 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCached Multi-Lora Composition for Multi-Concept Image Generation
Feb 07, 2025Low-Rank Adaptation (LoRA) has emerged as a widely adopted technique in text-to-image models, enabling precise rendering of multiple distinct elements, such as characters and styles, in multi-concept image generation. However, current approaches face significant challenges when composing these LoRAs for multi-concept image generation, resulting in diminished generated image quality. In this paper, we initially investigate the role of LoRAs in the denoising process through the lens of the Fourier frequency domain. Based on the hypothesis that applying multiple LoRAs could lead to "semantic conflicts", we find that certain LoRAs amplify high-frequency features such as edges and textures, whereas others mainly focus on low-frequency elements, including the overall structure and smooth color gradients. Building on these insights, we devise a frequency domain based sequencing strategy to determine the optimal order in which LoRAs should be integrated during inference. This strategy offers a methodical and generalizable solution compared to the naive integration commonly found in existing LoRA fusion techniques. To fully leverage our proposed LoRA order sequence determination method in multi-LoRA composition tasks, we introduce a novel, training-free framework, Cached Multi-LoRA (CMLoRA), designed to efficiently integrate multiple LoRAs while maintaining cohesive image generation. With its flexible backbone for multi-LoRA fusion and a non-uniform caching strategy tailored to individual LoRAs, CMLoRA has the potential to reduce semantic conflicts in LoRA composition and improve computational efficiency. Our experimental evaluations demonstrate that CMLoRA outperforms state-of-the-art training-free LoRA fusion methods by a significant margin -- it achieves an average improvement of $2.19\%$ in CLIPScore, and $11.25\%$ in MLLM win rate compared to LoraHub, LoRA Composite, and LoRA Switch.
$Δ$-DiT: A Training-Free Acceleration Method Tailored for Diffusion Transformers
Jun 03, 2024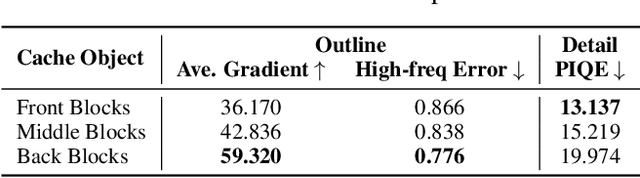
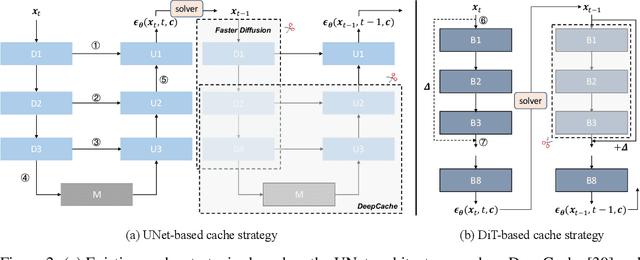

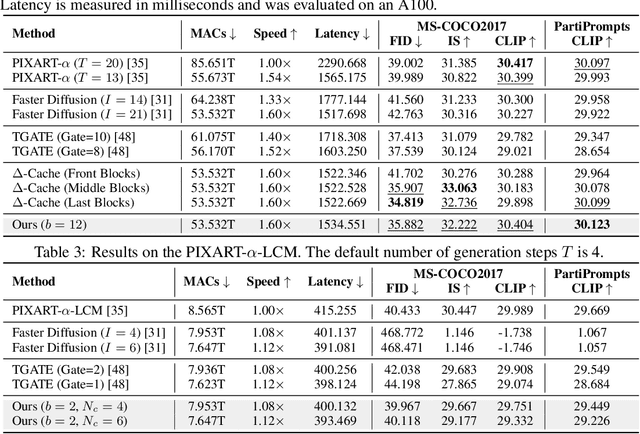
Diffusion models are widely recognized for generating high-quality and diverse images, but their poor real-time performance has led to numerous acceleration works, primarily focusing on UNet-based structures. With the more successful results achieved by diffusion transformers (DiT), there is still a lack of exploration regarding the impact of DiT structure on generation, as well as the absence of an acceleration framework tailored to the DiT architecture. To tackle these challenges, we conduct an investigation into the correlation between DiT blocks and image generation. Our findings reveal that the front blocks of DiT are associated with the outline of the generated images, while the rear blocks are linked to the details. Based on this insight, we propose an overall training-free inference acceleration framework $\Delta$-DiT: using a designed cache mechanism to accelerate the rear DiT blocks in the early sampling stages and the front DiT blocks in the later stages. Specifically, a DiT-specific cache mechanism called $\Delta$-Cache is proposed, which considers the inputs of the previous sampling image and reduces the bias in the inference. Extensive experiments on PIXART-$\alpha$ and DiT-XL demonstrate that the $\Delta$-DiT can achieve a $1.6\times$ speedup on the 20-step generation and even improves performance in most cases. In the scenario of 4-step consistent model generation and the more challenging $1.12\times$ acceleration, our method significantly outperforms existing methods. Our code will be publicly available.
