 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoice Timbre Attribute Detection with Compact and Interpretable Training-Free Acoustic Parameters
Mar 05, 2026Voice timbre attribute detection (vTAD) is the task of determining the relative intensity of timbre attributes between speech utterances. Voice timbre is a crucial yet inherently complex component of speech perception. While deep neural network (DNN) embeddings perform well in speaker modelling, they often act as black-box representations with limited physical interpretability and high computational cost. In this work, a compact acoustic parameter set is investigated for vTAD. The set captures important acoustic measures and their temporal dynamics which are found to be crucial in the task. Despite its simplicity, the acoustic parameter set is competitive, outperforming conventional cepstral features and supervised DNN embeddings, and approaching state-of-the-art self-supervised models. Importantly, the studied set require no trainable parameters, incur negligible computation, and offer explicit interpretability for analysing physical traits behind human timbre perception.
PodEval: A Multimodal Evaluation Framework for Podcast Audio Generation
Oct 01, 2025Recently, an increasing number of multimodal (text and audio) benchmarks have emerged, primarily focusing on evaluating models' understanding capability. However, exploration into assessing generative capabilities remains limited, especially for open-ended long-form content generation. Significant challenges lie in no reference standard answer, no unified evaluation metrics and uncontrollable human judgments. In this work, we take podcast-like audio generation as a starting point and propose PodEval, a comprehensive and well-designed open-source evaluation framework. In this framework: 1) We construct a real-world podcast dataset spanning diverse topics, serving as a reference for human-level creative quality. 2) We introduce a multimodal evaluation strategy and decompose the complex task into three dimensions: text, speech and audio, with different evaluation emphasis on "Content" and "Format". 3) For each modality, we design corresponding evaluation methods, involving both objective metrics and subjective listening test. We leverage representative podcast generation systems (including open-source, close-source, and human-made) in our experiments. The results offer in-depth analysis and insights into podcast generation, demonstrating the effectiveness of PodEval in evaluating open-ended long-form audio. This project is open-source to facilitate public use: https://github.com/yujxx/PodEval.
Low-Resource NMT: A Case Study on the Written and Spoken Languages in Hong Kong
May 23, 2025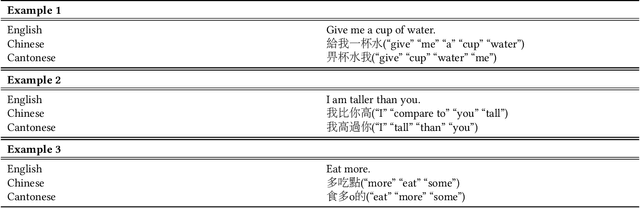



The majority of inhabitants in Hong Kong are able to read and write in standard Chinese but use Cantonese as the primary spoken language in daily life. Spoken Cantonese can be transcribed into Chinese characters, which constitute the so-called written Cantonese. Written Cantonese exhibits significant lexical and grammatical differences from standard written Chinese. The rise of written Cantonese is increasingly evident in the cyber world. The growing interaction between Mandarin speakers and Cantonese speakers is leading to a clear demand for automatic translation between Chinese and Cantonese. This paper describes a transformer-based neural machine translation (NMT) system for written-Chinese-to-written-Cantonese translation. Given that parallel text data of Chinese and Cantonese are extremely scarce, a major focus of this study is on the effort of preparing good amount of training data for NMT. In addition to collecting 28K parallel sentences from previous linguistic studies and scattered internet resources, we devise an effective approach to obtaining 72K parallel sentences by automatically extracting pairs of semantically similar sentences from parallel articles on Chinese Wikipedia and Cantonese Wikipedia. We show that leveraging highly similar sentence pairs mined from Wikipedia improves translation performance in all test sets. Our system outperforms Baidu Fanyi's Chinese-to-Cantonese translation on 6 out of 8 test sets in BLEU scores. Translation examples reveal that our system is able to capture important linguistic transformations between standard Chinese and spoken Cantonese.
