 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Stepwise-Enhanced Reasoning Framework for Large Language Models Based on External Subgraph Generation
Dec 29, 2025Large Language Models (LLMs) have achieved strong performance across a wide range of natural language processing tasks in recent years, including machine translation, text generation, and question answering. As their applications extend to increasingly complex scenarios, however, LLMs continue to face challenges in tasks that require deep reasoning and logical inference. In particular, models trained on large scale textual corpora may incorporate noisy or irrelevant information during generation, which can lead to incorrect predictions or outputs that are inconsistent with factual knowledge. To address this limitation, we propose a stepwise reasoning enhancement framework for LLMs based on external subgraph generation, termed SGR. The proposed framework dynamically constructs query relevant subgraphs from external knowledge bases and leverages their semantic structure to guide the reasoning process. By performing reasoning in a step by step manner over structured subgraphs, SGR reduces the influence of noisy information and improves reasoning accuracy. Specifically, the framework first generates an external subgraph tailored to the input query, then guides the model to conduct multi step reasoning grounded in the subgraph, and finally integrates multiple reasoning paths to produce the final answer. Experimental results on multiple benchmark datasets demonstrate that SGR consistently outperforms strong baselines, indicating its effectiveness in enhancing the reasoning capabilities of LLMs.
Multiscale Cross-Modal Mapping of Molecular, Pathologic, and Radiologic Phenotypes in Lipid-Deficient Clear Cell Renal CellCarcinoma
Dec 13, 2025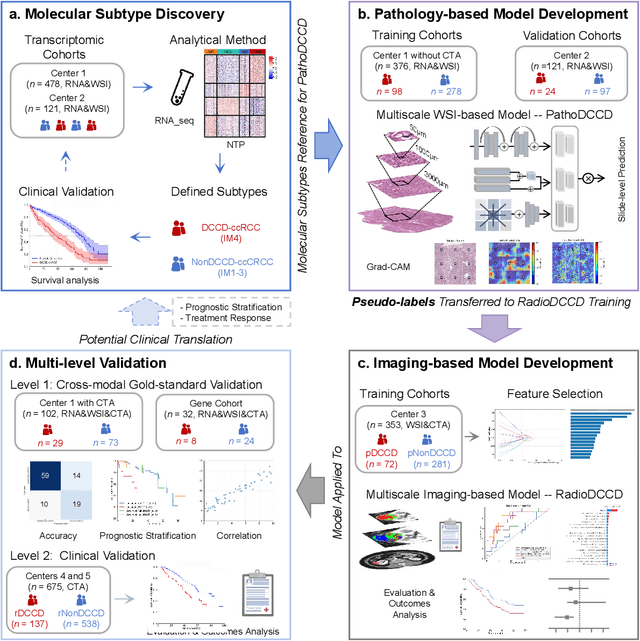