Enhancing Real-World Complex Network Representations with Hyperedge Augmentation
Feb 20, 2024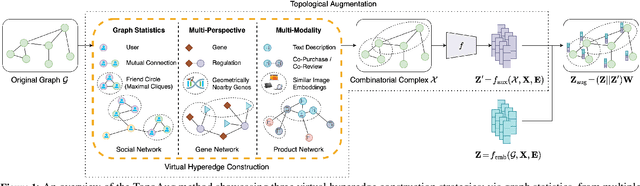
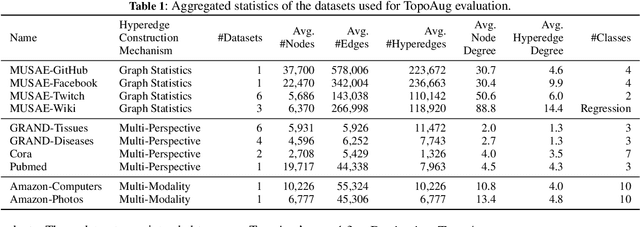
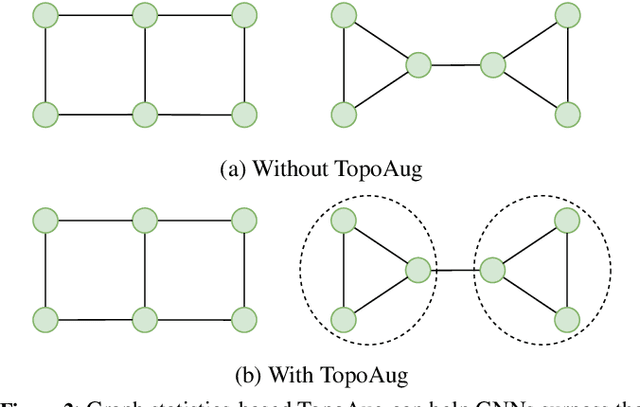
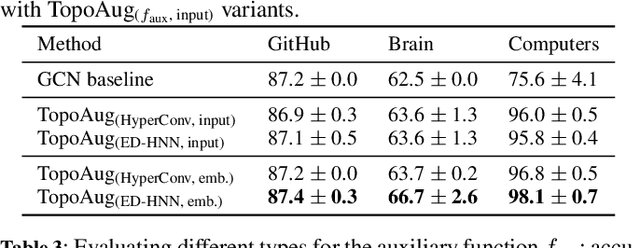
Graph augmentation methods play a crucial role in improving the performance and enhancing generalisation capabilities in Graph Neural Networks (GNNs). Existing graph augmentation methods mainly perturb the graph structures and are usually limited to pairwise node relations. These methods cannot fully address the complexities of real-world large-scale networks that often involve higher-order node relations beyond only being pairwise. Meanwhile, real-world graph datasets are predominantly modelled as simple graphs, due to the scarcity of data that can be used to form higher-order edges. Therefore, reconfiguring the higher-order edges as an integration into graph augmentation strategies lights up a promising research path to address the aforementioned issues. In this paper, we present Hyperedge Augmentation (HyperAug), a novel graph augmentation method that constructs virtual hyperedges directly form the raw data, and produces auxiliary node features by extracting from the virtual hyperedge information, which are used for enhancing GNN performances on downstream tasks. We design three diverse virtual hyperedge construction strategies to accompany the augmentation scheme: (1) via graph statistics, (2) from multiple data perspectives, and (3) utilising multi-modality. Furthermore, to facilitate HyperAug evaluation, we provide 23 novel real-world graph datasets across various domains including social media, biology, and e-commerce. Our empirical study shows that HyperAug consistently and significantly outperforms GNN baselines and other graph augmentation methods, across a variety of application contexts, which clearly indicates that it can effectively incorporate higher-order node relations into graph augmentation methods for real-world complex networks.
