world radiology applications.
SHERL: Synthesizing High Accuracy and Efficient Memory for Resource-Limited Transfer Learning
Jul 10, 2024



Parameter-efficient transfer learning (PETL) has emerged as a flourishing research field for adapting large pre-trained models to downstream tasks, greatly reducing trainable parameters while grappling with memory challenges during fine-tuning. To address it, memory-efficient series (METL) avoid backpropagating gradients through the large backbone. However, they compromise by exclusively relying on frozen intermediate outputs and limiting the exhaustive exploration of prior knowledge from pre-trained models. Moreover, the dependency and redundancy between cross-layer features are frequently overlooked, thereby submerging more discriminative representations and causing an inherent performance gap (vs. conventional PETL methods). Hence, we propose an innovative METL strategy called SHERL for resource-limited scenarios to decouple the entire adaptation into two successive and complementary processes. In the early route, intermediate outputs are consolidated via an anti-redundancy operation, enhancing their compatibility for subsequent interactions; thereby in the late route, utilizing minimal late pre-trained layers could alleviate the peak demand on memory overhead and regulate these fairly flexible features into more adaptive and powerful representations for new domains. Extensive ablations on vision-and-language and language-only tasks show that SHERL combines the strengths of both parameter and memory-efficient techniques, performing on-par or better across diverse architectures with lower memory during fine-tuning. Our code is publicly available at: https://github.com/Paranioar/SHERL.
LocCa: Visual Pretraining with Location-aware Captioners
Mar 28, 2024



Image captioning has been shown as an effective pretraining method similar to contrastive pretraining. However, the incorporation of location-aware information into visual pretraining remains an area with limited research. In this paper, we propose a simple visual pretraining method with location-aware captioners (LocCa). LocCa uses a simple image captioner task interface, to teach a model to read out rich information, i.e. bounding box coordinates, and captions, conditioned on the image pixel input. Thanks to the multitask capabilities of an encoder-decoder architecture, we show that an image captioner can easily handle multiple tasks during pretraining. Our experiments demonstrate that LocCa outperforms standard captioners significantly on localization downstream tasks while maintaining comparable performance on holistic tasks.
Animate Your Motion: Turning Still Images into Dynamic Videos
Mar 15, 2024
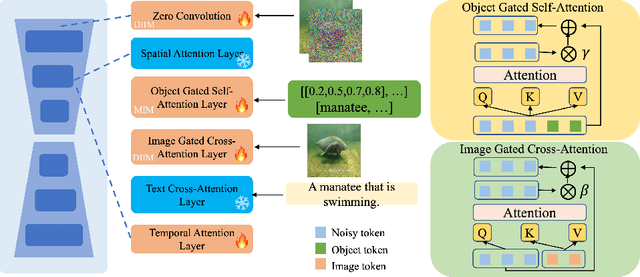
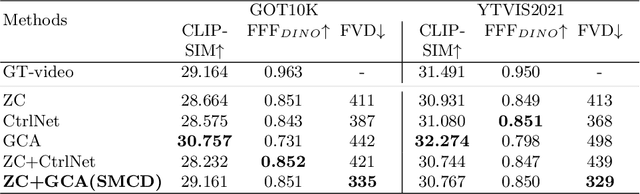
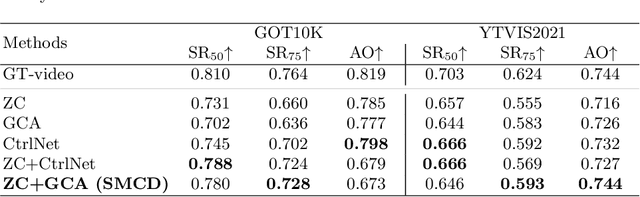
In recent years, diffusion models have made remarkable strides in text-to-video generation, sparking a quest for enhanced control over video outputs to more accurately reflect user intentions. Traditional efforts predominantly focus on employing either semantic cues, like images or depth maps, or motion-based conditions, like moving sketches or object bounding boxes. Semantic inputs offer a rich scene context but lack detailed motion specificity; conversely, motion inputs provide precise trajectory information but miss the broader semantic narrative. For the first time, we integrate both semantic and motion cues within a diffusion model for video generation, as demonstrated in Fig 1. To this end, we introduce the Scene and Motion Conditional Diffusion (SMCD), a novel methodology for managing multimodal inputs. It incorporates a recognized motion conditioning module and investigates various approaches to integrate scene conditions, promoting synergy between different modalities. For model training, we separate the conditions for the two modalities, introducing a two-stage training pipeline. Experimental results demonstrate that our design significantly enhances video quality, motion precision, and semantic coherence.