Probing Speaker-specific Features in Speaker Representations
Jan 09, 2025
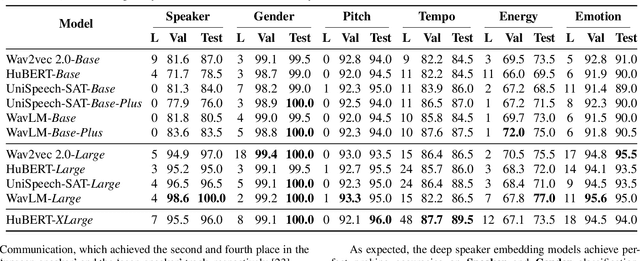
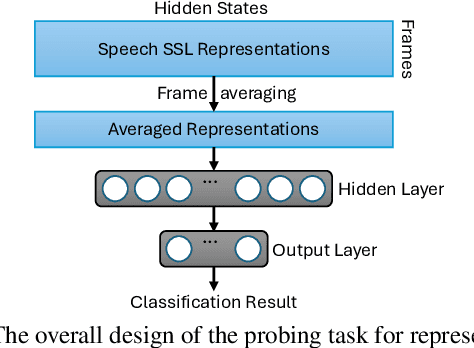
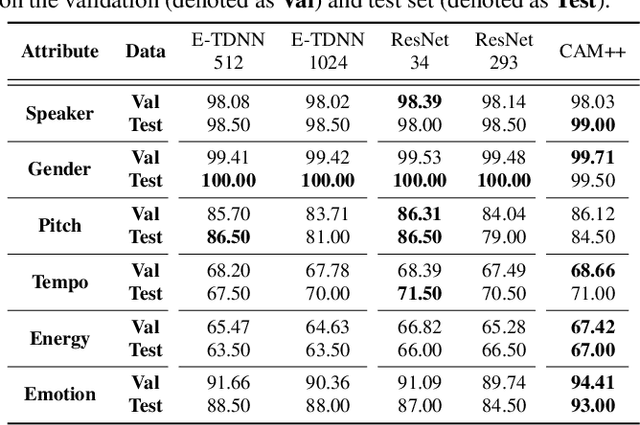
This study explores speaker-specific features encoded in speaker embeddings and intermediate layers of speech self-supervised learning (SSL) models. By utilising a probing method, we analyse features such as pitch, tempo, and energy across prominent speaker embedding models and speech SSL models, including HuBERT, WavLM, and Wav2vec 2.0. The results reveal that speaker embeddings like CAM++ excel in energy classification, while speech SSL models demonstrate superior performance across multiple features due to their hierarchical feature encoding. Intermediate layers effectively capture a mix of acoustic and para-linguistic information, with deeper layers refining these representations. This investigation provides insights into model design and highlights the potential of these representations for downstream applications, such as speaker verification and text-to-speech synthesis, while laying the groundwork for exploring additional features and advanced probing methods.
An Investigation of Reprogramming for Cross-Language Adaptation in Speaker Verification Systems
Nov 18, 2024



Language mismatch is among the most common and challenging domain mismatches in deploying speaker verification (SV) systems. Adversarial reprogramming has shown promising results in cross-language adaptation for SV. The reprogramming is implemented by padding learnable parameters on the two sides of input speech signals. In this paper, we investigate the relationship between the number of padded parameters and the performance of the reprogrammed models. Sufficient experiments are conducted with different scales of SV models and datasets. The results demonstrate that reprogramming consistently improves the performance of cross-language SV, while the improvement is saturated or even degraded when using larger padding lengths. The performance is mainly determined by the capacity of the original SV models instead of the number of padded parameters. The SV models with larger scales have higher upper bounds in performance and can endure longer padding without performance degradation.
CUEMPATHY: A Counseling Speech Dataset for Psychotherapy Research
Sep 04, 2024


Psychotherapy or counseling is typically conducted through spoken conversation between a therapist and a client. Analyzing the speech characteristics of psychotherapeutic interactions can help understand the factors associated with effective psychotherapy. This paper introduces CUEMPATHY, a large-scale speech dataset collected from actual counseling sessions. The dataset consists of 156 counseling sessions involving 39 therapist-client dyads. The process of speech data collection, subjective ratings (one observer and two client ratings), and transcription are described. An automatic speech and text processing system is developed to locate the time stamps of speaker turns in each session. Examining the relationships among the three subjective ratings suggests that observer and client ratings have no significant correlation, while the client-rated measures are significantly correlated. The intensity similarity between the therapist and the client, measured by the averaged absolute difference of speaker-turn-level intensities, is associated with the psychotherapy outcomes. Recent studies on the acoustic and linguistic characteristics of the CUEMPATHY are introduced.