Merging Vision Transformers from Different Tasks and Domains
Dec 25, 2023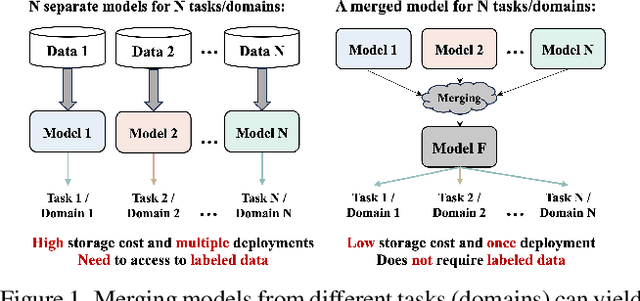

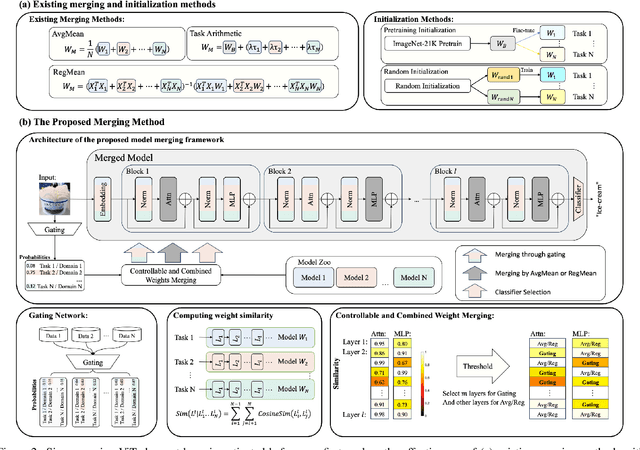
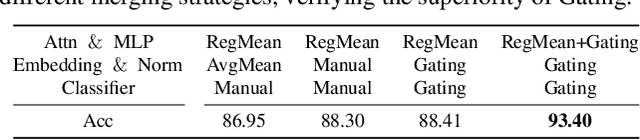
This work targets to merge various Vision Transformers (ViTs) trained on different tasks (i.e., datasets with different object categories) or domains (i.e., datasets with the same categories but different environments) into one unified model, yielding still good performance on each task or domain. Previous model merging works focus on either CNNs or NLP models, leaving the ViTs merging research untouched. To fill this gap, we first explore and find that existing model merging methods cannot well handle the merging of the whole ViT models and still have improvement space. To enable the merging of the whole ViT, we propose a simple-but-effective gating network that can both merge all kinds of layers (e.g., Embedding, Norm, Attention, and MLP) and select the suitable classifier. Specifically, the gating network is trained by unlabeled datasets from all the tasks (domains), and predicts the probability of which task (domain) the input belongs to for merging the models during inference. To further boost the performance of the merged model, especially when the difficulty of merging tasks increases, we design a novel metric of model weight similarity, and utilize it to realize controllable and combined weight merging. Comprehensive experiments on kinds of newly established benchmarks, validate the superiority of the proposed ViT merging framework for different tasks and domains. Our method can even merge beyond 10 ViT models from different vision tasks with a negligible effect on the performance of each task.
