 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMOD: A Unified EEG Emotion Representation Framework Leveraging V-A Guided Contrastive Learning
Nov 14, 2025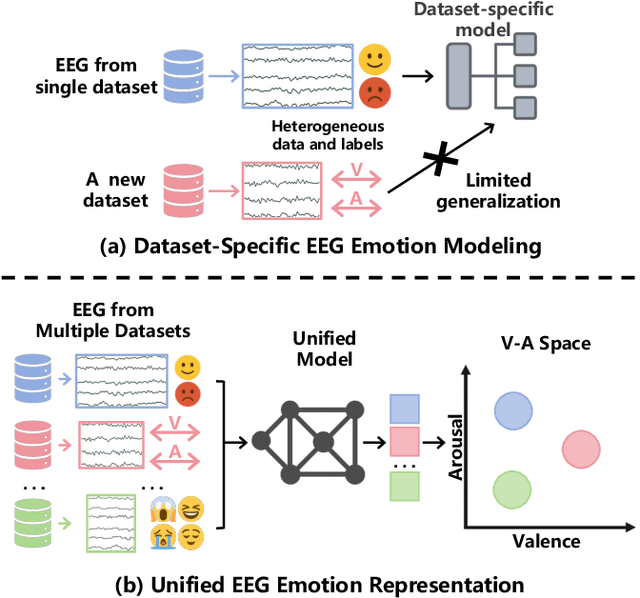



Emotion recognition from EEG signals is essential for affective computing and has been widely explored using deep learning. While recent deep learning approaches have achieved strong performance on single EEG emotion datasets, their generalization across datasets remains limited due to the heterogeneity in annotation schemes and data formats. Existing models typically require dataset-specific architectures tailored to input structure and lack semantic alignment across diverse emotion labels. To address these challenges, we propose EMOD: A Unified EEG Emotion Representation Framework Leveraging Valence-Arousal (V-A) Guided Contrastive Learning. EMOD learns transferable and emotion-aware representations from heterogeneous datasets by bridging both semantic and structural gaps. Specifically, we project discrete and continuous emotion labels into a unified V-A space and formulate a soft-weighted supervised contrastive loss that encourages emotionally similar samples to cluster in the latent space. To accommodate variable EEG formats, EMOD employs a flexible backbone comprising a Triple-Domain Encoder followed by a Spatial-Temporal Transformer, enabling robust extraction and integration of temporal, spectral, and spatial features. We pretrain EMOD on 8 public EEG datasets and evaluate its performance on three benchmark datasets. Experimental results show that EMOD achieves the state-of-the-art performance, demonstrating strong adaptability and generalization across diverse EEG-based emotion recognition scenarios.
EEGAgent: A Unified Framework for Automated EEG Analysis Using Large Language Models
Nov 13, 2025Scalable and generalizable analysis of brain activity is essential for advancing both clinical diagnostics and cognitive research. Electroencephalography (EEG), a non-invasive modality with high temporal resolution, has been widely used for brain states analysis. However, most existing EEG models are usually tailored for individual specific tasks, limiting their utility in realistic scenarios where EEG analysis often involves multi-task and continuous reasoning. In this work, we introduce EEGAgent, a general-purpose framework that leverages large language models (LLMs) to schedule and plan multiple tools to automatically complete EEG-related tasks. EEGAgent is capable of performing the key functions: EEG basic information perception, spatiotemporal EEG exploration, EEG event detection, interaction with users, and EEG report generation. To realize these capabilities, we design a toolbox composed of different tools for EEG preprocessing, feature extraction, event detection, etc. These capabilities were evaluated on public datasets, and our EEGAgent can support flexible and interpretable EEG analysis, highlighting its potential for real-world clinical applications.
