 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDQEN: Dual Query Enhancement Network for DETR-based HOI Detection
Aug 26, 2025Human-Object Interaction (HOI) detection focuses on localizing human-object pairs and recognizing their interactions. Recently, the DETR-based framework has been widely adopted in HOI detection. In DETR-based HOI models, queries with clear meaning are crucial for accurately detecting HOIs. However, prior works have typically relied on randomly initialized queries, leading to vague representations that limit the model's effectiveness. Meanwhile, humans in the HOI categories are fixed, while objects and their interactions are variable. Therefore, we propose a Dual Query Enhancement Network (DQEN) to enhance object and interaction queries. Specifically, object queries are enhanced with object-aware encoder features, enabling the model to focus more effectively on humans interacting with objects in an object-aware way. On the other hand, we design a novel Interaction Semantic Fusion module to exploit the HOI candidates that are promoted by the CLIP model. Semantic features are extracted to enhance the initialization of interaction queries, thereby improving the model's ability to understand interactions. Furthermore, we introduce an Auxiliary Prediction Unit aimed at improving the representation of interaction features. Our proposed method achieves competitive performance on both the HICO-Det and the V-COCO datasets. The source code is available at https://github.com/lzzhhh1019/DQEN.
EarthLink: A Self-Evolving AI Agent for Climate Science
Jul 24, 2025


Modern Earth science is at an inflection point. The vast, fragmented, and complex nature of Earth system data, coupled with increasingly sophisticated analytical demands, creates a significant bottleneck for rapid scientific discovery. Here we introduce EarthLink, the first AI agent designed as an interactive copilot for Earth scientists. It automates the end-to-end research workflow, from planning and code generation to multi-scenario analysis. Unlike static diagnostic tools, EarthLink can learn from user interaction, continuously refining its capabilities through a dynamic feedback loop. We validated its performance on a number of core scientific tasks of climate change, ranging from model-observation comparisons to the diagnosis of complex phenomena. In a multi-expert evaluation, EarthLink produced scientifically sound analyses and demonstrated an analytical competency that was rated as comparable to specific aspects of a human junior researcher's workflow. Additionally, its transparent, auditable workflows and natural language interface empower scientists to shift from laborious manual execution to strategic oversight and hypothesis generation. EarthLink marks a pivotal step towards an efficient, trustworthy, and collaborative paradigm for Earth system research in an era of accelerating global change. The system is accessible at our website https://earthlink.intern-ai.org.cn.
OmniEarth-Bench: Towards Holistic Evaluation of Earth's Six Spheres and Cross-Spheres Interactions with Multimodal Observational Earth Data
May 29, 2025Existing benchmarks for Earth science multimodal learning exhibit critical limitations in systematic coverage of geosystem components and cross-sphere interactions, often constrained to isolated subsystems (only in Human-activities sphere or atmosphere) with limited evaluation dimensions (less than 16 tasks). To address these gaps, we introduce OmniEarth-Bench, the first comprehensive multimodal benchmark spanning all six Earth science spheres (atmosphere, lithosphere, Oceansphere, cryosphere, biosphere and Human-activities sphere) and cross-spheres with one hundred expert-curated evaluation dimensions. Leveraging observational data from satellite sensors and in-situ measurements, OmniEarth-Bench integrates 29,779 annotations across four tiers: perception, general reasoning, scientific knowledge reasoning and chain-of-thought (CoT) reasoning. This involves the efforts of 2-5 experts per sphere to establish authoritative evaluation dimensions and curate relevant observational datasets, 40 crowd-sourcing annotators to assist experts for annotations, and finally, OmniEarth-Bench is validated via hybrid expert-crowd workflows to reduce label ambiguity. Experiments on 9 state-of-the-art MLLMs reveal that even the most advanced models struggle with our benchmarks, where none of them reach 35\% accuracy. Especially, in some cross-spheres tasks, the performance of leading models like GPT-4o drops to 0.0\%. OmniEarth-Bench sets a new standard for geosystem-aware AI, advancing both scientific discovery and practical applications in environmental monitoring and disaster prediction. The dataset, source code, and trained models were released.
