 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePodEval: A Multimodal Evaluation Framework for Podcast Audio Generation
Oct 01, 2025Recently, an increasing number of multimodal (text and audio) benchmarks have emerged, primarily focusing on evaluating models' understanding capability. However, exploration into assessing generative capabilities remains limited, especially for open-ended long-form content generation. Significant challenges lie in no reference standard answer, no unified evaluation metrics and uncontrollable human judgments. In this work, we take podcast-like audio generation as a starting point and propose PodEval, a comprehensive and well-designed open-source evaluation framework. In this framework: 1) We construct a real-world podcast dataset spanning diverse topics, serving as a reference for human-level creative quality. 2) We introduce a multimodal evaluation strategy and decompose the complex task into three dimensions: text, speech and audio, with different evaluation emphasis on "Content" and "Format". 3) For each modality, we design corresponding evaluation methods, involving both objective metrics and subjective listening test. We leverage representative podcast generation systems (including open-source, close-source, and human-made) in our experiments. The results offer in-depth analysis and insights into podcast generation, demonstrating the effectiveness of PodEval in evaluating open-ended long-form audio. This project is open-source to facilitate public use: https://github.com/yujxx/PodEval.
Probing Speaker-specific Features in Speaker Representations
Jan 09, 2025
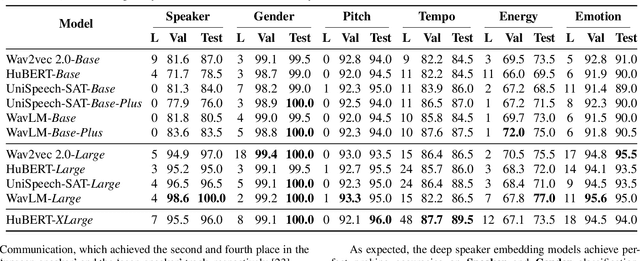
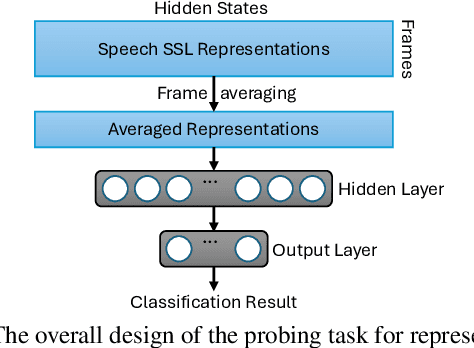
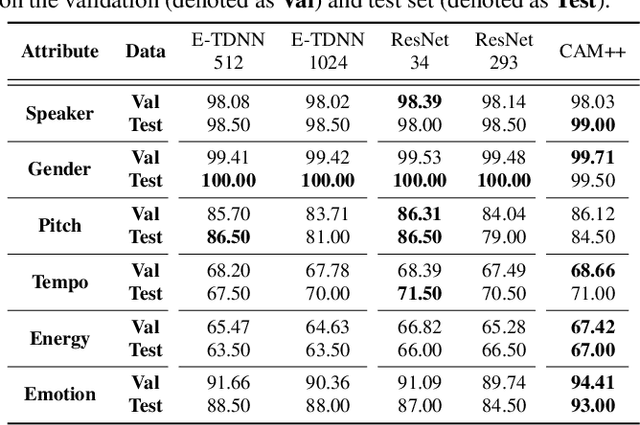
This study explores speaker-specific features encoded in speaker embeddings and intermediate layers of speech self-supervised learning (SSL) models. By utilising a probing method, we analyse features such as pitch, tempo, and energy across prominent speaker embedding models and speech SSL models, including HuBERT, WavLM, and Wav2vec 2.0. The results reveal that speaker embeddings like CAM++ excel in energy classification, while speech SSL models demonstrate superior performance across multiple features due to their hierarchical feature encoding. Intermediate layers effectively capture a mix of acoustic and para-linguistic information, with deeper layers refining these representations. This investigation provides insights into model design and highlights the potential of these representations for downstream applications, such as speaker verification and text-to-speech synthesis, while laying the groundwork for exploring additional features and advanced probing methods.
An Investigation of Reprogramming for Cross-Language Adaptation in Speaker Verification Systems
Nov 18, 2024



Language mismatch is among the most common and challenging domain mismatches in deploying speaker verification (SV) systems. Adversarial reprogramming has shown promising results in cross-language adaptation for SV. The reprogramming is implemented by padding learnable parameters on the two sides of input speech signals. In this paper, we investigate the relationship between the number of padded parameters and the performance of the reprogrammed models. Sufficient experiments are conducted with different scales of SV models and datasets. The results demonstrate that reprogramming consistently improves the performance of cross-language SV, while the improvement is saturated or even degraded when using larger padding lengths. The performance is mainly determined by the capacity of the original SV models instead of the number of padded parameters. The SV models with larger scales have higher upper bounds in performance and can endure longer padding without performance degradation.