Edge Intelligence with Spiking Neural Networks
Jul 18, 2025The convergence of artificial intelligence and edge computing has spurred growing interest in enabling intelligent services directly on resource-constrained devices. While traditional deep learning models require significant computational resources and centralized data management, the resulting latency, bandwidth consumption, and privacy concerns have exposed critical limitations in cloud-centric paradigms. Brain-inspired computing, particularly Spiking Neural Networks (SNNs), offers a promising alternative by emulating biological neuronal dynamics to achieve low-power, event-driven computation. This survey provides a comprehensive overview of Edge Intelligence based on SNNs (EdgeSNNs), examining their potential to address the challenges of on-device learning, inference, and security in edge scenarios. We present a systematic taxonomy of EdgeSNN foundations, encompassing neuron models, learning algorithms, and supporting hardware platforms. Three representative practical considerations of EdgeSNN are discussed in depth: on-device inference using lightweight SNN models, resource-aware training and updating under non-stationary data conditions, and secure and privacy-preserving issues. Furthermore, we highlight the limitations of evaluating EdgeSNNs on conventional hardware and introduce a dual-track benchmarking strategy to support fair comparisons and hardware-aware optimization. Through this study, we aim to bridge the gap between brain-inspired learning and practical edge deployment, offering insights into current advancements, open challenges, and future research directions. To the best of our knowledge, this is the first dedicated and comprehensive survey on EdgeSNNs, providing an essential reference for researchers and practitioners working at the intersection of neuromorphic computing and edge intelligence.
Spiking Neural Networks with Temporal Attention-Guided Adaptive Fusion for imbalanced Multi-modal Learning
May 20, 2025Multimodal spiking neural networks (SNNs) hold significant potential for energy-efficient sensory processing but face critical challenges in modality imbalance and temporal misalignment. Current approaches suffer from uncoordinated convergence speeds across modalities and static fusion mechanisms that ignore time-varying cross-modal interactions. We propose the temporal attention-guided adaptive fusion framework for multimodal SNNs with two synergistic innovations: 1) The Temporal Attention-guided Adaptive Fusion (TAAF) module that dynamically assigns importance scores to fused spiking features at each timestep, enabling hierarchical integration of temporally heterogeneous spike-based features; 2) The temporal adaptive balanced fusion loss that modulates learning rates per modality based on the above attention scores, preventing dominant modalities from monopolizing optimization. The proposed framework implements adaptive fusion, especially in the temporal dimension, and alleviates the modality imbalance during multimodal learning, mimicking cortical multisensory integration principles. Evaluations on CREMA-D, AVE, and EAD datasets demonstrate state-of-the-art performance (77.55\%, 70.65\% and 97.5\%accuracy, respectively) with energy efficiency. The system resolves temporal misalignment through learnable time-warping operations and faster modality convergence coordination than baseline SNNs. This work establishes a new paradigm for temporally coherent multimodal learning in neuromorphic systems, bridging the gap between biological sensory processing and efficient machine intelligence.
Bidirectional Distillation: A Mixed-Play Framework for Multi-Agent Generalizable Behaviors
May 16, 2025Population-population generalization is a challenging problem in multi-agent reinforcement learning (MARL), particularly when agents encounter unseen co-players. However, existing self-play-based methods are constrained by the limitation of inside-space generalization. In this study, we propose Bidirectional Distillation (BiDist), a novel mixed-play framework, to overcome this limitation in MARL. BiDist leverages knowledge distillation in two alternating directions: forward distillation, which emulates the historical policies' space and creates an implicit self-play, and reverse distillation, which systematically drives agents towards novel distributions outside the known policy space in a non-self-play manner. In addition, BiDist operates as a concise and efficient solution without the need for the complex and costly storage of past policies. We provide both theoretical analysis and empirical evidence to support BiDist's effectiveness. Our results highlight its remarkable generalization ability across a variety of cooperative, competitive, and social dilemma tasks, and reveal that BiDist significantly diversifies the policy distribution space. We also present comprehensive ablation studies to reinforce BiDist's effectiveness and key success factors. Source codes are available in the supplementary material.
