 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLSTM-MAS: A Long Short-Term Memory Inspired Multi-Agent System for Long-Context Understanding
Jan 17, 2026Effectively processing long contexts remains a fundamental yet unsolved challenge for large language models (LLMs). Existing single-LLM-based methods primarily reduce the context window or optimize the attention mechanism, but they often encounter additional computational costs or constrained expanded context length. While multi-agent-based frameworks can mitigate these limitations, they remain susceptible to the accumulation of errors and the propagation of hallucinations. In this work, we draw inspiration from the Long Short-Term Memory (LSTM) architecture to design a Multi-Agent System called LSTM-MAS, emulating LSTM's hierarchical information flow and gated memory mechanisms for long-context understanding. Specifically, LSTM-MAS organizes agents in a chained architecture, where each node comprises a worker agent for segment-level comprehension, a filter agent for redundancy reduction, a judge agent for continuous error detection, and a manager agent for globally regulates information propagation and retention, analogous to LSTM and its input gate, forget gate, constant error carousel unit, and output gate. These novel designs enable controlled information transfer and selective long-term dependency modeling across textual segments, which can effectively avoid error accumulation and hallucination propagation. We conducted an extensive evaluation of our method. Compared with the previous best multi-agent approach, CoA, our model achieves improvements of 40.93%, 43.70%,121.57% and 33.12%, on NarrativeQA, Qasper, HotpotQA, and MuSiQue, respectively.
FAVOR-Bench: A Comprehensive Benchmark for Fine-Grained Video Motion Understanding
Mar 19, 2025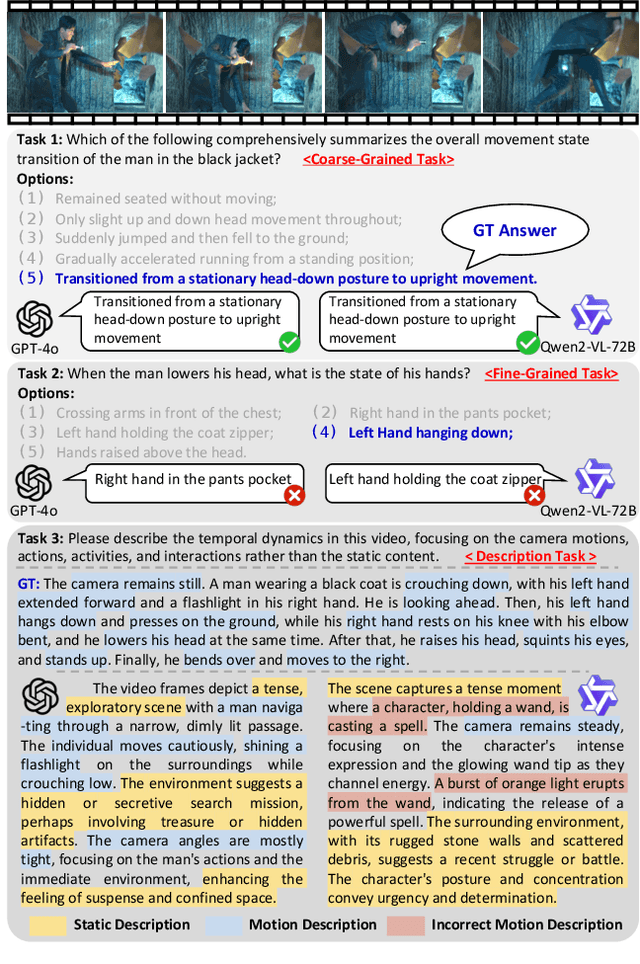

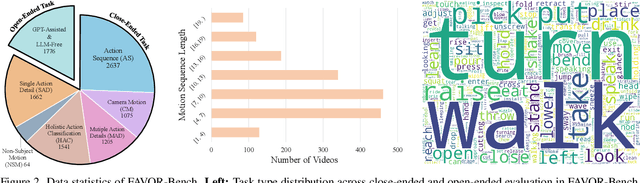

Multimodal Large Language Models (MLLMs) have shown remarkable capabilities in video content understanding but still struggle with fine-grained motion comprehension. To comprehensively assess the motion understanding ability of existing MLLMs, we introduce FAVOR-Bench, comprising 1,776 videos with structured manual annotations of various motions. Our benchmark includes both close-ended and open-ended tasks. For close-ended evaluation, we carefully design 8,184 multiple-choice question-answer pairs spanning six distinct sub-tasks. For open-ended evaluation, we develop both a novel cost-efficient LLM-free and a GPT-assisted caption assessment method, where the former can enhance benchmarking interpretability and reproducibility. Comprehensive experiments with 21 state-of-the-art MLLMs reveal significant limitations in their ability to comprehend and describe detailed temporal dynamics in video motions. To alleviate this limitation, we further build FAVOR-Train, a dataset consisting of 17,152 videos with fine-grained motion annotations. The results of finetuning Qwen2.5-VL on FAVOR-Train yield consistent improvements on motion-related tasks of TVBench, MotionBench and our FAVOR-Bench. Comprehensive assessment results demonstrate that the proposed FAVOR-Bench and FAVOR-Train provide valuable tools to the community for developing more powerful video understanding models. Project page: \href{https://favor-bench.github.io/}{https://favor-bench.github.io/}.
TokenCarve: Information-Preserving Visual Token Compression in Multimodal Large Language Models
Mar 13, 2025