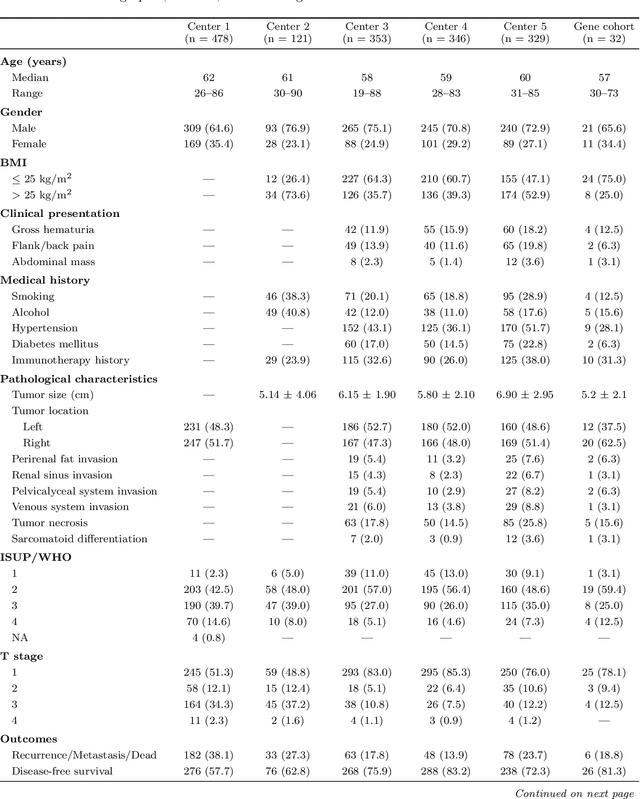
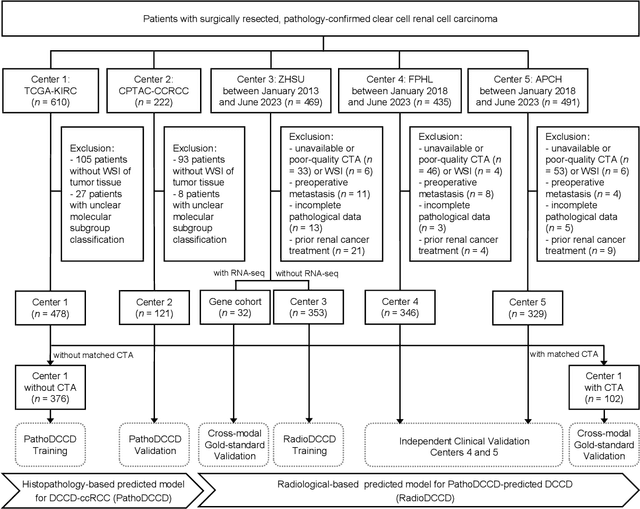
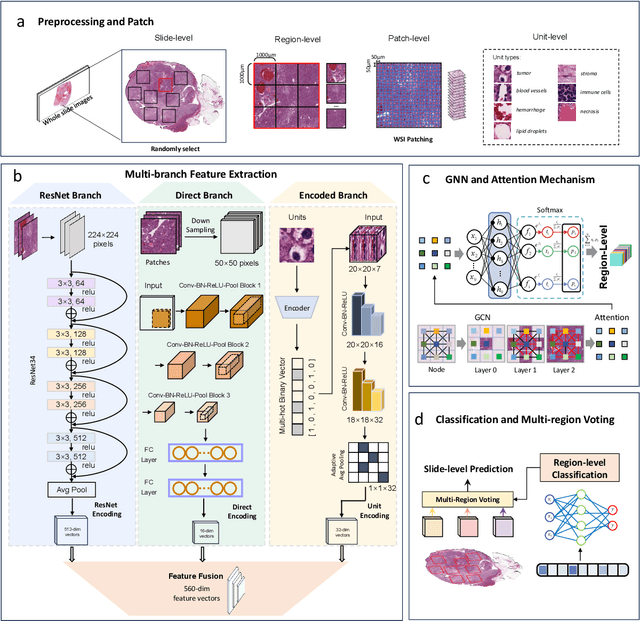
Clear cell renal cell carcinoma (ccRCC) exhibits extensive intratumoral heterogeneity on multiple biological scales, contributing to variable clinical outcomes and limiting the effectiveness of conventional TNM staging, which highlights the urgent need for multiscale integrative analytic frameworks. The lipid-deficient de-clear cell differentiated (DCCD) ccRCC subtype, defined by multi-omics analyses, is associated with adverse outcomes even in early-stage disease. Here, we establish a hierarchical cross-scale framework for the preoperative identification of DCCD-ccRCC. At the highest layer, cross-modal mapping transferred molecular signatures to histological and CT phenotypes, establishing a molecular-to-pathology-to-radiology supervisory bridge. Within this framework, each modality-specific model is designed to mirror the inherent hierarchical structure of tumor biology. PathoDCCD captured multi-scale microscopic features, from cellular morphology and tissue architecture to meso-regional organization. RadioDCCD integrated complementary macroscopic information by combining whole-tumor and its habitat-subregions radiomics with a 2D maximal-section heterogeneity metric. These nested models enabled integrated molecular subtype prediction and clinical risk stratification. Across five cohorts totaling 1,659 patients, PathoDCCD reliably recapitulated molecular subtypes, while RadioDCCD provided reliable preoperative prediction. The consistent predictions identified patients with the poorest clinical outcomes. This cross-scale paradigm unifies molecular biology, computational pathology, and quantitative radiology into a biologically grounded strategy for preoperative noninvasive molecular phenotyping of ccRCC.