Hybrid Graph: A Unified Graph Representation with Datasets and Benchmarks for Complex Graphs
Jun 08, 2023
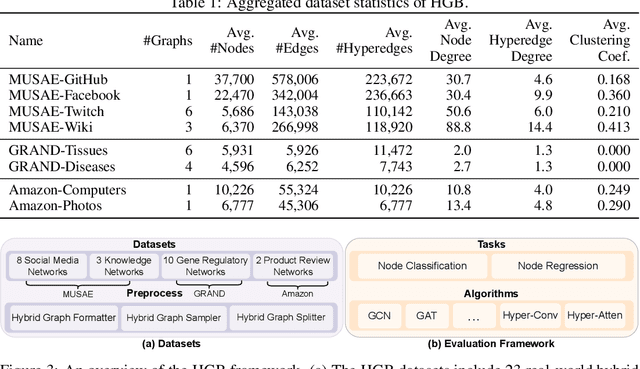
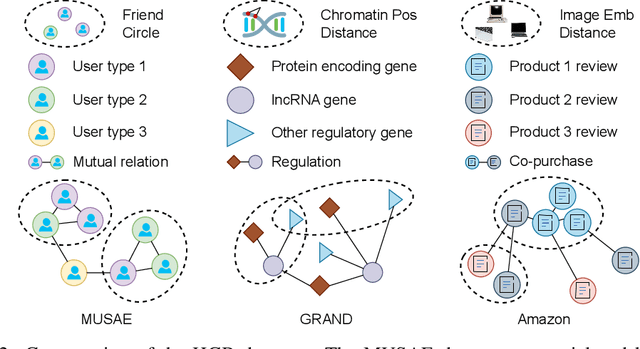
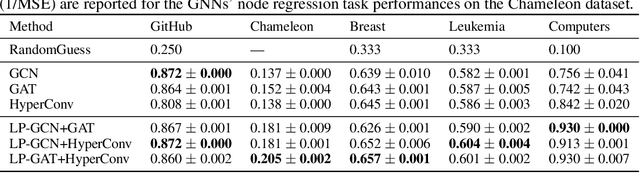
Graphs are widely used to encapsulate a variety of data formats, but real-world networks often involve complex node relations beyond only being pairwise. While hypergraphs and hierarchical graphs have been developed and employed to account for the complex node relations, they cannot fully represent these complexities in practice. Additionally, though many Graph Neural Networks (GNNs) have been proposed for representation learning on higher-order graphs, they are usually only evaluated on simple graph datasets. Therefore, there is a need for a unified modelling of higher-order graphs, and a collection of comprehensive datasets with an accessible evaluation framework to fully understand the performance of these algorithms on complex graphs. In this paper, we introduce the concept of hybrid graphs, a unified definition for higher-order graphs, and present the Hybrid Graph Benchmark (HGB). HGB contains 23 real-world hybrid graph datasets across various domains such as biology, social media, and e-commerce. Furthermore, we provide an extensible evaluation framework and a supporting codebase to facilitate the training and evaluation of GNNs on HGB. Our empirical study of existing GNNs on HGB reveals various research opportunities and gaps, including (1) evaluating the actual performance improvement of hypergraph GNNs over simple graph GNNs; (2) comparing the impact of different sampling strategies on hybrid graph learning methods; and (3) exploring ways to integrate simple graph and hypergraph information. We make our source code and full datasets publicly available at https://zehui127.github.io/hybrid-graph-benchmark/.
