 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurveStream: Boosting Streaming Video Understanding in MLLMs via Curvature-Aware Hierarchical Visual Memory Management
Mar 20, 2026Multimodal Large Language Models have achieved significant success in offline video understanding, yet their application to streaming videos is severely limited by the linear explosion of visual tokens, which often leads to Out-of-Memory (OOM) errors or catastrophic forgetting. Existing visual retention and memory management methods typically rely on uniform sampling, low-level physical metrics, or passive cache eviction. However, these strategies often lack intrinsic semantic awareness, potentially disrupting contextual coherence and blurring transient yet critical semantic transitions. To address these limitations, we propose CurveStream, a training-free, curvature-aware hierarchical visual memory management framework. Our approach is motivated by the key observation that high-curvature regions along continuous feature trajectories closely align with critical global semantic transitions. Based on this geometric insight, CurveStream evaluates real-time semantic intensity via a Curvature Score and integrates an online K-Sigma dynamic threshold to adaptively route frames into clear and fuzzy memory states under a strict token budget. Evaluations across diverse temporal scales confirm that this lightweight framework, CurveStream, consistently yields absolute performance gains of over 10% (e.g., 10.69% on StreamingBench and 13.58% on OVOBench) over respective baselines, establishing new state-of-the-art results for streaming video perception.The code will be released at https://github.com/streamingvideos/CurveStream.
Local Information Matters: Inference Acceleration For Grounded Conversation Generation Models Through Adaptive Local-Aware Token Pruning
Apr 01, 2025
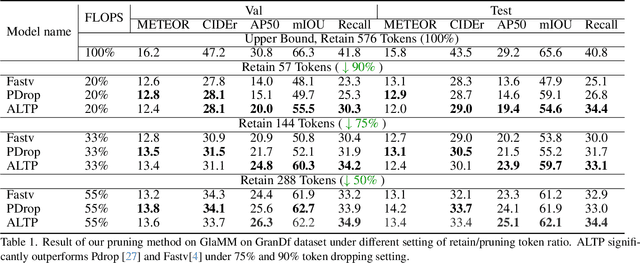


Grounded Conversation Generation (GCG) is an emerging vision-language task that requires models to generate natural language responses seamlessly intertwined with corresponding object segmentation masks. Recent models, such as GLaMM and OMG-LLaVA, achieve pixel-level grounding but incur significant computational costs due to processing a large number of visual tokens. Existing token pruning methods, like FastV and PyramidDrop, fail to preserve the local visual features critical for accurate grounding, leading to substantial performance drops in GCG tasks. To address this, we propose Adaptive Local-Aware Token Pruning (ALTP), a simple yet effective framework that accelerates GCG models by prioritizing local object information. ALTP introduces two key components: (1) Detail Density Capture (DDC), which uses superpixel segmentation to retain tokens in object-centric regions, preserving fine-grained details, and (2) Dynamic Density Formation (DDF), which dynamically allocates tokens based on information density, ensuring higher retention in semantically rich areas. Extensive experiments on the GranDf dataset demonstrate that ALTP significantly outperforms existing token pruning methods, such as FastV and PyramidDrop, on both GLaMM and OMG-LLaVA models. Notably, when applied to GLaMM, ALTP achieves a 90% reduction in visual tokens with a 4.9% improvement in AP50 and a 5.0% improvement in Recall compared to PyramidDrop. Similarly, on OMG-LLaVA, ALTP improves AP by 2.1% and mIOU by 3.0% at a 90% token reduction compared with PDrop.
TokenCarve: Information-Preserving Visual Token Compression in Multimodal Large Language Models
Mar 13, 2025



Multimodal Large Language Models (MLLMs) are becoming increasingly popular, while the high computational cost associated with multimodal data input, particularly from visual tokens, poses a significant challenge. Existing training-based token compression methods improve inference efficiency but require costly retraining, while training-free methods struggle to maintain performance when aggressively reducing token counts. In this study, we reveal that the performance degradation of MLLM closely correlates with the accelerated loss of information in the attention output matrix. This insight introduces a novel information-preserving perspective, making it possible to maintain performance even under extreme token compression. Based on this finding, we propose TokenCarve, a training-free, plug-and-play, two-stage token compression framework. The first stage employs an Information-Preservation-Guided Selection (IPGS) strategy to prune low-information tokens, while the second stage further leverages IPGS to guide token merging, minimizing information loss. Extensive experiments on 11 datasets and 2 model variants demonstrate the effectiveness of TokenCarve. It can even reduce the number of visual tokens to 22.2% of the original count, achieving a 1.23x speedup in inference, a 64% reduction in KV cache storage, and only a 1.54% drop in accuracy. Our code is available at https://github.com/ShawnTan86/TokenCarve.
DeRS: Towards Extremely Efficient Upcycled Mixture-of-Experts Models
Mar 03, 2025