PodEval: A Multimodal Evaluation Framework for Podcast Audio Generation
Oct 01, 2025Recently, an increasing number of multimodal (text and audio) benchmarks have emerged, primarily focusing on evaluating models' understanding capability. However, exploration into assessing generative capabilities remains limited, especially for open-ended long-form content generation. Significant challenges lie in no reference standard answer, no unified evaluation metrics and uncontrollable human judgments. In this work, we take podcast-like audio generation as a starting point and propose PodEval, a comprehensive and well-designed open-source evaluation framework. In this framework: 1) We construct a real-world podcast dataset spanning diverse topics, serving as a reference for human-level creative quality. 2) We introduce a multimodal evaluation strategy and decompose the complex task into three dimensions: text, speech and audio, with different evaluation emphasis on "Content" and "Format". 3) For each modality, we design corresponding evaluation methods, involving both objective metrics and subjective listening test. We leverage representative podcast generation systems (including open-source, close-source, and human-made) in our experiments. The results offer in-depth analysis and insights into podcast generation, demonstrating the effectiveness of PodEval in evaluating open-ended long-form audio. This project is open-source to facilitate public use: https://github.com/yujxx/PodEval.
AFT: An Exemplar-Free Class Incremental Learning Method for Environmental Sound Classification
Sep 19, 2025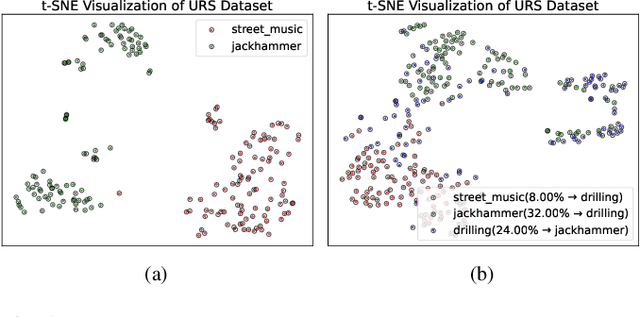
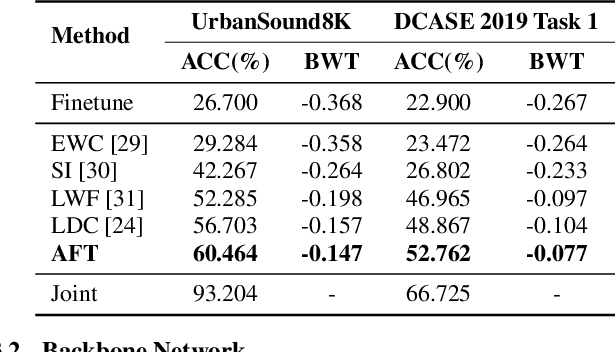
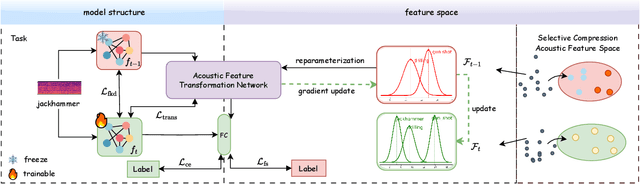
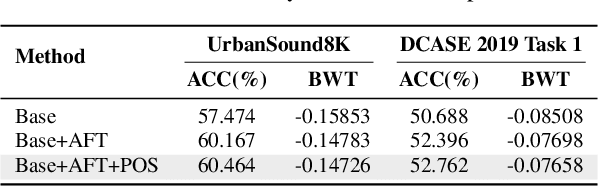
As sounds carry rich information, environmental sound classification (ESC) is crucial for numerous applications such as rare wild animals detection. However, our world constantly changes, asking ESC models to adapt to new sounds periodically. The major challenge here is catastrophic forgetting, where models lose the ability to recognize old sounds when learning new ones. Many methods address this using replay-based continual learning. This could be impractical in scenarios such as data privacy concerns. Exemplar-free methods are commonly used but can distort old features, leading to worse performance. To overcome such limitations, we propose an Acoustic Feature Transformation (AFT) technique that aligns the temporal features of old classes to the new space, including a selectively compressed feature space. AFT mitigates the forgetting of old knowledge without retaining past data. We conducted experiments on two datasets, showing consistent improvements over baseline models with accuracy gains of 3.7\% to 3.9\%.