Molly: Making Large Language Model Agents Solve Python Problem More Logically
Dec 24, 2024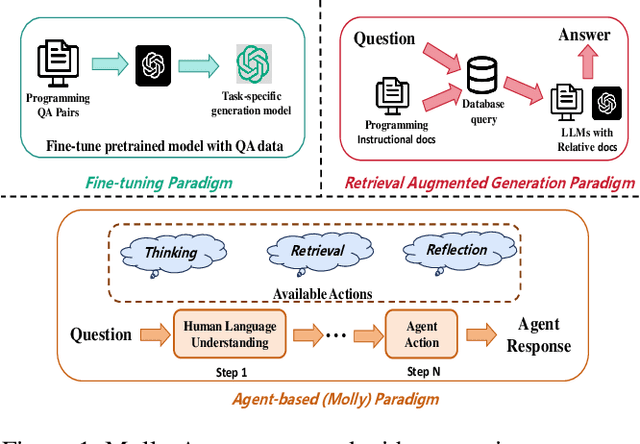
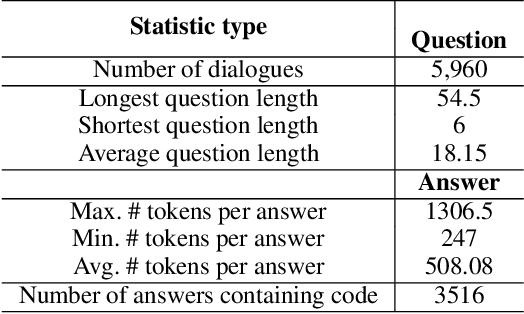
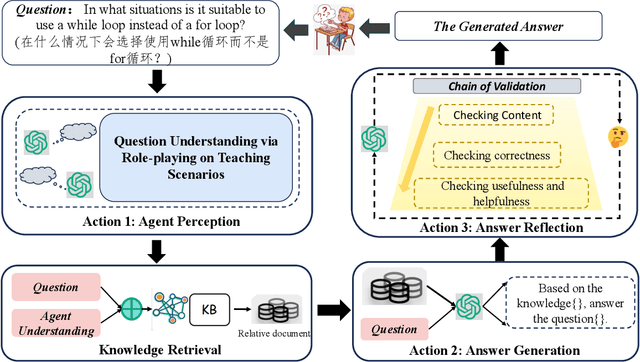

Applying large language models (LLMs) as teaching assists has attracted much attention as an integral part of intelligent education, particularly in computing courses. To reduce the gap between the LLMs and the computer programming education expert, fine-tuning and retrieval augmented generation (RAG) are the two mainstream methods in existing researches. However, fine-tuning for specific tasks is resource-intensive and may diminish the model`s generalization capabilities. RAG can perform well on reducing the illusion of LLMs, but the generation of irrelevant factual content during reasoning can cause significant confusion for learners. To address these problems, we introduce the Molly agent, focusing on solving the proposed problem encountered by learners when learning Python programming language. Our agent automatically parse the learners' questioning intent through a scenario-based interaction, enabling precise retrieval of relevant documents from the constructed knowledge base. At generation stage, the agent reflect on the generated responses to ensure that they not only align with factual content but also effectively answer the user's queries. Extensive experimentation on a constructed Chinese Python QA dataset shows the effectiveness of the Molly agent, indicating an enhancement in its performance for providing useful responses to Python questions.