Upcycled Mixture-of-Experts (MoE) models have shown great potential in various tasks by converting the original Feed-Forward Network (FFN) layers in pre-trained dense models into MoE layers. However, these models still suffer from significant parameter inefficiency due to the introduction of multiple experts. In this work, we propose a novel DeRS (Decompose, Replace, and Synthesis) paradigm to overcome this shortcoming, which is motivated by our observations about the unique redundancy mechanisms of upcycled MoE experts. Specifically, DeRS decomposes the experts into one expert-shared base weight and multiple expert-specific delta weights, and subsequently represents these delta weights in lightweight forms. Our proposed DeRS paradigm can be applied to enhance parameter efficiency in two different scenarios, including: 1) DeRS Compression for inference stage, using sparsification or quantization to compress vanilla upcycled MoE models; and 2) DeRS Upcycling for training stage, employing lightweight sparse or low-rank matrixes to efficiently upcycle dense models into MoE models. Extensive experiments across three different tasks show that the proposed methods can achieve extreme parameter efficiency while maintaining the performance for both training and compression of upcycled MoE models.
$Δ$-DiT: A Training-Free Acceleration Method Tailored for Diffusion Transformers
Jun 03, 2024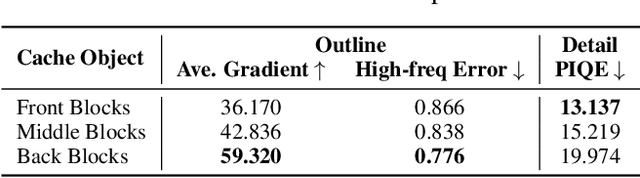
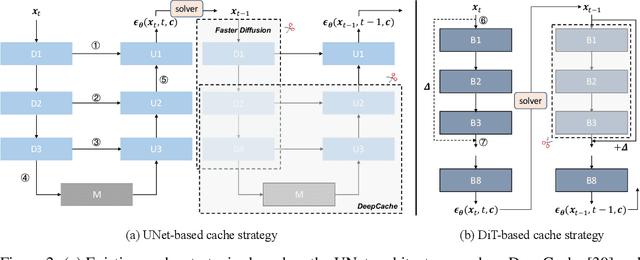

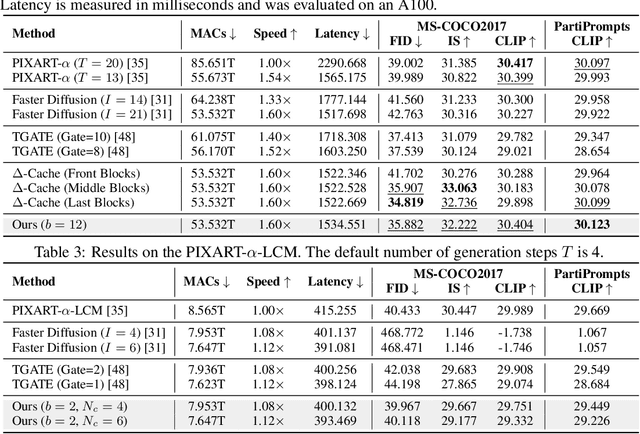
Diffusion models are widely recognized for generating high-quality and diverse images, but their poor real-time performance has led to numerous acceleration works, primarily focusing on UNet-based structures. With the more successful results achieved by diffusion transformers (DiT), there is still a lack of exploration regarding the impact of DiT structure on generation, as well as the absence of an acceleration framework tailored to the DiT architecture. To tackle these challenges, we conduct an investigation into the correlation between DiT blocks and image generation. Our findings reveal that the front blocks of DiT are associated with the outline of the generated images, while the rear blocks are linked to the details. Based on this insight, we propose an overall training-free inference acceleration framework $\Delta$-DiT: using a designed cache mechanism to accelerate the rear DiT blocks in the early sampling stages and the front DiT blocks in the later stages. Specifically, a DiT-specific cache mechanism called $\Delta$-Cache is proposed, which considers the inputs of the previous sampling image and reduces the bias in the inference. Extensive experiments on PIXART-$\alpha$ and DiT-XL demonstrate that the $\Delta$-DiT can achieve a $1.6\times$ speedup on the 20-step generation and even improves performance in most cases. In the scenario of 4-step consistent model generation and the more challenging $1.12\times$ acceleration, our method significantly outperforms existing methods. Our code will be publicly available.
MADTP: Multimodal Alignment-Guided Dynamic Token Pruning for Accelerating Vision-Language Transformer
Mar 05, 2024



