 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmu3.5: Native Multimodal Models are World Learners
Oct 30, 2025We introduce Emu3.5, a large-scale multimodal world model that natively predicts the next state across vision and language. Emu3.5 is pre-trained end-to-end with a unified next-token prediction objective on a corpus of vision-language interleaved data containing over 10 trillion tokens, primarily derived from sequential frames and transcripts of internet videos. The model naturally accepts interleaved vision-language inputs and generates interleaved vision-language outputs. Emu3.5 is further post-trained with large-scale reinforcement learning to enhance multimodal reasoning and generation. To improve inference efficiency, we propose Discrete Diffusion Adaptation (DiDA), which converts token-by-token decoding into bidirectional parallel prediction, accelerating per-image inference by about 20x without sacrificing performance. Emu3.5 exhibits strong native multimodal capabilities, including long-horizon vision-language generation, any-to-image (X2I) generation, and complex text-rich image generation. It also exhibits generalizable world-modeling abilities, enabling spatiotemporally consistent world exploration and open-world embodied manipulation across diverse scenarios and tasks. For comparison, Emu3.5 achieves performance comparable to Gemini 2.5 Flash Image (Nano Banana) on image generation and editing tasks and demonstrates superior results on a suite of interleaved generation tasks. We open-source Emu3.5 at https://github.com/baaivision/Emu3.5 to support community research.
End-to-End Vision Tokenizer Tuning
May 15, 2025Existing vision tokenization isolates the optimization of vision tokenizers from downstream training, implicitly assuming the visual tokens can generalize well across various tasks, e.g., image generation and visual question answering. The vision tokenizer optimized for low-level reconstruction is agnostic to downstream tasks requiring varied representations and semantics. This decoupled paradigm introduces a critical misalignment: The loss of the vision tokenization can be the representation bottleneck for target tasks. For example, errors in tokenizing text in a given image lead to poor results when recognizing or generating them. To address this, we propose ETT, an end-to-end vision tokenizer tuning approach that enables joint optimization between vision tokenization and target autoregressive tasks. Unlike prior autoregressive models that use only discrete indices from a frozen vision tokenizer, ETT leverages the visual embeddings of the tokenizer codebook, and optimizes the vision tokenizers end-to-end with both reconstruction and caption objectives. ETT can be seamlessly integrated into existing training pipelines with minimal architecture modifications. Our ETT is simple to implement and integrate, without the need to adjust the original codebooks or architectures of the employed large language models. Extensive experiments demonstrate that our proposed end-to-end vision tokenizer tuning unlocks significant performance gains, i.e., 2-6% for multimodal understanding and visual generation tasks compared to frozen tokenizer baselines, while preserving the original reconstruction capability. We hope this very simple and strong method can empower multimodal foundation models besides image generation and understanding.
EVEv2: Improved Baselines for Encoder-Free Vision-Language Models
Feb 10, 2025



Existing encoder-free vision-language models (VLMs) are rapidly narrowing the performance gap with their encoder-based counterparts, highlighting the promising potential for unified multimodal systems with structural simplicity and efficient deployment. We systematically clarify the performance gap between VLMs using pre-trained vision encoders, discrete tokenizers, and minimalist visual layers from scratch, deeply excavating the under-examined characteristics of encoder-free VLMs. We develop efficient strategies for encoder-free VLMs that rival mainstream encoder-based ones. After an in-depth investigation, we launch EVEv2.0, a new and improved family of encoder-free VLMs. We show that: (i) Properly decomposing and hierarchically associating vision and language within a unified model reduces interference between modalities. (ii) A well-designed training strategy enables effective optimization for encoder-free VLMs. Through extensive evaluation, our EVEv2.0 represents a thorough study for developing a decoder-only architecture across modalities, demonstrating superior data efficiency and strong vision-reasoning capability. Code is publicly available at: https://github.com/baaivision/EVE.