Fast-BEV: A Fast and Strong Bird's-Eye View Perception Baseline
Jan 29, 2023
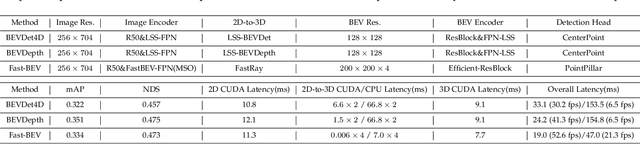
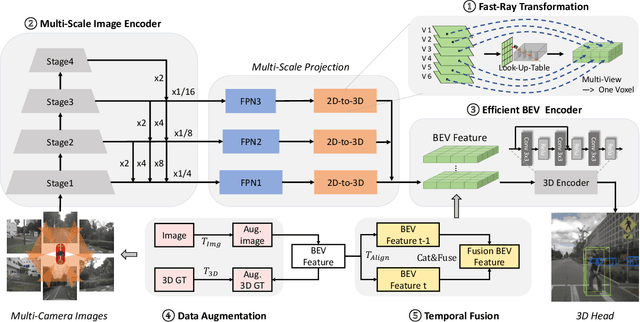
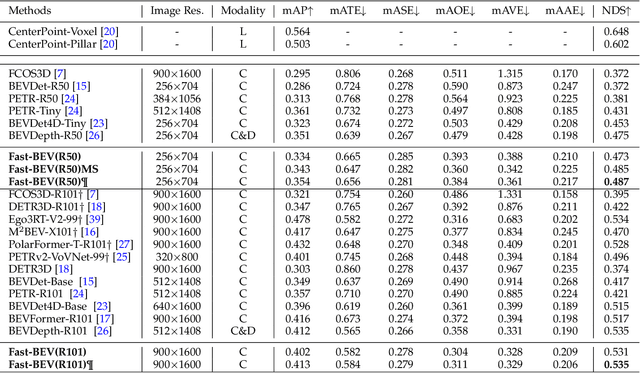
Recently, perception task based on Bird's-Eye View (BEV) representation has drawn more and more attention, and BEV representation is promising as the foundation for next-generation Autonomous Vehicle (AV) perception. However, most existing BEV solutions either require considerable resources to execute on-vehicle inference or suffer from modest performance. This paper proposes a simple yet effective framework, termed Fast-BEV , which is capable of performing faster BEV perception on the on-vehicle chips. Towards this goal, we first empirically find that the BEV representation can be sufficiently powerful without expensive transformer based transformation nor depth representation. Our Fast-BEV consists of five parts, We novelly propose (1) a lightweight deployment-friendly view transformation which fast transfers 2D image feature to 3D voxel space, (2) an multi-scale image encoder which leverages multi-scale information for better performance, (3) an efficient BEV encoder which is particularly designed to speed up on-vehicle inference. We further introduce (4) a strong data augmentation strategy for both image and BEV space to avoid over-fitting, (5) a multi-frame feature fusion mechanism to leverage the temporal information. Through experiments, on 2080Ti platform, our R50 model can run 52.6 FPS with 47.3% NDS on the nuScenes validation set, exceeding the 41.3 FPS and 47.5% NDS of the BEVDepth-R50 model and 30.2 FPS and 45.7% NDS of the BEVDet4D-R50 model. Our largest model (R101@900x1600) establishes a competitive 53.5% NDS on the nuScenes validation set. We further develop a benchmark with considerable accuracy and efficiency on current popular on-vehicle chips. The code is released at: https://github.com/Sense-GVT/Fast-BEV.