Vision-Language Transformers (VLTs) have shown great success recently, but are meanwhile accompanied by heavy computation costs, where a major reason can be attributed to the large number of visual and language tokens. Existing token pruning research for compressing VLTs mainly follows a single-modality-based scheme yet ignores the critical role of aligning different modalities for guiding the token pruning process, causing the important tokens for one modality to be falsely pruned in another modality branch. Meanwhile, existing VLT pruning works also lack the flexibility to dynamically compress each layer based on different input samples. To this end, we propose a novel framework named Multimodal Alignment-Guided Dynamic Token Pruning (MADTP) for accelerating various VLTs. Specifically, we first introduce a well-designed Multi-modality Alignment Guidance (MAG) module that can align features of the same semantic concept from different modalities, to ensure the pruned tokens are less important for all modalities. We further design a novel Dynamic Token Pruning (DTP) module, which can adaptively adjust the token compression ratio in each layer based on different input instances. Extensive experiments on various benchmarks demonstrate that MADTP significantly reduces the computational complexity of kinds of multimodal models while preserving competitive performance. Notably, when applied to the BLIP model in the NLVR2 dataset, MADTP can reduce the GFLOPs by 80% with less than 4% performance degradation.
* 19 pages, 9 figures, Published in CVPR2024
ClipSAM: CLIP and SAM Collaboration for Zero-Shot Anomaly Segmentation
Jan 29, 2024