Autoregressive Video Generation without Vector Quantization
Dec 18, 2024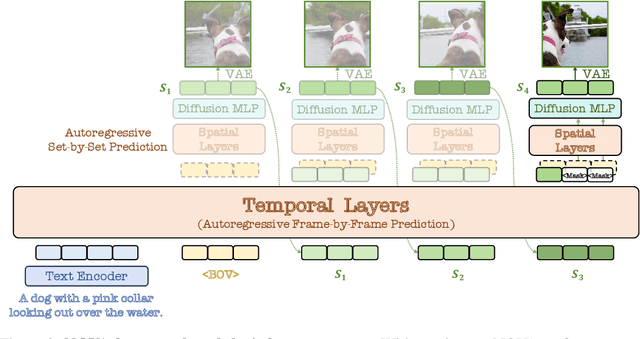
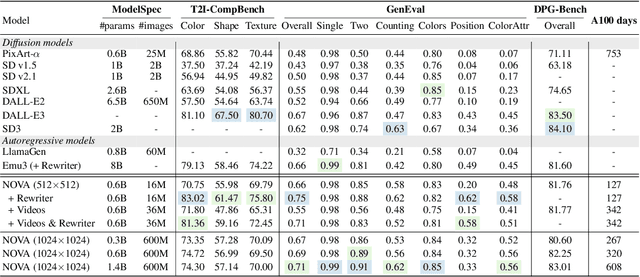
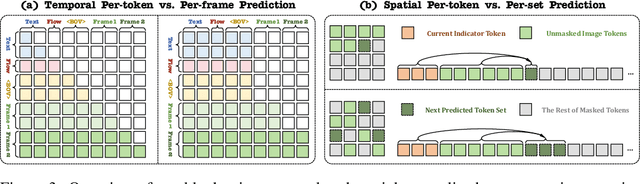
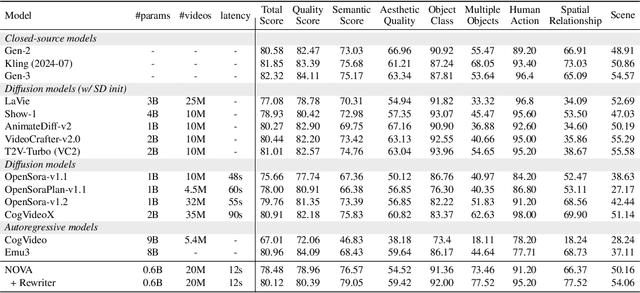
This paper presents a novel approach that enables autoregressive video generation with high efficiency. We propose to reformulate the video generation problem as a non-quantized autoregressive modeling of temporal frame-by-frame prediction and spatial set-by-set prediction. Unlike raster-scan prediction in prior autoregressive models or joint distribution modeling of fixed-length tokens in diffusion models, our approach maintains the causal property of GPT-style models for flexible in-context capabilities, while leveraging bidirectional modeling within individual frames for efficiency. With the proposed approach, we train a novel video autoregressive model without vector quantization, termed NOVA. Our results demonstrate that NOVA surpasses prior autoregressive video models in data efficiency, inference speed, visual fidelity, and video fluency, even with a much smaller model capacity, i.e., 0.6B parameters. NOVA also outperforms state-of-the-art image diffusion models in text-to-image generation tasks, with a significantly lower training cost. Additionally, NOVA generalizes well across extended video durations and enables diverse zero-shot applications in one unified model. Code and models are publicly available at https://github.com/baaivision/NOVA.
Emu3: Next-Token Prediction is All You Need
Sep 27, 2024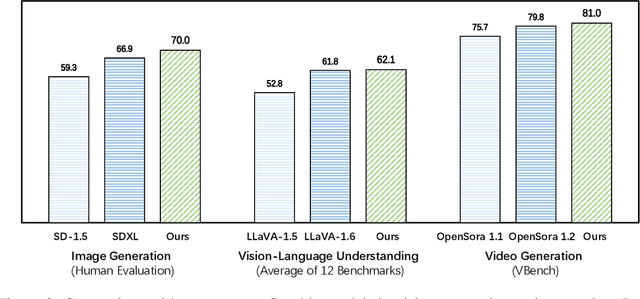


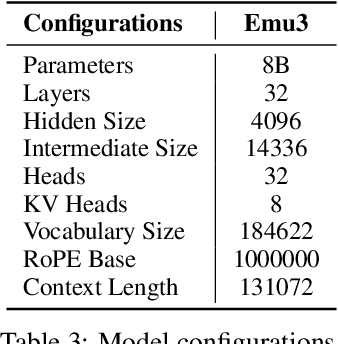
While next-token prediction is considered a promising path towards artificial general intelligence, it has struggled to excel in multimodal tasks, which are still dominated by diffusion models (e.g., Stable Diffusion) and compositional approaches (e.g., CLIP combined with LLMs). In this paper, we introduce Emu3, a new suite of state-of-the-art multimodal models trained solely with next-token prediction. By tokenizing images, text, and videos into a discrete space, we train a single transformer from scratch on a mixture of multimodal sequences. Emu3 outperforms several well-established task-specific models in both generation and perception tasks, surpassing flagship models such as SDXL and LLaVA-1.6, while eliminating the need for diffusion or compositional architectures. Emu3 is also capable of generating high-fidelity video via predicting the next token in a video sequence. We simplify complex multimodal model designs by converging on a singular focus: tokens, unlocking great potential for scaling both during training and inference. Our results demonstrate that next-token prediction is a promising path towards building general multimodal intelligence beyond language. We open-source key techniques and models to support further research in this direction.