User-Driven Voice Generation and Editing through Latent Space Navigation
Aug 30, 2024



This paper presents a user-driven approach for synthesizing highly specific target voices based on user feedback, which is particularly beneficial for speech-impaired individuals who wish to recreate their lost voices but lack prior recordings. Specifically, we leverage the neural analysis and synthesis framework to construct a low-dimensional, yet sufficiently expressive latent speaker embedding space. Within this latent space, we implement a search algorithm that guides users to their desired voice through completing a sequence of straightforward comparison tasks. Both synthetic simulations and real-world user studies demonstrate that the proposed approach can effectively approximate target voices. Moreover, by analyzing the mel-spectrogram generator's Jacobians, we identify a set of meaningful voice editing directions within the latent space. These directions enable users to further fine-tune specific attributes of the generated voice, including the pitch level, pitch range, volume, vocal tension, nasality, and tone color. Audio samples are available at https://myspeechprojects.github.io/voicedesign/.
ToneUnit: A Speech Discretization Approach for Tonal Language Speech Synthesis
Jun 13, 2024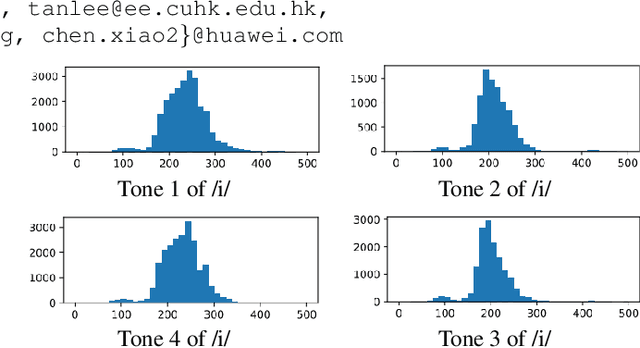
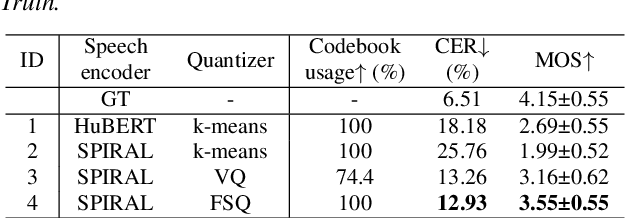
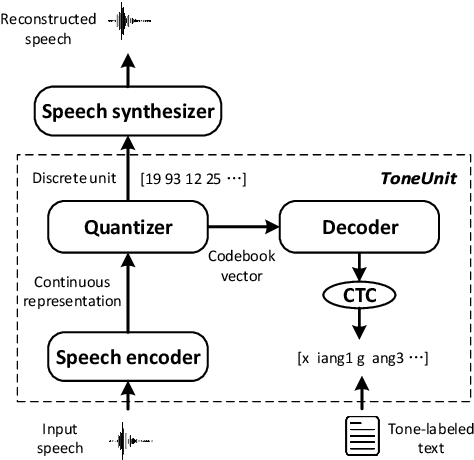
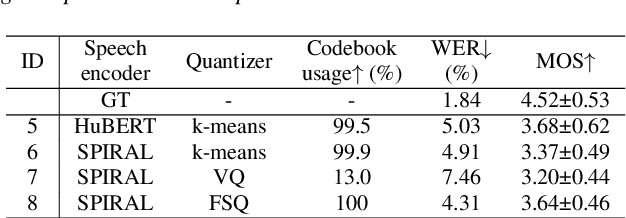
Representing speech as discretized units has numerous benefits in supporting downstream spoken language processing tasks. However, the approach has been less explored in speech synthesis of tonal languages like Mandarin Chinese. Our preliminary experiments on Chinese speech synthesis reveal the issue of "tone shift", where a synthesized speech utterance contains correct base syllables but incorrect tones. To address the issue, we propose the ToneUnit framework, which leverages annotated data with tone labels as CTC supervision to learn tone-aware discrete speech units for Mandarin Chinese speech. Our findings indicate that the discrete units acquired through the TonUnit resolve the "tone shift" issue in synthesized Chinese speech and yield favorable results in English synthesis. Moreover, the experimental results suggest that finite scalar quantization enhances the effectiveness of ToneUnit. Notably, ToneUnit can work effectively even with minimal annotated data.