DualMamba: A Lightweight Spectral-Spatial Mamba-Convolution Network for Hyperspectral Image Classification
Jun 11, 2024
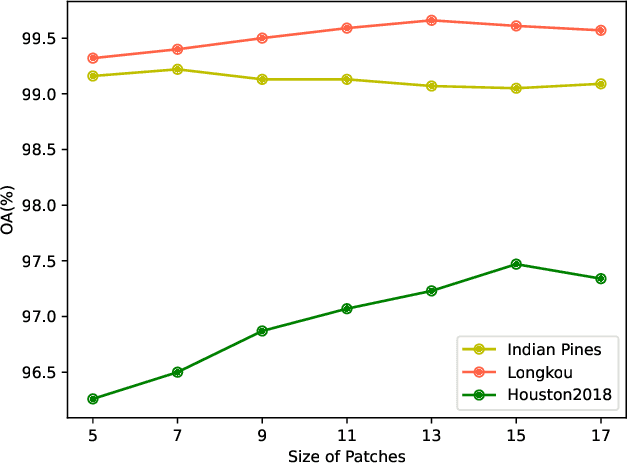
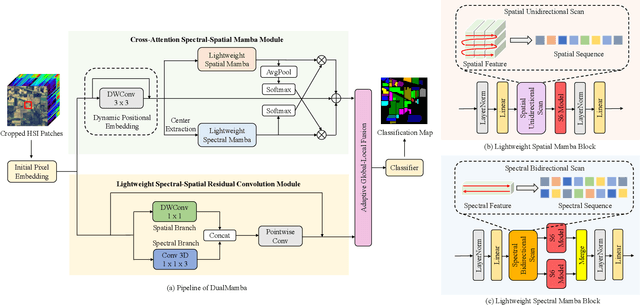
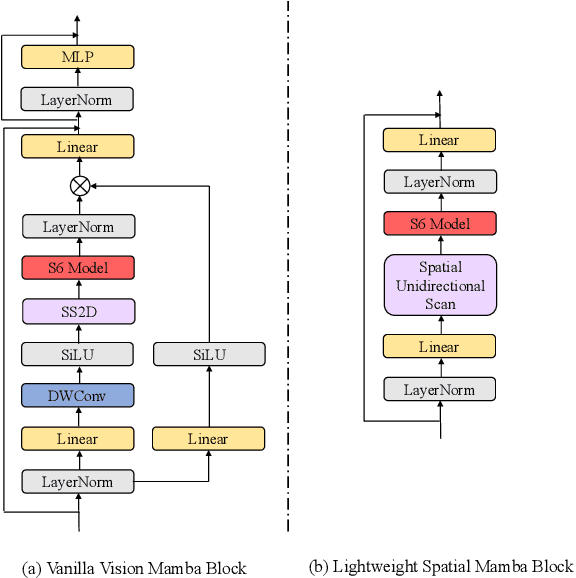
The effectiveness and efficiency of modeling complex spectral-spatial relations are both crucial for Hyperspectral image (HSI) classification. Most existing methods based on CNNs and transformers still suffer from heavy computational burdens and have room for improvement in capturing the global-local spectral-spatial feature representation. To this end, we propose a novel lightweight parallel design called lightweight dual-stream Mamba-convolution network (DualMamba) for HSI classification. Specifically, a parallel lightweight Mamba and CNN block are first developed to extract global and local spectral-spatial features. First, the cross-attention spectral-spatial Mamba module is proposed to leverage the global modeling of Mamba at linear complexity. Within this module, dynamic positional embedding is designed to enhance the spatial location information of visual sequences. The lightweight spectral/spatial Mamba blocks comprise an efficient scanning strategy and a lightweight Mamba design to efficiently extract global spectral-spatial features. And the cross-attention spectral-spatial fusion is designed to learn cross-correlation and fuse spectral-spatial features. Second, the lightweight spectral-spatial residual convolution module is proposed with lightweight spectral and spatial branches to extract local spectral-spatial features through residual learning. Finally, the adaptive global-local fusion is proposed to dynamically combine global Mamba features and local convolution features for a global-local spectral-spatial representation. Compared with state-of-the-art HSI classification methods, experimental results demonstrate that DualMamba achieves significant classification accuracy on three public HSI datasets and a superior reduction in model parameters and floating point operations (FLOPs).