Unveiling Encoder-Free Vision-Language Models
Jun 17, 2024Existing vision-language models (VLMs) mostly rely on vision encoders to extract visual features followed by large language models (LLMs) for visual-language tasks. However, the vision encoders set a strong inductive bias in abstracting visual representation, e.g., resolution, aspect ratio, and semantic priors, which could impede the flexibility and efficiency of the VLMs. Training pure VLMs that accept the seamless vision and language inputs, i.e., without vision encoders, remains challenging and rarely explored. Empirical observations reveal that direct training without encoders results in slow convergence and large performance gaps. In this work, we bridge the gap between encoder-based and encoder-free models, and present a simple yet effective training recipe towards pure VLMs. Specifically, we unveil the key aspects of training encoder-free VLMs efficiently via thorough experiments: (1) Bridging vision-language representation inside one unified decoder; (2) Enhancing visual recognition capability via extra supervision. With these strategies, we launch EVE, an encoder-free vision-language model that can be trained and forwarded efficiently. Notably, solely utilizing 35M publicly accessible data, EVE can impressively rival the encoder-based VLMs of similar capacities across multiple vision-language benchmarks. It significantly outperforms the counterpart Fuyu-8B with mysterious training procedures and undisclosed training data. We believe that EVE provides a transparent and efficient route for developing a pure decoder-only architecture across modalities. Our code and models are publicly available at: https://github.com/baaivision/EVE.
EVA-CLIP-18B: Scaling CLIP to 18 Billion Parameters
Feb 06, 2024



Scaling up contrastive language-image pretraining (CLIP) is critical for empowering both vision and multimodal models. We present EVA-CLIP-18B, the largest and most powerful open-source CLIP model to date, with 18-billion parameters. With only 6-billion training samples seen, EVA-CLIP-18B achieves an exceptional 80.7% zero-shot top-1 accuracy averaged across 27 widely recognized image classification benchmarks, outperforming its forerunner EVA-CLIP (5-billion parameters) and other open-source CLIP models by a large margin. Remarkably, we observe a consistent performance improvement with the model size scaling of EVA-CLIP, despite maintaining a constant training dataset of 2-billion image-text pairs from LAION-2B and COYO-700M. This dataset is openly available and much smaller than the in-house datasets (e.g., DFN-5B, WebLI-10B) employed in other state-of-the-art CLIP models. EVA-CLIP-18B demonstrates the potential of EVA-style weak-to-strong visual model scaling. With our model weights made publicly available, we hope to facilitate future research in vision and multimodal foundation models.
Generative Multimodal Models are In-Context Learners
Dec 20, 2023The human ability to easily solve multimodal tasks in context (i.e., with only a few demonstrations or simple instructions), is what current multimodal systems have largely struggled to imitate. In this work, we demonstrate that the task-agnostic in-context learning capabilities of large multimodal models can be significantly enhanced by effective scaling-up. We introduce Emu2, a generative multimodal model with 37 billion parameters, trained on large-scale multimodal sequences with a unified autoregressive objective. Emu2 exhibits strong multimodal in-context learning abilities, even emerging to solve tasks that require on-the-fly reasoning, such as visual prompting and object-grounded generation. The model sets a new record on multiple multimodal understanding tasks in few-shot settings. When instruction-tuned to follow specific instructions, Emu2 further achieves new state-of-the-art on challenging tasks such as question answering benchmarks for large multimodal models and open-ended subject-driven generation. These achievements demonstrate that Emu2 can serve as a base model and general-purpose interface for a wide range of multimodal tasks. Code and models are publicly available to facilitate future research.