Fast-BEV: Towards Real-time On-vehicle Bird's-Eye View Perception
Jan 19, 2023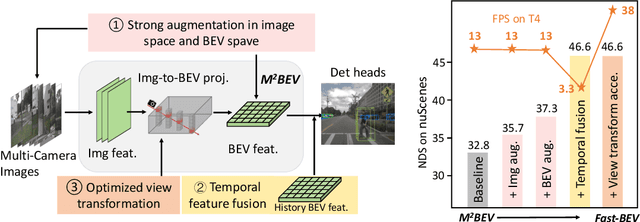
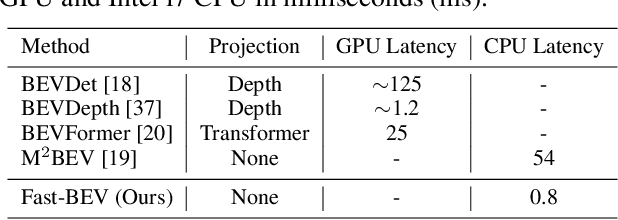
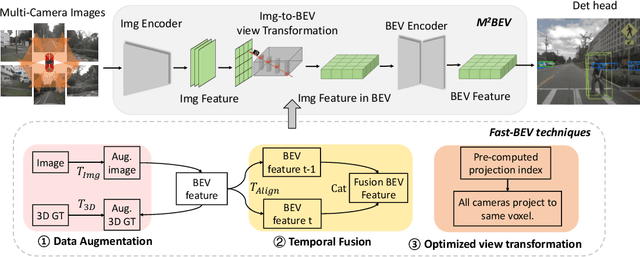
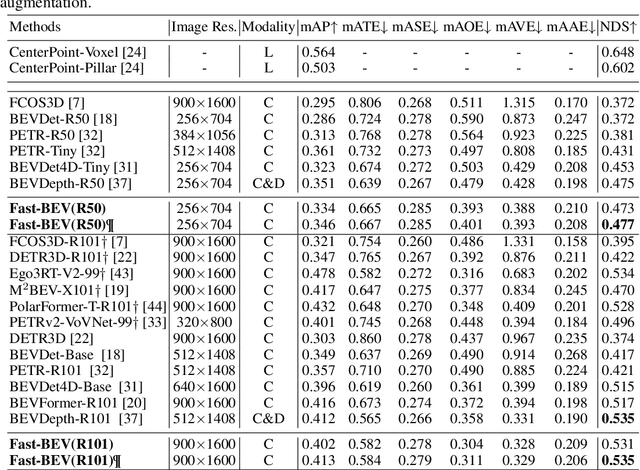
Recently, the pure camera-based Bird's-Eye-View (BEV) perception removes expensive Lidar sensors, making it a feasible solution for economical autonomous driving. However, most existing BEV solutions either suffer from modest performance or require considerable resources to execute on-vehicle inference. This paper proposes a simple yet effective framework, termed Fast-BEV, which is capable of performing real-time BEV perception on the on-vehicle chips. Towards this goal, we first empirically find that the BEV representation can be sufficiently powerful without expensive view transformation or depth representation. Starting from M2BEV baseline, we further introduce (1) a strong data augmentation strategy for both image and BEV space to avoid over-fitting (2) a multi-frame feature fusion mechanism to leverage the temporal information (3) an optimized deployment-friendly view transformation to speed up the inference. Through experiments, we show Fast-BEV model family achieves considerable accuracy and efficiency on edge. In particular, our M1 model (R18@256x704) can run over 50FPS on the Tesla T4 platform, with 47.0% NDS on the nuScenes validation set. Our largest model (R101@900x1600) establishes a new state-of-the-art 53.5% NDS on the nuScenes validation set. The code is released at: https://github.com/Sense-GVT/Fast-BEV.