CronusVLA: Transferring Latent Motion Across Time for Multi-Frame Prediction in Manipulation
Jun 24, 2025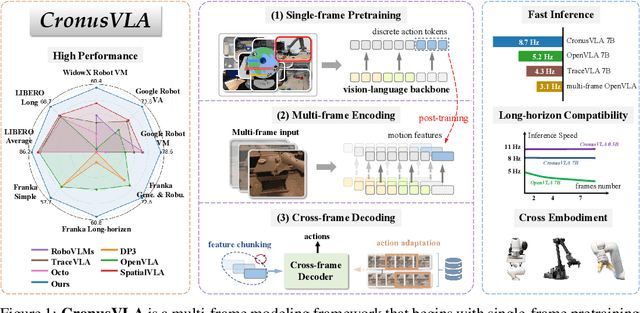
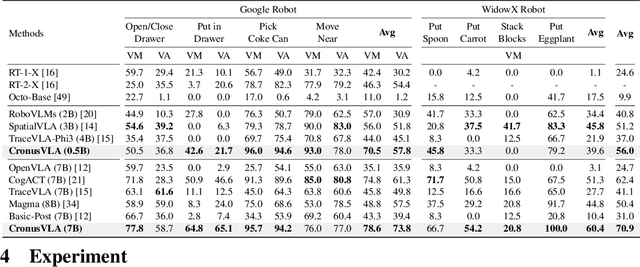
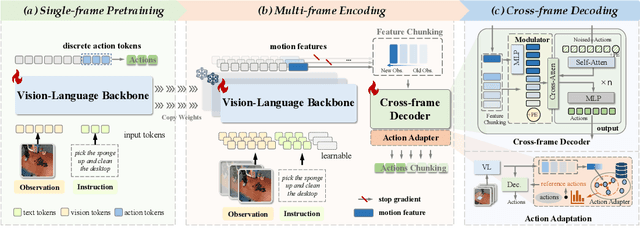
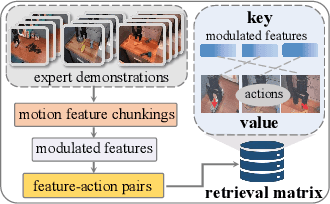
Recent vision-language-action (VLA) models built on pretrained vision-language models (VLMs) have demonstrated strong generalization across manipulation tasks. However, they remain constrained by a single-frame observation paradigm and cannot fully benefit from the motion information offered by aggregated multi-frame historical observations, as the large vision-language backbone introduces substantial computational cost and inference latency. We propose CronusVLA, a unified framework that extends single-frame VLA models to the multi-frame paradigm through an efficient post-training stage. CronusVLA comprises three key components: (1) single-frame pretraining on large-scale embodied datasets with autoregressive action tokens prediction, which establishes an embodied vision-language foundation; (2) multi-frame encoding, adapting the prediction of vision-language backbones from discrete action tokens to motion features during post-training, and aggregating motion features from historical frames into a feature chunking; (3) cross-frame decoding, which maps the feature chunking to accurate actions via a shared decoder with cross-attention. By reducing redundant token computation and caching past motion features, CronusVLA achieves efficient inference. As an application of motion features, we further propose an action adaptation mechanism based on feature-action retrieval to improve model performance during finetuning. CronusVLA achieves state-of-the-art performance on SimplerEnv with 70.9% success rate, and 12.7% improvement over OpenVLA on LIBERO. Real-world Franka experiments also show the strong performance and robustness.