Exploiting CLIP for Zero-shot HOI Detection Requires Knowledge Distillation at Multiple Levels
Sep 10, 2023



In this paper, we investigate the task of zero-shot human-object interaction (HOI) detection, a novel paradigm for identifying HOIs without the need for task-specific annotations. To address this challenging task, we employ CLIP, a large-scale pre-trained vision-language model (VLM), for knowledge distillation on multiple levels. Specifically, we design a multi-branch neural network that leverages CLIP for learning HOI representations at various levels, including global images, local union regions encompassing human-object pairs, and individual instances of humans or objects. To train our model, CLIP is utilized to generate HOI scores for both global images and local union regions that serve as supervision signals. The extensive experiments demonstrate the effectiveness of our novel multi-level CLIP knowledge integration strategy. Notably, the model achieves strong performance, which is even comparable with some fully-supervised and weakly-supervised methods on the public HICO-DET benchmark.
UniPT: Universal Parallel Tuning for Transfer Learning with Efficient Parameter and Memory
Aug 28, 2023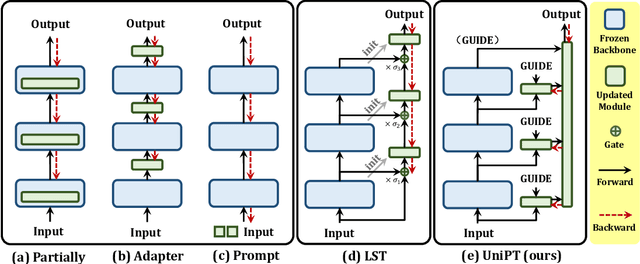
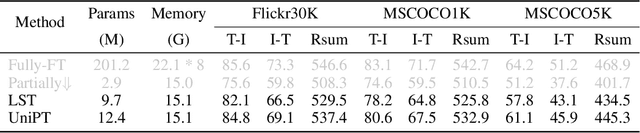
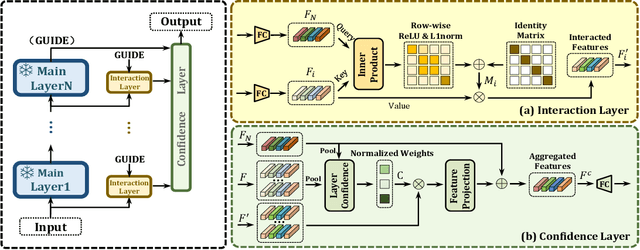
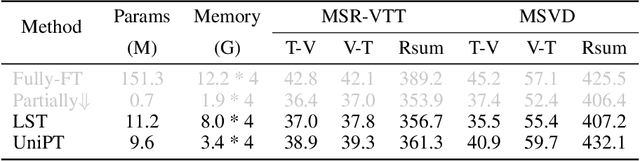
Fine-tuning pre-trained models has emerged as a powerful technique in numerous domains, owing to its ability to leverage enormous pre-existing knowledge and achieve remarkable performance on downstream tasks. However, updating the parameters of entire networks is computationally intensive. Although state-of-the-art parameter-efficient transfer learning (PETL) methods significantly reduce the trainable parameters and storage demand, almost all of them still need to back-propagate the gradients through large pre-trained networks. This memory-extensive characteristic extremely limits the applicability of PETL methods in real-world scenarios. To this end, we propose a new memory-efficient PETL strategy, dubbed Universal Parallel Tuning (UniPT). Specifically, we facilitate the transfer process via a lightweight learnable parallel network, which consists of two modules: 1) A parallel interaction module that decouples the inherently sequential connections and processes the intermediate activations detachedly of the pre-trained network. 2) A confidence aggregation module that learns optimal strategies adaptively for integrating cross-layer features. We evaluate UniPT with different backbones (e.g., VSE$\infty$, CLIP4Clip, Clip-ViL, and MDETR) on five challenging vision-and-language tasks (i.e., image-text retrieval, video-text retrieval, visual question answering, compositional question answering, and visual grounding). Extensive ablations on ten datasets have validated that our UniPT can not only dramatically reduce memory consumption and outperform the best memory-efficient competitor, but also achieve higher performance than existing PETL methods in a low-memory scenario on different architectures. Our code is publicly available at: https://github.com/Paranioar/UniPT.