FreeMan: Towards Benchmarking 3D Human Pose Estimation in the Wild
Sep 12, 2023Estimating the 3D structure of the human body from natural scenes is a fundamental aspect of visual perception. This task carries great importance for fields like AIGC and human-robot interaction. In practice, 3D human pose estimation in real-world settings is a critical initial step in solving this problem. However, the current datasets, often collected under controlled laboratory conditions using complex motion capture equipment and unvarying backgrounds, are insufficient. The absence of real-world datasets is stalling the progress of this crucial task. To facilitate the development of 3D pose estimation, we present FreeMan, the first large-scale, real-world multi-view dataset. FreeMan was captured by synchronizing 8 smartphones across diverse scenarios. It comprises 11M frames from 8000 sequences, viewed from different perspectives. These sequences cover 40 subjects across 10 different scenarios, each with varying lighting conditions. We have also established an automated, precise labeling pipeline that allows for large-scale processing efficiently. We provide comprehensive evaluation baselines for a range of tasks, underlining the significant challenges posed by FreeMan. Further evaluations of standard indoor/outdoor human sensing datasets reveal that FreeMan offers robust representation transferability in real and complex scenes. FreeMan is now publicly available at https://wangjiongw.github.io/freeman.
LAMM: Language-Assisted Multi-Modal Instruction-Tuning Dataset, Framework, and Benchmark
Jun 18, 2023
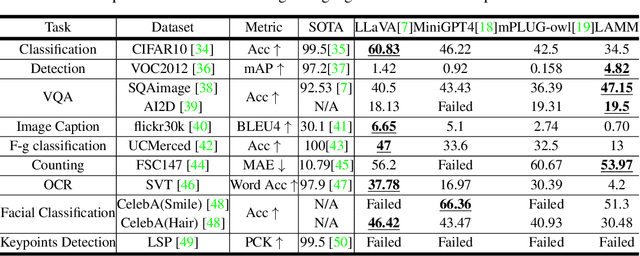
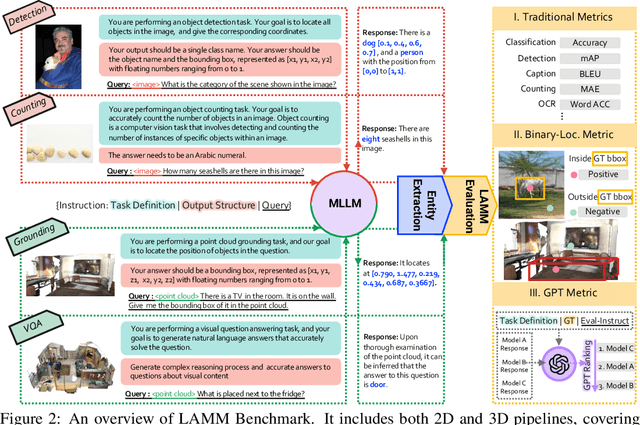
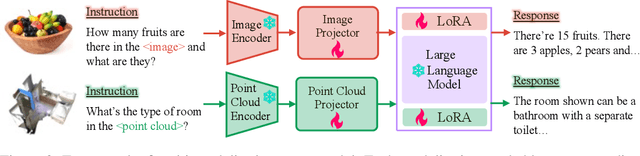
Large language models have become a potential pathway toward achieving artificial general intelligence. Recent works on multi-modal large language models have demonstrated their effectiveness in handling visual modalities. In this work, we extend the research of MLLMs to point clouds and present the LAMM-Dataset and LAMM-Benchmark for 2D image and 3D point cloud understanding. We also establish an extensible framework to facilitate the extension of MLLMs to additional modalities. Our main contribution is three-fold: 1) We present the LAMM-Dataset and LAMM-Benchmark, which cover almost all high-level vision tasks for 2D and 3D vision. Extensive experiments validate the effectiveness of our dataset and benchmark. 2) We demonstrate the detailed methods of constructing instruction-tuning datasets and benchmarks for MLLMs, which will enable future research on MLLMs to scale up and extend to other domains, tasks, and modalities faster. 3) We provide a primary but potential MLLM training framework optimized for modalities' extension. We also provide baseline models, comprehensive experimental observations, and analysis to accelerate future research. Codes and datasets are now available at https://github.com/OpenLAMM/LAMM.