A Parameter-efficient Language Extension Framework for Multilingual ASR
Jun 10, 2024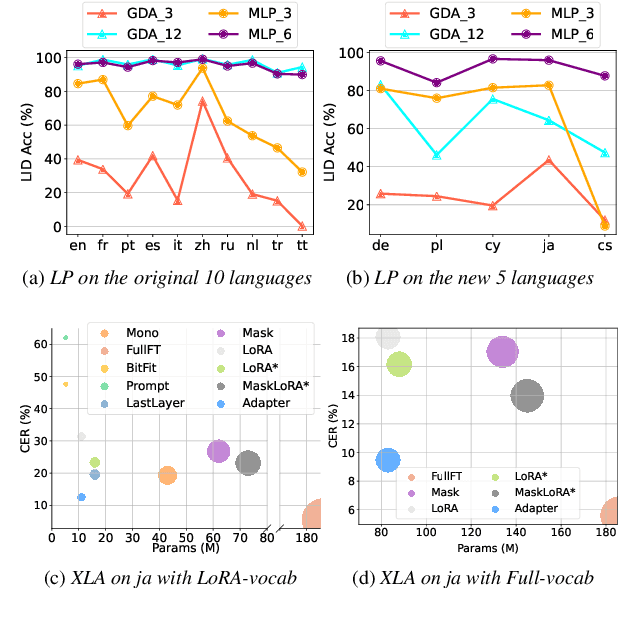
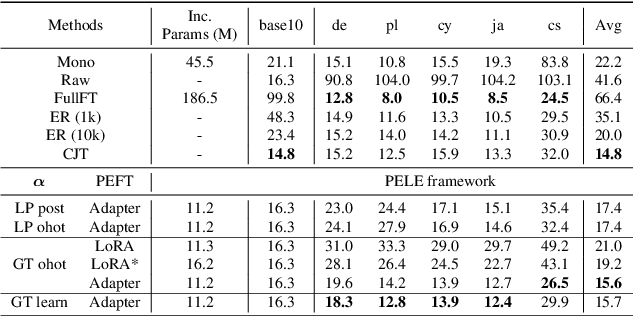
Covering all languages with a multilingual speech recognition model (MASR) is very difficult. Performing language extension on top of an existing MASR is a desirable choice. In this study, the MASR continual learning problem is probabilistically decomposed into language identity prediction (LP) and cross-lingual adaptation (XLA) sub-problems. Based on this, we propose an architecture-based framework for language extension that can fundamentally solve catastrophic forgetting, debudded as PELE. PELE is designed to be parameter-efficient, incrementally incorporating an add-on module to adapt to a new language. Specifically, different parameter-efficient fine-tuning (PEFT) modules and their variants are explored as potential candidates to perform XLA. Experiments are carried out on 5 new languages with a wide range of low-resourced data sizes. The best-performing PEFT candidate can achieve satisfactory performance across all languages and demonstrates superiority in three of five languages over the continual joint learning setting. Notably, PEFT methods focusing on weight parameters or input features are revealed to be limited in performance, showing significantly inferior extension capabilities compared to inserting a lightweight module in between layers such as an Adapter.
LUPET: Incorporating Hierarchical Information Path into Multilingual ASR
Jan 08, 2024



Many factors have separately shown their effectiveness on improving multilingual ASR. They include language identity (LID) and phoneme information, language-specific processing modules and cross-lingual self-supervised speech representation, etc. However, few studies work on synergistically combining them to contribute a unified solution, which still remains an open question. To this end, a novel view to incorporate hierarchical information path LUPET into multilingual ASR is proposed. The LUPET is a path encoding multiple information in different granularity from shallow to deep encoder layers. Early information in this path is beneficial for deriving later occurred information. Specifically, the input goes from LID prediction to acoustic unit discovery followed by phoneme sharing, and then dynamically routed by mixture-of-expert for final token recognition. Experiments on 10 languages of Common Voice examined the superior performance of LUPET. Importantly, LUPET significantly boosts the recognition on high-resource languages, thus mitigating the compromised phenomenon towards low-resource languages in a multilingual setting.