 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISTA-Bench: Do Vision-Language Models Really Understand Visualized Text as Well as Pure Text?
Feb 04, 2026Vision-Language Models (VLMs) have achieved impressive performance in cross-modal understanding across textual and visual inputs, yet existing benchmarks predominantly focus on pure-text queries. In real-world scenarios, language also frequently appears as visualized text embedded in images, raising the question of whether current VLMs handle such input requests comparably. We introduce VISTA-Bench, a systematic benchmark from multimodal perception, reasoning, to unimodal understanding domains. It evaluates visualized text understanding by contrasting pure-text and visualized-text questions under controlled rendering conditions. Extensive evaluation of over 20 representative VLMs reveals a pronounced modality gap: models that perform well on pure-text queries often degrade substantially when equivalent semantic content is presented as visualized text. This gap is further amplified by increased perceptual difficulty, highlighting sensitivity to rendering variations despite unchanged semantics. Overall, VISTA-Bench provides a principled evaluation framework to diagnose this limitation and to guide progress toward more unified language representations across tokenized text and pixels. The source dataset is available at https://github.com/QingAnLiu/VISTA-Bench.
Interactive Spatial-Frequency Fusion Mamba for Multi-Modal Image Fusion
Feb 04, 2026Multi-Modal Image Fusion (MMIF) aims to combine images from different modalities to produce fused images, retaining texture details and preserving significant information. Recently, some MMIF methods incorporate frequency domain information to enhance spatial features. However, these methods typically rely on simple serial or parallel spatial-frequency fusion without interaction. In this paper, we propose a novel Interactive Spatial-Frequency Fusion Mamba (ISFM) framework for MMIF. Specifically, we begin with a Modality-Specific Extractor (MSE) to extract features from different modalities. It models long-range dependencies across the image with linear computational complexity. To effectively leverage frequency information, we then propose a Multi-scale Frequency Fusion (MFF). It adaptively integrates low-frequency and high-frequency components across multiple scales, enabling robust representations of frequency features. More importantly, we further propose an Interactive Spatial-Frequency Fusion (ISF). It incorporates frequency features to guide spatial features across modalities, enhancing complementary representations. Extensive experiments are conducted on six MMIF datasets. The experimental results demonstrate that our ISFM can achieve better performances than other state-of-the-art methods. The source code is available at https://github.com/Namn23/ISFM.
Think3D: Thinking with Space for Spatial Reasoning
Jan 19, 2026Understanding and reasoning about the physical world requires spatial intelligence: the ability to interpret geometry, perspective, and spatial relations beyond 2D perception. While recent vision large models (VLMs) excel at visual understanding, they remain fundamentally 2D perceivers and struggle with genuine 3D reasoning. We introduce Think3D, a framework that enables VLM agents to think with 3D space. By leveraging 3D reconstruction models that recover point clouds and camera poses from images or videos, Think3D allows the agent to actively manipulate space through camera-based operations and ego/global-view switching, transforming spatial reasoning into an interactive 3D chain-of-thought process. Without additional training, Think3D significantly improves the spatial reasoning performance of advanced models such as GPT-4.1 and Gemini 2.5 Pro, yielding average gains of +7.8% on BLINK Multi-view and MindCube, and +4.7% on VSI-Bench. We further show that smaller models, which struggle with spatial exploration, benefit significantly from a reinforcement learning policy that enables the model to select informative viewpoints and operations. With RL, the benefit from tool usage increases from +0.7% to +6.8%. Our findings demonstrate that training-free, tool-augmented spatial exploration is a viable path toward more flexible and human-like 3D reasoning in multimodal agents, establishing a new dimension of multimodal intelligence. Code and weights are released at https://github.com/zhangzaibin/spagent.
Towards Cross-Platform Generalization: Domain Adaptive 3D Detection with Augmentation and Pseudo-Labeling
Jan 13, 2026This technical report represents the award-winning solution to the Cross-platform 3D Object Detection task in the RoboSense2025 Challenge. Our approach is built upon PVRCNN++, an efficient 3D object detection framework that effectively integrates point-based and voxel-based features. On top of this foundation, we improve cross-platform generalization by narrowing domain gaps through tailored data augmentation and a self-training strategy with pseudo-labels. These enhancements enabled our approach to secure the 3rd place in the challenge, achieving a 3D AP of 62.67% for the Car category on the phase-1 target domain, and 58.76% and 49.81% for Car and Pedestrian categories respectively on the phase-2 target domain.
The RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
AR-MOT: Autoregressive Multi-object Tracking
Jan 05, 2026As multi-object tracking (MOT) tasks continue to evolve toward more general and multi-modal scenarios, the rigid and task-specific architectures of existing MOT methods increasingly hinder their applicability across diverse tasks and limit flexibility in adapting to new tracking formulations. Most approaches rely on fixed output heads and bespoke tracking pipelines, making them difficult to extend to more complex or instruction-driven tasks. To address these limitations, we propose AR-MOT, a novel autoregressive paradigm that formulates MOT as a sequence generation task within a large language model (LLM) framework. This design enables the model to output structured results through flexible sequence construction, without requiring any task-specific heads. To enhance region-level visual perception, we introduce an Object Tokenizer based on a pretrained detector. To mitigate the misalignment between global and regional features, we propose a Region-Aware Alignment (RAA) module, and to support long-term tracking, we design a Temporal Memory Fusion (TMF) module that caches historical object tokens. AR-MOT offers strong potential for extensibility, as new modalities or instructions can be integrated by simply modifying the output sequence format without altering the model architecture. Extensive experiments on MOT17 and DanceTrack validate the feasibility of our approach, achieving performance comparable to state-of-the-art methods while laying the foundation for more general and flexible MOT systems.
Utilizing Earth Foundation Models to Enhance the Simulation Performance of Hydrological Models with AlphaEarth Embeddings
Jan 04, 2026Predicting river flow in places without streamflow records is challenging because basins respond differently to climate, terrain, vegetation, and soils. Traditional basin attributes describe some of these differences, but they cannot fully represent the complexity of natural environments. This study examines whether AlphaEarth Foundation embeddings, which are learned from large collections of satellite images rather than designed by experts, offer a more informative way to describe basin characteristics. These embeddings summarize patterns in vegetation, land surface properties, and long-term environmental dynamics. We find that models using them achieve higher accuracy when predicting flows in basins not used for training, suggesting that they capture key physical differences more effectively than traditional attributes. We further investigate how selecting appropriate donor basins influences prediction in ungauged regions. Similarity based on the embeddings helps identify basins with comparable environmental and hydrological behavior, improving performance, whereas adding many dissimilar basins can reduce accuracy. The results show that satellite-informed environmental representations can strengthen hydrological forecasting and support the development of models that adapt more easily to different landscapes.
Living the Novel: A System for Generating Self-Training Timeline-Aware Conversational Agents from Novels
Dec 08, 2025



We present the Living Novel, an end-to-end system that transforms any literary work into an immersive, multi-character conversational experience. This system is designed to solve two fundamental challenges for LLM-driven characters. Firstly, generic LLMs suffer from persona drift, often failing to stay in character. Secondly, agents often exhibit abilities that extend beyond the constraints of the story's world and logic, leading to both narrative incoherence (spoiler leakage) and robustness failures (frame-breaking). To address these challenges, we introduce a novel two-stage training pipeline. Our Deep Persona Alignment (DPA) stage uses data-free reinforcement finetuning to instill deep character fidelity. Our Coherence and Robustness Enhancing (CRE) stage then employs a story-time-aware knowledge graph and a second retrieval-grounded training pass to architecturally enforce these narrative constraints. We validate our system through a multi-phase evaluation using Jules Verne's Twenty Thousand Leagues Under the Sea. A lab study with a detailed ablation of system components is followed by a 5-day in-the-wild diary study. Our DPA pipeline helps our specialized model outperform GPT-4o on persona-specific metrics, and our CRE stage achieves near-perfect performance in coherence and robustness measures. Our study surfaces practical design guidelines for AI-driven narrative systems: we find that character-first self-training is foundational for believability, while explicit story-time constraints are crucial for sustaining coherent, interruption-resilient mobile-web experiences.