Set-Based Face Recognition Beyond Disentanglement: Burstiness Suppression With Variance Vocabulary
Apr 13, 2023Set-based face recognition (SFR) aims to recognize the face sets in the unconstrained scenario, where the appearance of same identity may change dramatically with extreme variances (e.g., illumination, pose, expression). We argue that the two crucial issues in SFR, the face quality and burstiness, are both identity-irrelevant and variance-relevant. The quality and burstiness assessment are interfered with by the entanglement of identity, and the face recognition is interfered with by the entanglement of variance. Thus we propose to separate the identity features with the variance features in a light-weighted set-based disentanglement framework. Beyond disentanglement, the variance features are fully utilized to indicate face quality and burstiness in a set, rather than being discarded after training. To suppress face burstiness in the sets, we propose a vocabulary-based burst suppression (VBS) method which quantizes faces with a reference vocabulary. With interword and intra-word normalization operations on the assignment scores, the face burtisness degrees are appropriately estimated. The extensive illustrations and experiments demonstrate the effect of the disentanglement framework with VBS, which gets new state-of-the-art on the SFR benchmarks. The code will be released at https://github.com/Liubinggunzu/set_burstiness.
Model Compression for DNN-Based Text-Independent Speaker Verification Using Weight Quantization
Nov 14, 2022


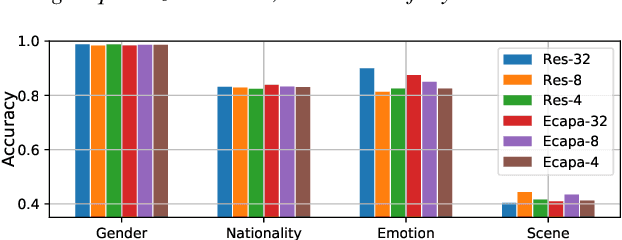
DNN-based models achieve high performance in the speaker verification (SV) task with substantial computation costs. The model size is an essential concern in applying models on resource-constrained devices, while model compression for SV models has not been studied extensively in previous works. Weight quantization is exploited to compress DNN-based speaker embedding extraction models in this paper. Uniform and Powers-of-Two quantization are utilized in the experiments. The results on VoxCeleb show that the weight quantization can decrease the size of ECAPA-TDNN and ResNet by 4 times with insignificant performance decline. The quantized 4-bit ResNet achieves similar performance to the original model with an 8 times smaller size. We empirically show that the performance of ECAPA-TDNN is more sensitive than ResNet to quantization due to the difference in weight distribution. The experiments on CN-Celeb also demonstrate that quantized models are robust for SV in the language mismatch scenario.
Frame-Subtitle Self-Supervision for Multi-Modal Video Question Answering
Sep 08, 2022
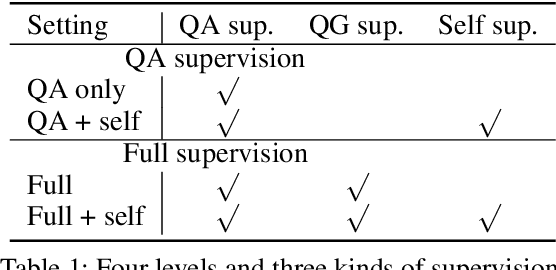
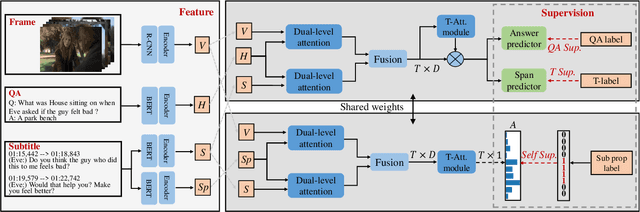

Multi-modal video question answering aims to predict correct answer and localize the temporal boundary relevant to the question. The temporal annotations of questions improve QA performance and interpretability of recent works, but they are usually empirical and costly. To avoid the temporal annotations, we devise a weakly supervised question grounding (WSQG) setting, where only QA annotations are used and the relevant temporal boundaries are generated according to the temporal attention scores. To substitute the temporal annotations, we transform the correspondence between frames and subtitles to Frame-Subtitle (FS) self-supervision, which helps to optimize the temporal attention scores and hence improve the video-language understanding in VideoQA model. The extensive experiments on TVQA and TVQA+ datasets demonstrate that the proposed WSQG strategy gets comparable performance on question grounding, and the FS self-supervision helps improve the question answering and grounding performance on both QA-supervision only and full-supervision settings.