GENMANIP: LLM-driven Simulation for Generalizable Instruction-Following Manipulation
Jun 12, 2025
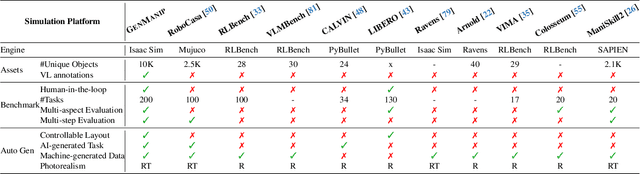

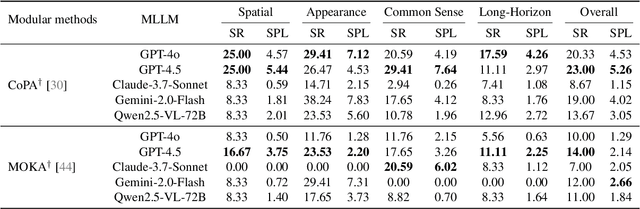
Robotic manipulation in real-world settings remains challenging, especially regarding robust generalization. Existing simulation platforms lack sufficient support for exploring how policies adapt to varied instructions and scenarios. Thus, they lag behind the growing interest in instruction-following foundation models like LLMs, whose adaptability is crucial yet remains underexplored in fair comparisons. To bridge this gap, we introduce GenManip, a realistic tabletop simulation platform tailored for policy generalization studies. It features an automatic pipeline via LLM-driven task-oriented scene graph to synthesize large-scale, diverse tasks using 10K annotated 3D object assets. To systematically assess generalization, we present GenManip-Bench, a benchmark of 200 scenarios refined via human-in-the-loop corrections. We evaluate two policy types: (1) modular manipulation systems integrating foundation models for perception, reasoning, and planning, and (2) end-to-end policies trained through scalable data collection. Results show that while data scaling benefits end-to-end methods, modular systems enhanced with foundation models generalize more effectively across diverse scenarios. We anticipate this platform to facilitate critical insights for advancing policy generalization in realistic conditions. Project Page: https://genmanip.axi404.top/.
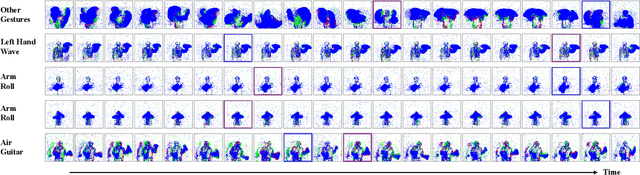
Neuromorphic Sequential Arena: A Benchmark for Neuromorphic Temporal Processing
May 28, 2025Temporal processing is vital for extracting meaningful information from time-varying signals. Recent advancements in Spiking Neural Networks (SNNs) have shown immense promise in efficiently processing these signals. However, progress in this field has been impeded by the lack of effective and standardized benchmarks, which complicates the consistent measurement of technological advancements and limits the practical applicability of SNNs. To bridge this gap, we introduce the Neuromorphic Sequential Arena (NSA), a comprehensive benchmark that offers an effective, versatile, and application-oriented evaluation framework for neuromorphic temporal processing. The NSA includes seven real-world temporal processing tasks from a diverse range of application scenarios, each capturing rich temporal dynamics across multiple timescales. Utilizing NSA, we conduct extensive comparisons of recently introduced spiking neuron models and neural architectures, presenting comprehensive baselines in terms of task performance, training speed, memory usage, and energy efficiency. Our findings emphasize an urgent need for efficient SNN designs that can consistently deliver high performance across tasks with varying temporal complexities while maintaining low computational costs. NSA enables systematic tracking of advancements in neuromorphic algorithm research and paves the way for developing effective and efficient neuromorphic temporal processing systems.