* Accepted by NeurIPS2022_ML4AD on October 22, 2022
MQBench: Towards Reproducible and Deployable Model Quantization Benchmark
Nov 05, 2021
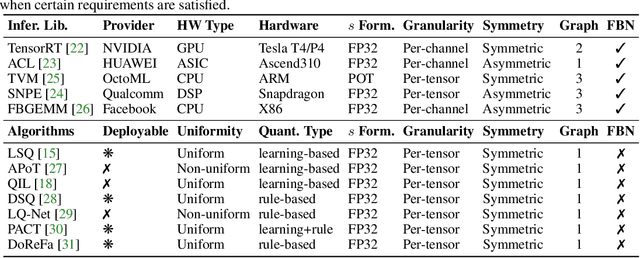

Model quantization has emerged as an indispensable technique to accelerate deep learning inference. While researchers continue to push the frontier of quantization algorithms, existing quantization work is often unreproducible and undeployable. This is because researchers do not choose consistent training pipelines and ignore the requirements for hardware deployments. In this work, we propose Model Quantization Benchmark (MQBench), a first attempt to evaluate, analyze, and benchmark the reproducibility and deployability for model quantization algorithms. We choose multiple different platforms for real-world deployments, including CPU, GPU, ASIC, DSP, and evaluate extensive state-of-the-art quantization algorithms under a unified training pipeline. MQBench acts like a bridge to connect the algorithm and the hardware. We conduct a comprehensive analysis and find considerable intuitive or counter-intuitive insights. By aligning the training settings, we find existing algorithms have about the same performance on the conventional academic track. While for the hardware-deployable quantization, there is a huge accuracy gap which remains unsettled. Surprisingly, no existing algorithm wins every challenge in MQBench, and we hope this work could inspire future research directions.
Learning in School: Multi-teacher Knowledge Inversion for Data-Free Quantization
Nov 19, 2020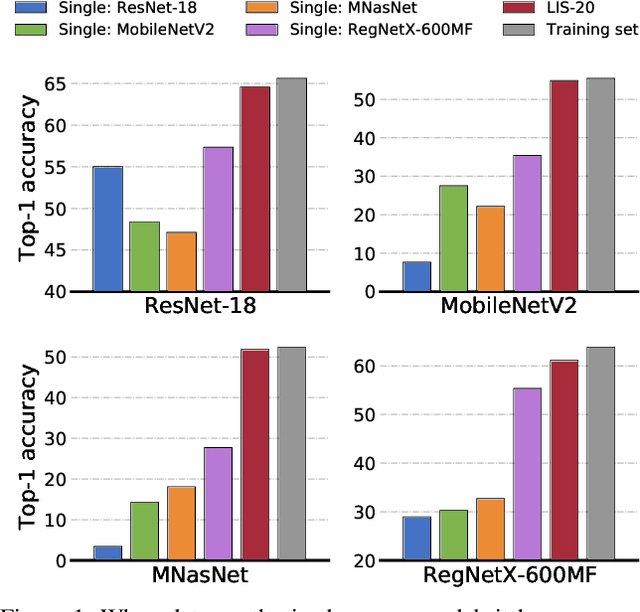
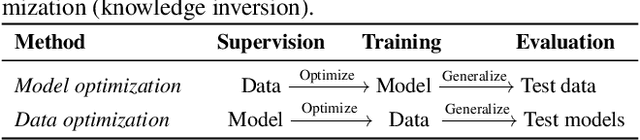
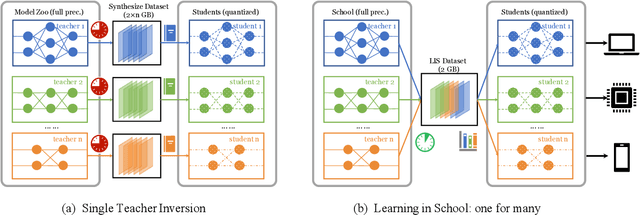
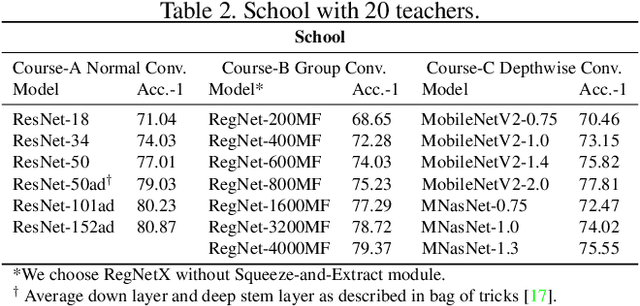
User data confidentiality protection is becoming a rising challenge in the present deep learning research. In that case, data-free quantization has emerged as a promising method to conduct model compression without the need for user data. With no access to data, model quantization naturally becomes less resilient and faces a higher risk of performance degradation. Prior works propose to distill fake images by matching the activation distribution given a specific pre-trained model. However, this fake data cannot be applied to other models easily and is optimized by an invariant objective, resulting in the lack of generalizability and diversity whereas these properties can be found in the natural image dataset. To address these problems, we propose Learning in School~(LIS) algorithm, capable to generate the images suitable for all models by inverting the knowledge in multiple teachers. We further introduce a decentralized training strategy by sampling teachers from hierarchical courses to simultaneously maintain the diversity of generated images. LIS data is highly diverse, not model-specific and only requires one-time synthesis to generalize multiple models and applications. Extensive experiments prove that LIS images resemble natural images with high quality and high fidelity. On data-free quantization, our LIS method significantly surpasses the existing model-specific methods. In particular, LIS data is effective in both post-training quantization and quantization-aware training on the ImageNet dataset and achieves up to 33\% top-1 accuracy uplift compared with existing methods.