A Study of Autoregressive Decoders for Multi-Tasking in Computer Vision
Mar 30, 2023



There has been a recent explosion of computer vision models which perform many tasks and are composed of an image encoder (usually a ViT) and an autoregressive decoder (usually a Transformer). However, most of this work simply presents one system and its results, leaving many questions regarding design decisions and trade-offs of such systems unanswered. In this work, we aim to provide such answers. We take a close look at autoregressive decoders for multi-task learning in multimodal computer vision, including classification, captioning, visual question answering, and optical character recognition. Through extensive systematic experiments, we study the effects of task and data mixture, training and regularization hyperparameters, conditioning type and specificity, modality combination, and more. Importantly, we compare these to well-tuned single-task baselines to highlight the cost incurred by multi-tasking. A key finding is that a small decoder learned on top of a frozen pretrained encoder works surprisingly well. We call this setup locked-image tuning with decoder (LiT-decoder). It can be seen as teaching a decoder to interact with a pretrained vision model via natural language.
Weakly-supervised HOI Detection via Prior-guided Bi-level Representation Learning
Mar 02, 2023



Human object interaction (HOI) detection plays a crucial role in human-centric scene understanding and serves as a fundamental building-block for many vision tasks. One generalizable and scalable strategy for HOI detection is to use weak supervision, learning from image-level annotations only. This is inherently challenging due to ambiguous human-object associations, large search space of detecting HOIs and highly noisy training signal. A promising strategy to address those challenges is to exploit knowledge from large-scale pretrained models (e.g., CLIP), but a direct knowledge distillation strategy~\citep{liao2022gen} does not perform well on the weakly-supervised setting. In contrast, we develop a CLIP-guided HOI representation capable of incorporating the prior knowledge at both image level and HOI instance level, and adopt a self-taught mechanism to prune incorrect human-object associations. Experimental results on HICO-DET and V-COCO show that our method outperforms the previous works by a sizable margin, showing the efficacy of our HOI representation.