Active Contact Engagement for Aerial Navigation in Unknown Environments with Glass
May 01, 2025Autonomous aerial robots are increasingly being deployed in real-world scenarios, where transparent glass obstacles present significant challenges to reliable navigation. Researchers have investigated the use of non-contact sensors and passive contact-resilient aerial vehicle designs to detect glass surfaces, which are often limited in terms of robustness and efficiency. In this work, we propose a novel approach for robust autonomous aerial navigation in unknown environments with transparent glass obstacles, combining the strengths of both sensor-based and contact-based glass detection. The proposed system begins with the incremental detection and information maintenance about potential glass surfaces using visual sensor measurements. The vehicle then actively engages in touch actions with the visually detected potential glass surfaces using a pair of lightweight contact-sensing modules to confirm or invalidate their presence. Following this, the volumetric map is efficiently updated with the glass surface information and safe trajectories are replanned on the fly to circumvent the glass obstacles. We validate the proposed system through real-world experiments in various scenarios, demonstrating its effectiveness in enabling efficient and robust autonomous aerial navigation in complex real-world environments with glass obstacles.
RoboGround: Robotic Manipulation with Grounded Vision-Language Priors
Apr 30, 2025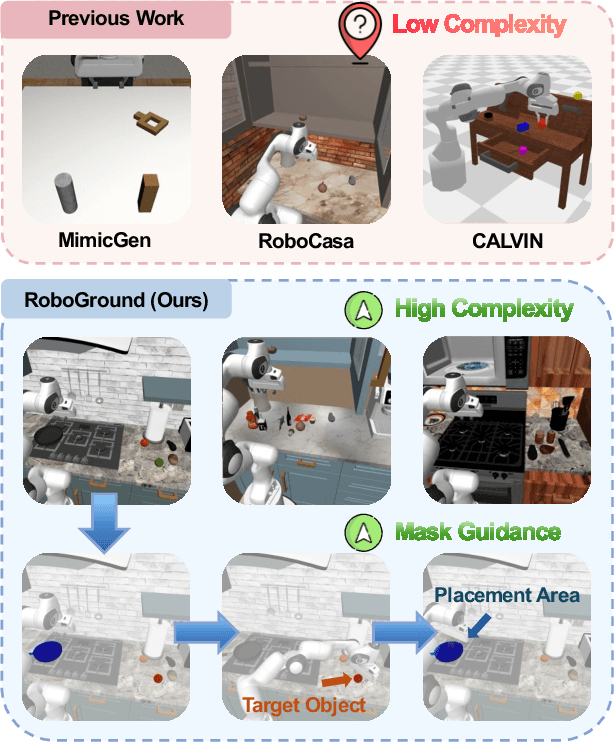

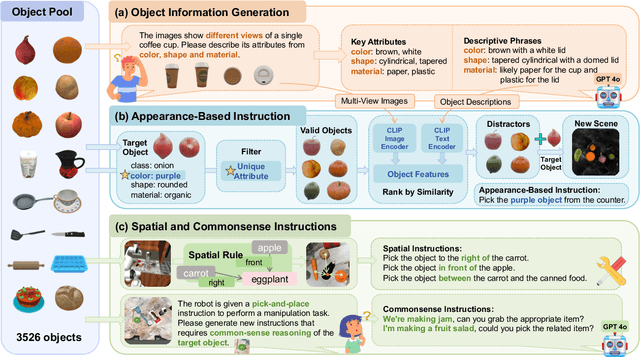
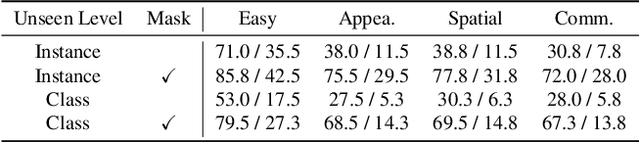
Recent advancements in robotic manipulation have highlighted the potential of intermediate representations for improving policy generalization. In this work, we explore grounding masks as an effective intermediate representation, balancing two key advantages: (1) effective spatial guidance that specifies target objects and placement areas while also conveying information about object shape and size, and (2) broad generalization potential driven by large-scale vision-language models pretrained on diverse grounding datasets. We introduce RoboGround, a grounding-aware robotic manipulation system that leverages grounding masks as an intermediate representation to guide policy networks in object manipulation tasks. To further explore and enhance generalization, we propose an automated pipeline for generating large-scale, simulated data with a diverse set of objects and instructions. Extensive experiments show the value of our dataset and the effectiveness of grounding masks as intermediate guidance, significantly enhancing the generalization abilities of robot policies.