Recently, foundational models such as CLIP and SAM have shown promising performance for the task of Zero-Shot Anomaly Segmentation (ZSAS). However, either CLIP-based or SAM-based ZSAS methods still suffer from non-negligible key drawbacks: 1) CLIP primarily focuses on global feature alignment across different inputs, leading to imprecise segmentation of local anomalous parts; 2) SAM tends to generate numerous redundant masks without proper prompt constraints, resulting in complex post-processing requirements. In this work, we innovatively propose a CLIP and SAM collaboration framework called ClipSAM for ZSAS. The insight behind ClipSAM is to employ CLIP's semantic understanding capability for anomaly localization and rough segmentation, which is further used as the prompt constraints for SAM to refine the anomaly segmentation results. In details, we introduce a crucial Unified Multi-scale Cross-modal Interaction (UMCI) module for interacting language with visual features at multiple scales of CLIP to reason anomaly positions. Then, we design a novel Multi-level Mask Refinement (MMR) module, which utilizes the positional information as multi-level prompts for SAM to acquire hierarchical levels of masks and merges them. Extensive experiments validate the effectiveness of our approach, achieving the optimal segmentation performance on the MVTec-AD and VisA datasets.
Collaborative Position Reasoning Network for Referring Image Segmentation
Jan 22, 2024Given an image and a natural language expression as input, the goal of referring image segmentation is to segment the foreground masks of the entities referred by the expression. Existing methods mainly focus on interactive learning between vision and language to enhance the multi-modal representations for global context reasoning. However, predicting directly in pixel-level space can lead to collapsed positioning and poor segmentation results. Its main challenge lies in how to explicitly model entity localization, especially for non-salient entities. In this paper, we tackle this problem by executing a Collaborative Position Reasoning Network (CPRN) via the proposed novel Row-and-Column interactive (RoCo) and Guided Holistic interactive (Holi) modules. Specifically, RoCo aggregates the visual features into the row- and column-wise features corresponding two directional axes respectively. It offers a fine-grained matching behavior that perceives the associations between the linguistic features and two decoupled visual features to perform position reasoning over a hierarchical space. Holi integrates features of the two modalities by a cross-modal attention mechanism, which suppresses the irrelevant redundancy under the guide of positioning information from RoCo. Thus, with the incorporation of RoCo and Holi modules, CPRN captures the visual details of position reasoning so that the model can achieve more accurate segmentation. To our knowledge, this is the first work that explicitly focuses on position reasoning modeling. We also validate the proposed method on three evaluation datasets. It consistently outperforms existing state-of-the-art methods.
LAMM: Language-Assisted Multi-Modal Instruction-Tuning Dataset, Framework, and Benchmark
Jun 18, 2023
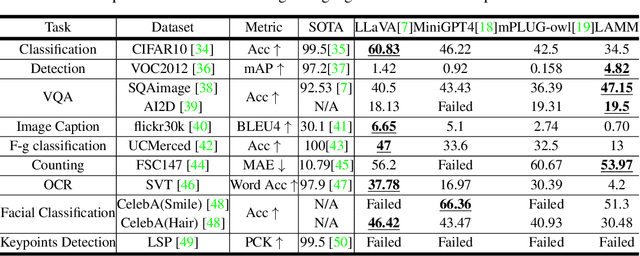
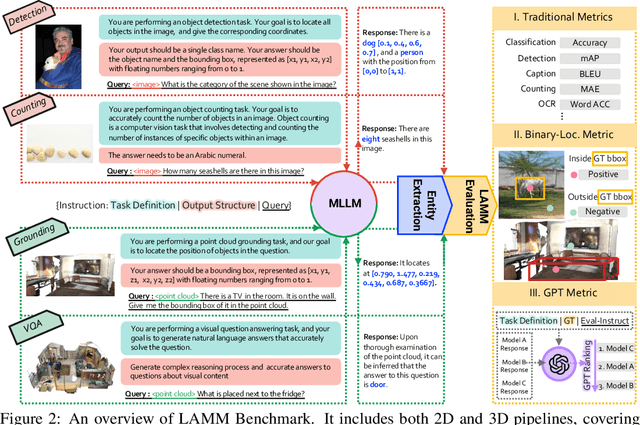
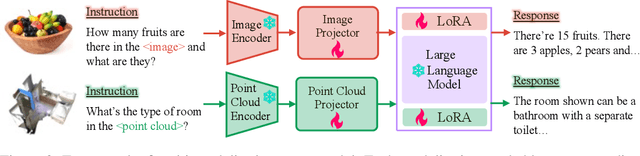
Large language models have become a potential pathway toward achieving artificial general intelligence. Recent works on multi-modal large language models have demonstrated their effectiveness in handling visual modalities. In this work, we extend the research of MLLMs to point clouds and present the LAMM-Dataset and LAMM-Benchmark for 2D image and 3D point cloud understanding. We also establish an extensible framework to facilitate the extension of MLLMs to additional modalities. Our main contribution is three-fold: 1) We present the LAMM-Dataset and LAMM-Benchmark, which cover almost all high-level vision tasks for 2D and 3D vision. Extensive experiments validate the effectiveness of our dataset and benchmark. 2) We demonstrate the detailed methods of constructing instruction-tuning datasets and benchmarks for MLLMs, which will enable future research on MLLMs to scale up and extend to other domains, tasks, and modalities faster. 3) We provide a primary but potential MLLM training framework optimized for modalities' extension. We also provide baseline models, comprehensive experimental observations, and analysis to accelerate future research. Codes and datasets are now available at https://github.com/OpenLAMM/LAMM.
A2S-NAS: Asymmetric Spectral-Spatial Neural Architecture Search For Hyperspectral Image Classification
Feb 23, 2023



Existing deep learning-based hyperspectral image (HSI) classification works still suffer from the limitation of the fixed-sized receptive field, leading to difficulties in distinctive spectral-spatial features for ground objects with various sizes and arbitrary shapes. Meanwhile, plenty of previous works ignore asymmetric spectral-spatial dimensions in HSI. To address the above issues, we propose a multi-stage search architecture in order to overcome asymmetric spectral-spatial dimensions and capture significant features. First, the asymmetric pooling on the spectral-spatial dimension maximally retains the essential features of HSI. Then, the 3D convolution with a selectable range of receptive fields overcomes the constraints of fixed-sized convolution kernels. Finally, we extend these two searchable operations to different layers of each stage to build the final architecture. Extensive experiments are conducted on two challenging HSI benchmarks including Indian Pines and Houston University, and results demonstrate the effectiveness of the proposed method with superior performance compared with the related works.