Parameter Aware Mamba Model for Multi-task Dense Prediction
Nov 18, 2025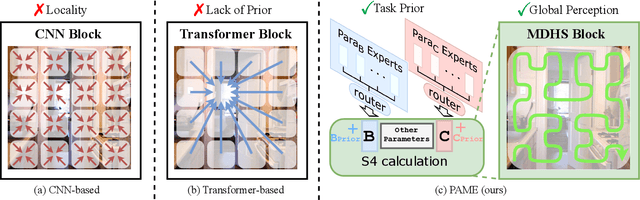
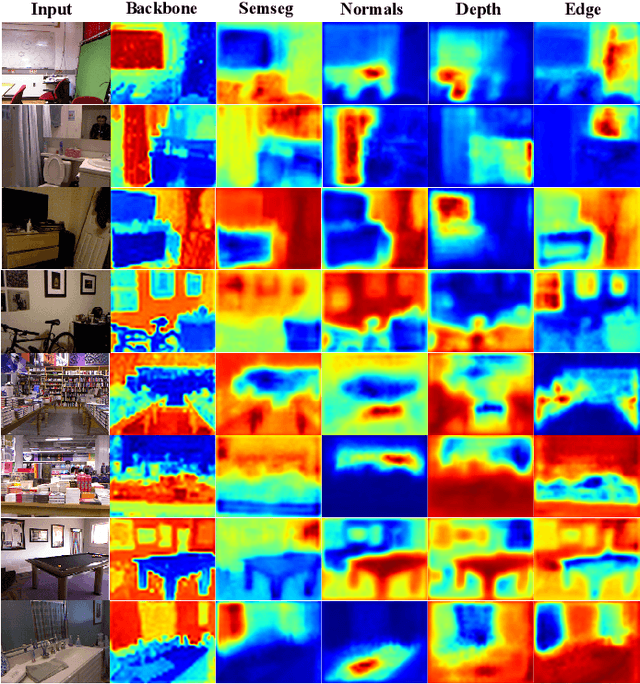
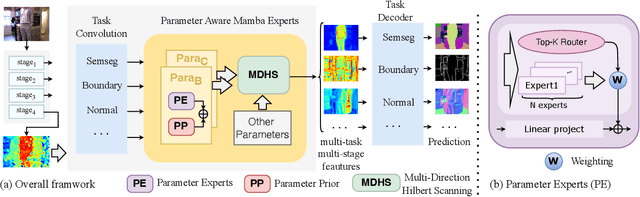
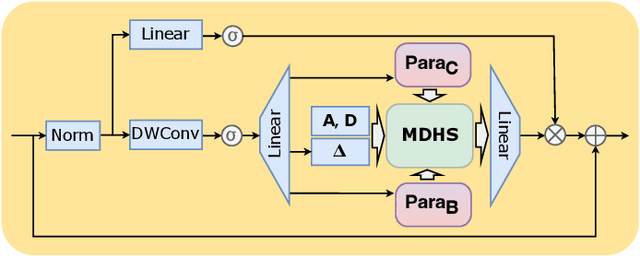
Understanding the inter-relations and interactions between tasks is crucial for multi-task dense prediction. Existing methods predominantly utilize convolutional layers and attention mechanisms to explore task-level interactions. In this work, we introduce a novel decoder-based framework, Parameter Aware Mamba Model (PAMM), specifically designed for dense prediction in multi-task learning setting. Distinct from approaches that employ Transformers to model holistic task relationships, PAMM leverages the rich, scalable parameters of state space models to enhance task interconnectivity. It features dual state space parameter experts that integrate and set task-specific parameter priors, capturing the intrinsic properties of each task. This approach not only facilitates precise multi-task interactions but also allows for the global integration of task priors through the structured state space sequence model (S4). Furthermore, we employ the Multi-Directional Hilbert Scanning method to construct multi-angle feature sequences, thereby enhancing the sequence model's perceptual capabilities for 2D data. Extensive experiments on the NYUD-v2 and PASCAL-Context benchmarks demonstrate the effectiveness of our proposed method. Our code is available at https://github.com/CQC-gogopro/PAMM.
Spatial-Frequency Enhanced Mamba for Multi-Modal Image Fusion
Nov 10, 2025Multi-Modal Image Fusion (MMIF) aims to integrate complementary image information from different modalities to produce informative images. Previous deep learning-based MMIF methods generally adopt Convolutional Neural Networks (CNNs) or Transformers for feature extraction. However, these methods deliver unsatisfactory performances due to the limited receptive field of CNNs and the high computational cost of Transformers. Recently, Mamba has demonstrated a powerful potential for modeling long-range dependencies with linear complexity, providing a promising solution to MMIF. Unfortunately, Mamba lacks full spatial and frequency perceptions, which are very important for MMIF. Moreover, employing Image Reconstruction (IR) as an auxiliary task has been proven beneficial for MMIF. However, a primary challenge is how to leverage IR efficiently and effectively. To address the above issues, we propose a novel framework named Spatial-Frequency Enhanced Mamba Fusion (SFMFusion) for MMIF. More specifically, we first propose a three-branch structure to couple MMIF and IR, which can retain complete contents from source images. Then, we propose the Spatial-Frequency Enhanced Mamba Block (SFMB), which can enhance Mamba in both spatial and frequency domains for comprehensive feature extraction. Finally, we propose the Dynamic Fusion Mamba Block (DFMB), which can be deployed across different branches for dynamic feature fusion. Extensive experiments show that our method achieves better results than most state-of-the-art methods on six MMIF datasets. The source code is available at https://github.com/SunHui1216/SFMFusion.