Spiking Neural Networks for Temporal Processing: Status Quo and Future Prospects
Feb 13, 2025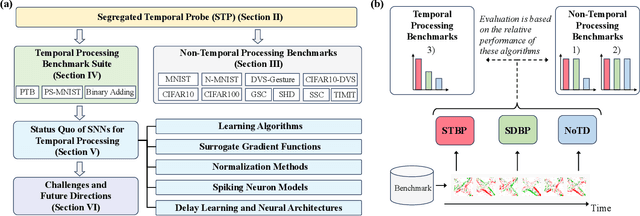

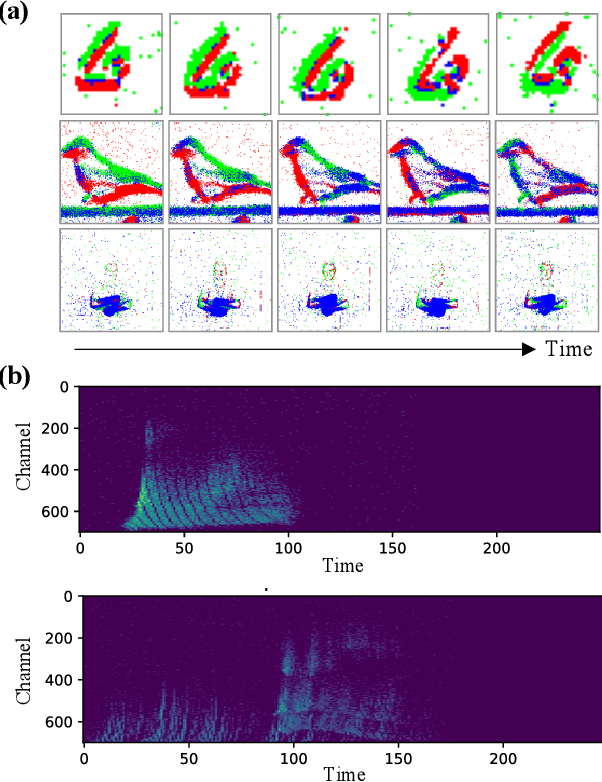
Temporal processing is fundamental for both biological and artificial intelligence systems, as it enables the comprehension of dynamic environments and facilitates timely responses. Spiking Neural Networks (SNNs) excel in handling such data with high efficiency, owing to their rich neuronal dynamics and sparse activity patterns. Given the recent surge in the development of SNNs, there is an urgent need for a comprehensive evaluation of their temporal processing capabilities. In this paper, we first conduct an in-depth assessment of commonly used neuromorphic benchmarks, revealing critical limitations in their ability to evaluate the temporal processing capabilities of SNNs. To bridge this gap, we further introduce a benchmark suite consisting of three temporal processing tasks characterized by rich temporal dynamics across multiple timescales. Utilizing this benchmark suite, we perform a thorough evaluation of recently introduced SNN approaches to elucidate the current status of SNNs in temporal processing. Our findings indicate significant advancements in recently developed spiking neuron models and neural architectures regarding their temporal processing capabilities, while also highlighting a performance gap in handling long-range dependencies when compared to state-of-the-art non-spiking models. Finally, we discuss the key challenges and outline potential avenues for future research.