Multimodal Large Language Models (MLLMs) are becoming increasingly popular, while the high computational cost associated with multimodal data input, particularly from visual tokens, poses a significant challenge. Existing training-based token compression methods improve inference efficiency but require costly retraining, while training-free methods struggle to maintain performance when aggressively reducing token counts. In this study, we reveal that the performance degradation of MLLM closely correlates with the accelerated loss of information in the attention output matrix. This insight introduces a novel information-preserving perspective, making it possible to maintain performance even under extreme token compression. Based on this finding, we propose TokenCarve, a training-free, plug-and-play, two-stage token compression framework. The first stage employs an Information-Preservation-Guided Selection (IPGS) strategy to prune low-information tokens, while the second stage further leverages IPGS to guide token merging, minimizing information loss. Extensive experiments on 11 datasets and 2 model variants demonstrate the effectiveness of TokenCarve. It can even reduce the number of visual tokens to 22.2% of the original count, achieving a 1.23x speedup in inference, a 64% reduction in KV cache storage, and only a 1.54% drop in accuracy. Our code is available at https://github.com/ShawnTan86/TokenCarve.
Attention Reallocation: Towards Zero-cost and Controllable Hallucination Mitigation of MLLMs
Mar 12, 2025Multi-Modal Large Language Models (MLLMs) stand out in various tasks but still struggle with hallucinations. While recent training-free mitigation methods mostly introduce additional inference overhead via retrospection strategy and contrastive decoding, we propose attention reallocation (AttnReal) to mitigate hallucinations with nearly zero extra cost. Our approach is motivated by the key observations that, MLLM's unreasonable attention distribution causes features to be dominated by historical output tokens, which further contributes to hallucinated responses because of the distribution gap between different token types. Based on the observations, AttnReal recycles excessive attention from output tokens and reallocates it to visual tokens, which reduces MLLM's reliance on language priors and ensures the decoding process depends more on the visual inputs. More interestingly, we find that, by controlling the intensity of AttnReal, we can achieve a wide-range trade-off between the response faithfulness and overall performance. Comprehensive results from different benchmarks validate the effectiveness of AttnReal across six open-source MLLMs and three decoding strategies.
$Δ$-DiT: A Training-Free Acceleration Method Tailored for Diffusion Transformers
Jun 03, 2024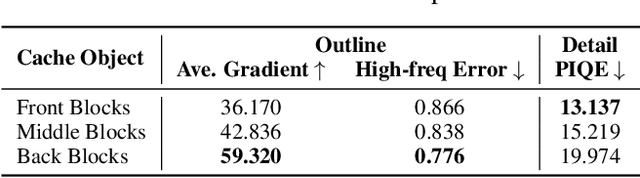
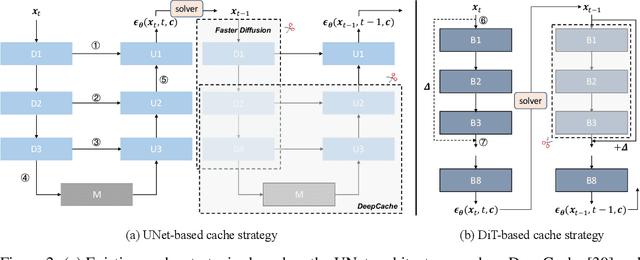

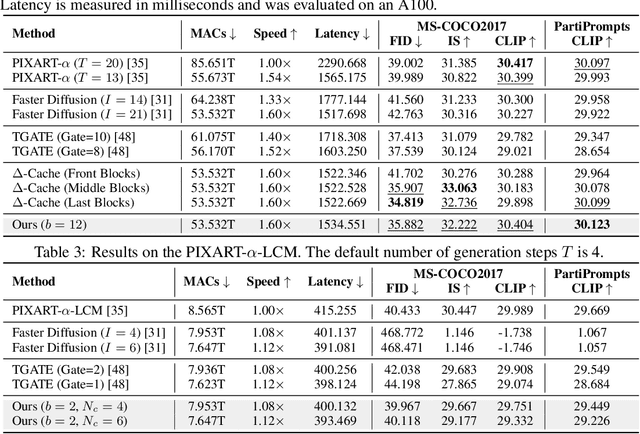
Diffusion models are widely recognized for generating high-quality and diverse images, but their poor real-time performance has led to numerous acceleration works, primarily focusing on UNet-based structures. With the more successful results achieved by diffusion transformers (DiT), there is still a lack of exploration regarding the impact of DiT structure on generation, as well as the absence of an acceleration framework tailored to the DiT architecture. To tackle these challenges, we conduct an investigation into the correlation between DiT blocks and image generation. Our findings reveal that the front blocks of DiT are associated with the outline of the generated images, while the rear blocks are linked to the details. Based on this insight, we propose an overall training-free inference acceleration framework $\Delta$-DiT: using a designed cache mechanism to accelerate the rear DiT blocks in the early sampling stages and the front DiT blocks in the later stages. Specifically, a DiT-specific cache mechanism called $\Delta$-Cache is proposed, which considers the inputs of the previous sampling image and reduces the bias in the inference. Extensive experiments on PIXART-$\alpha$ and DiT-XL demonstrate that the $\Delta$-DiT can achieve a $1.6\times$ speedup on the 20-step generation and even improves performance in most cases. In the scenario of 4-step consistent model generation and the more challenging $1.12\times$ acceleration, our method significantly outperforms existing methods. Our code will be publicly available.
ClipSAM: CLIP and SAM Collaboration for Zero-Shot Anomaly Segmentation
Jan 29, 2024