Once Quantized for All: Progressively Searching for Quantized Efficient Models
Oct 09, 2020

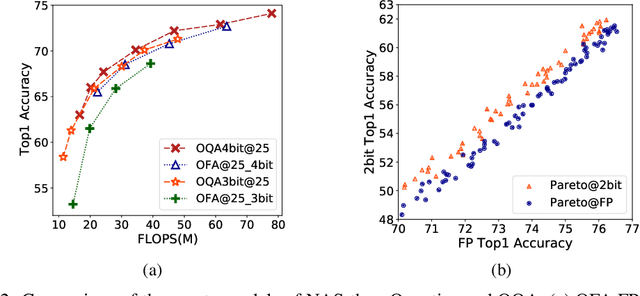
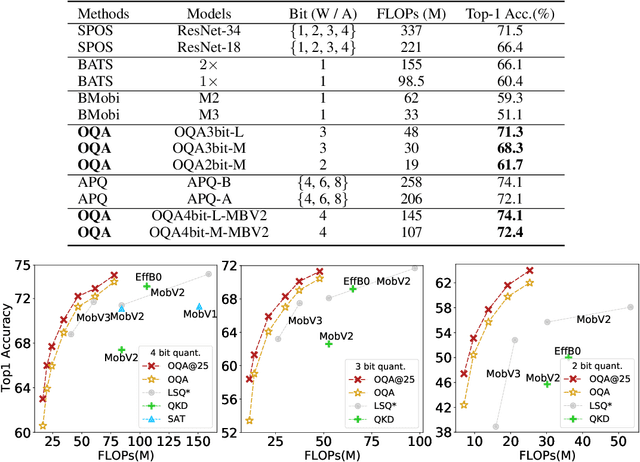
Automatic search of Quantized Neural Networks has attracted a lot of attention. However, the existing quantization aware Neural Architecture Search (NAS) approaches inherit a two-stage search-retrain schema, which is not only time-consuming but also adversely affected by the unreliable ranking of architectures during the search. To avoid the undesirable effect of the search-retrain schema, we present Once Quantized for All (OQA), a novel framework that searches for quantized efficient models and deploys their quantized weights at the same time without additional post-process. While supporting a huge architecture search space, our OQA can produce a series of ultra-low bit-width(e.g. 4/3/2 bit) quantized efficient models. A progressive bit inheritance procedure is introduced to support ultra-low bit-width. Our discovered model family, OQANets, achieves a new state-of-the-art (SOTA) on quantized efficient models compared with various quantization methods and bit-widths. In particular, OQA2bit-L achieves 64.0% ImageNet Top-1 accuracy, outperforming its 2-bit counterpart EfficientNet-B0@QKD by a large margin of 14% using 30% less computation budget. Code is available at https://github.com/LaVieEnRoseSMZ/OQA.