CapsFusion: Rethinking Image-Text Data at Scale
Nov 02, 2023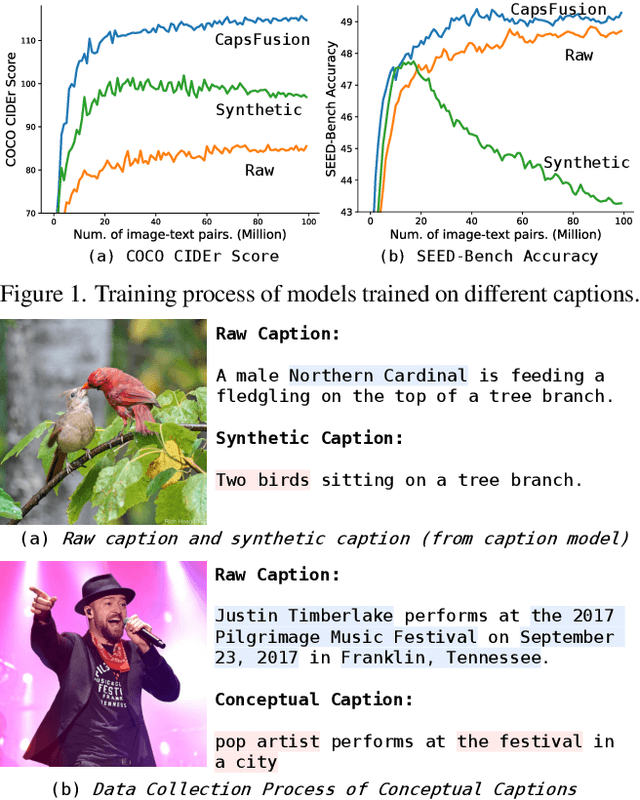
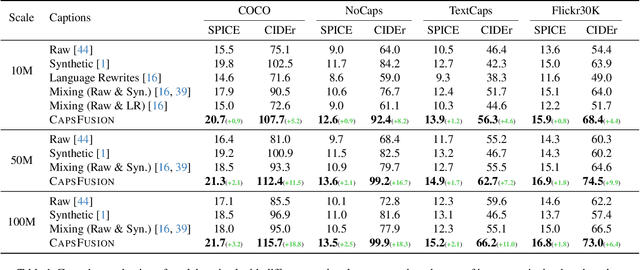


Large multimodal models demonstrate remarkable generalist ability to perform diverse multimodal tasks in a zero-shot manner. Large-scale web-based image-text pairs contribute fundamentally to this success, but suffer from excessive noise. Recent studies use alternative captions synthesized by captioning models and have achieved notable benchmark performance. However, our experiments reveal significant Scalability Deficiency and World Knowledge Loss issues in models trained with synthetic captions, which have been largely obscured by their initial benchmark success. Upon closer examination, we identify the root cause as the overly-simplified language structure and lack of knowledge details in existing synthetic captions. To provide higher-quality and more scalable multimodal pretraining data, we propose CapsFusion, an advanced framework that leverages large language models to consolidate and refine information from both web-based image-text pairs and synthetic captions. Extensive experiments show that CapsFusion captions exhibit remarkable all-round superiority over existing captions in terms of model performance (e.g., 18.8 and 18.3 improvements in CIDEr score on COCO and NoCaps), sample efficiency (requiring 11-16 times less computation than baselines), world knowledge depth, and scalability. These effectiveness, efficiency and scalability advantages position CapsFusion as a promising candidate for future scaling of LMM training.
Generative Pretraining in Multimodality
Jul 11, 2023We present Emu, a Transformer-based multimodal foundation model, which can seamlessly generate images and texts in multimodal context. This omnivore model can take in any single-modality or multimodal data input indiscriminately (e.g., interleaved image, text and video) through a one-model-for-all autoregressive training process. First, visual signals are encoded into embeddings, and together with text tokens form an interleaved input sequence. Emu is then end-to-end trained with a unified objective of classifying the next text token or regressing the next visual embedding in the multimodal sequence. This versatile multimodality empowers the exploration of diverse pretraining data sources at scale, such as videos with interleaved frames and text, webpages with interleaved images and text, as well as web-scale image-text pairs and video-text pairs. Emu can serve as a generalist multimodal interface for both image-to-text and text-to-image tasks, and supports in-context image and text generation. Across a broad range of zero-shot/few-shot tasks including image captioning, visual question answering, video question answering and text-to-image generation, Emu demonstrates superb performance compared to state-of-the-art large multimodal models. Extended capabilities such as multimodal assistants via instruction tuning are also demonstrated with impressive performance.