Recently, foundational models such as CLIP and SAM have shown promising performance for the task of Zero-Shot Anomaly Segmentation (ZSAS). However, either CLIP-based or SAM-based ZSAS methods still suffer from non-negligible key drawbacks: 1) CLIP primarily focuses on global feature alignment across different inputs, leading to imprecise segmentation of local anomalous parts; 2) SAM tends to generate numerous redundant masks without proper prompt constraints, resulting in complex post-processing requirements. In this work, we innovatively propose a CLIP and SAM collaboration framework called ClipSAM for ZSAS. The insight behind ClipSAM is to employ CLIP's semantic understanding capability for anomaly localization and rough segmentation, which is further used as the prompt constraints for SAM to refine the anomaly segmentation results. In details, we introduce a crucial Unified Multi-scale Cross-modal Interaction (UMCI) module for interacting language with visual features at multiple scales of CLIP to reason anomaly positions. Then, we design a novel Multi-level Mask Refinement (MMR) module, which utilizes the positional information as multi-level prompts for SAM to acquire hierarchical levels of masks and merges them. Extensive experiments validate the effectiveness of our approach, achieving the optimal segmentation performance on the MVTec-AD and VisA datasets.
Partial Fine-Tuning: A Successor to Full Fine-Tuning for Vision Transformers
Dec 25, 2023Fine-tuning pre-trained foundation models has gained significant popularity in various research fields. Existing methods for fine-tuning can be roughly divided into two categories, namely Parameter-Efficient Fine-Tuning and High-Performance Fine-Tuning. The former aims at improving efficiency, while the latter focuses on enhancing performance. Beyond these methods, we demonstrate that Partial Fine-Tuning can be an innovative and promising direction capable of concurrently enhancing both efficiency and accuracy. We first validate eight manually-defined partial fine-tuning strategies across kinds of datasets and vision transformer architectures, and find that some partial fine-tuning strategies (e.g., ffn only or attention only) can achieve better performance with fewer tuned parameters than full fine-tuning, and selecting appropriate layers is critical to partial fine-tuning. Thus, we propose a novel fine-tuned angle metric to guide the selection of appropriate layers for partial fine-tuning, making it flexible to be adapted to various scenarios for more practicable partial fine-tuning. Additionally, we show that partial fine-tuning can serve as a new dimension for Model Soups, improving both the model performance and generalization with fewer tuned parameters. Comprehensive experiments on a wide range of datasets and models validate the great potential of partial fine-tuning.
Efficient Architecture Search via Bi-level Data Pruning
Dec 21, 2023Improving the efficiency of Neural Architecture Search (NAS) is a challenging but significant task that has received much attention. Previous works mainly adopted the Differentiable Architecture Search (DARTS) and improved its search strategies or modules to enhance search efficiency. Recently, some methods have started considering data reduction for speedup, but they are not tightly coupled with the architecture search process, resulting in sub-optimal performance. To this end, this work pioneers an exploration into the critical role of dataset characteristics for DARTS bi-level optimization, and then proposes a novel Bi-level Data Pruning (BDP) paradigm that targets the weights and architecture levels of DARTS to enhance efficiency from a data perspective. Specifically, we introduce a new progressive data pruning strategy that utilizes supernet prediction dynamics as the metric, to gradually prune unsuitable samples for DARTS during the search. An effective automatic class balance constraint is also integrated into BDP, to suppress potential class imbalances resulting from data-efficient algorithms. Comprehensive evaluations on the NAS-Bench-201 search space, DARTS search space, and MobileNet-like search space validate that BDP reduces search costs by over 50% while achieving superior performance when applied to baseline DARTS. Besides, we demonstrate that BDP can harmoniously integrate with advanced DARTS variants, like PC-DARTS and \b{eta}-DARTS, offering an approximately 2 times speedup with minimal performance compromises.