Single Image 3D Object Estimation with Primitive Graph Networks
Sep 09, 2021
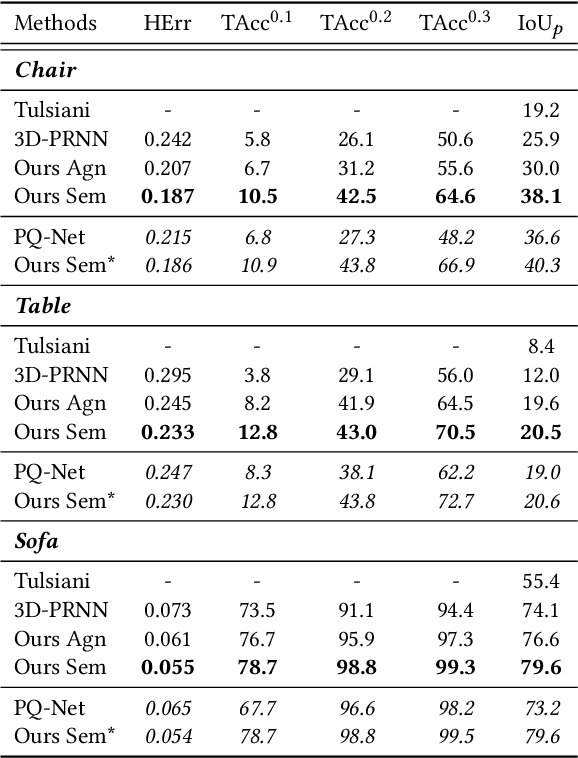
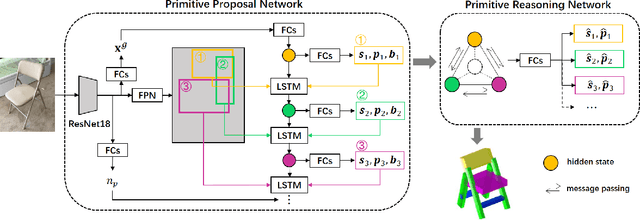
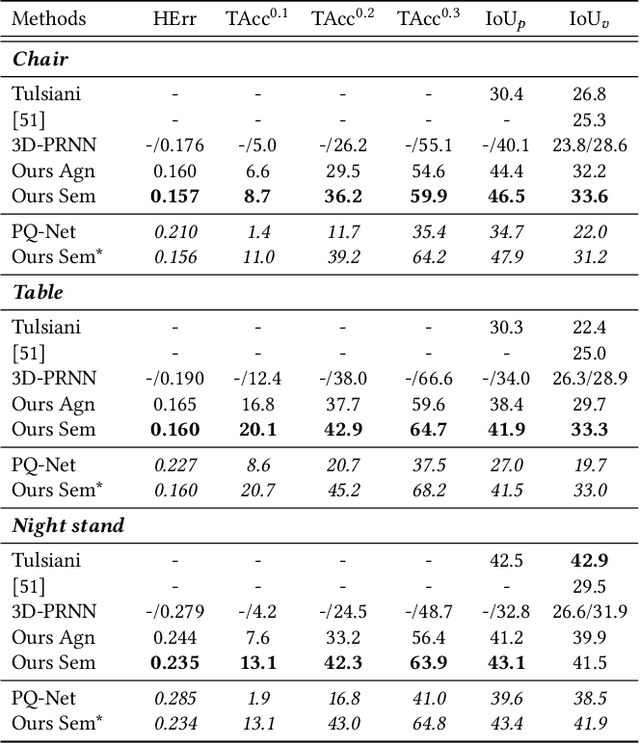
Reconstructing 3D object from a single image (RGB or depth) is a fundamental problem in visual scene understanding and yet remains challenging due to its ill-posed nature and complexity in real-world scenes. To address those challenges, we adopt a primitive-based representation for 3D object, and propose a two-stage graph network for primitive-based 3D object estimation, which consists of a sequential proposal module and a graph reasoning module. Given a 2D image, our proposal module first generates a sequence of 3D primitives from input image with local feature attention. Then the graph reasoning module performs joint reasoning on a primitive graph to capture the global shape context for each primitive. Such a framework is capable of taking into account rich geometry and semantic constraints during 3D structure recovery, producing 3D objects with more coherent structure even under challenging viewing conditions. We train the entire graph neural network in a stage-wise strategy and evaluate it on three benchmarks: Pix3D, ModelNet and NYU Depth V2. Extensive experiments show that our approach outperforms the previous state of the arts with a considerable margin.
Bipartite Graph Network with Adaptive Message Passing for Unbiased Scene Graph Generation
Apr 29, 2021
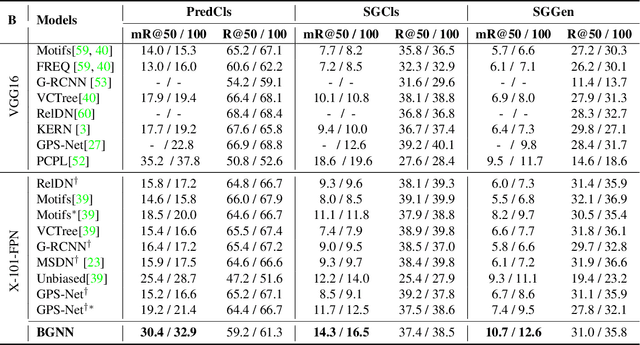
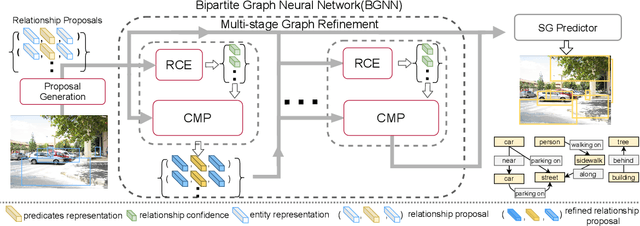
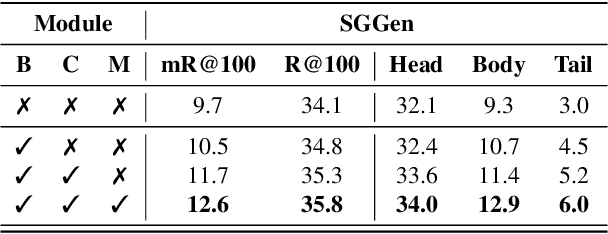
Scene graph generation is an important visual understanding task with a broad range of vision applications. Despite recent tremendous progress, it remains challenging due to the intrinsic long-tailed class distribution and large intra-class variation. To address these issues, we introduce a novel confidence-aware bipartite graph neural network with adaptive message propagation mechanism for unbiased scene graph generation. In addition, we propose an efficient bi-level data resampling strategy to alleviate the imbalanced data distribution problem in training our graph network. Our approach achieves superior or competitive performance over previous methods on several challenging datasets, including Visual Genome, Open Images V4/V6, demonstrating its effectiveness and generality.