Human-like Cognitive Generalization for Large Models via Brain-in-the-loop Supervision
May 14, 2025Recent advancements in deep neural networks (DNNs), particularly large-scale language models, have demonstrated remarkable capabilities in image and natural language understanding. Although scaling up model parameters with increasing volume of training data has progressively improved DNN capabilities, achieving complex cognitive abilities - such as understanding abstract concepts, reasoning, and adapting to novel scenarios, which are intrinsic to human cognition - remains a major challenge. In this study, we show that brain-in-the-loop supervised learning, utilizing a small set of brain signals, can effectively transfer human conceptual structures to DNNs, significantly enhancing their comprehension of abstract and even unseen concepts. Experimental results further indicate that the enhanced cognitive capabilities lead to substantial performance gains in challenging tasks, including few-shot/zero-shot learning and out-of-distribution recognition, while also yielding highly interpretable concept representations. These findings highlight that human-in-the-loop supervision can effectively augment the complex cognitive abilities of large models, offering a promising pathway toward developing more human-like cognitive abilities in artificial systems.
Hybrid Spiking Vision Transformer for Object Detection with Event Cameras
May 12, 2025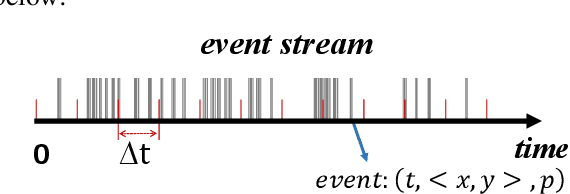
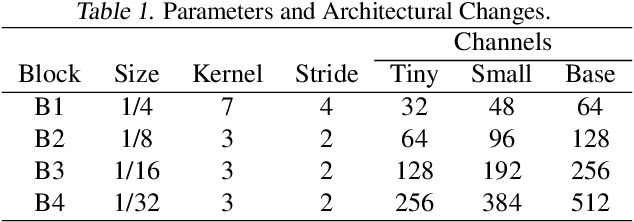

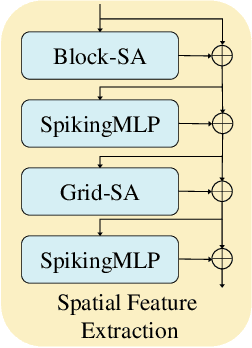
Event-based object detection has gained increasing attention due to its advantages such as high temporal resolution, wide dynamic range, and asynchronous address-event representation. Leveraging these advantages, Spiking Neural Networks (SNNs) have emerged as a promising approach, offering low energy consumption and rich spatiotemporal dynamics. To further enhance the performance of event-based object detection, this study proposes a novel hybrid spike vision Transformer (HsVT) model. The HsVT model integrates a spatial feature extraction module to capture local and global features, and a temporal feature extraction module to model time dependencies and long-term patterns in event sequences. This combination enables HsVT to capture spatiotemporal features, improving its capability to handle complex event-based object detection tasks. To support research in this area, we developed and publicly released The Fall Detection Dataset as a benchmark for event-based object detection tasks. This dataset, captured using an event-based camera, ensures facial privacy protection and reduces memory usage due to the event representation format. We evaluated the HsVT model on GEN1 and Fall Detection datasets across various model sizes. Experimental results demonstrate that HsVT achieves significant performance improvements in event detection with fewer parameters.
TS-SNN: Temporal Shift Module for Spiking Neural Networks
May 08, 2025Spiking Neural Networks (SNNs) are increasingly recognized for their biological plausibility and energy efficiency, positioning them as strong alternatives to Artificial Neural Networks (ANNs) in neuromorphic computing applications. SNNs inherently process temporal information by leveraging the precise timing of spikes, but balancing temporal feature utilization with low energy consumption remains a challenge. In this work, we introduce Temporal Shift module for Spiking Neural Networks (TS-SNN), which incorporates a novel Temporal Shift (TS) module to integrate past, present, and future spike features within a single timestep via a simple yet effective shift operation. A residual combination method prevents information loss by integrating shifted and original features. The TS module is lightweight, requiring only one additional learnable parameter, and can be seamlessly integrated into existing architectures with minimal additional computational cost. TS-SNN achieves state-of-the-art performance on benchmarks like CIFAR-10 (96.72\%), CIFAR-100 (80.28\%), and ImageNet (70.61\%) with fewer timesteps, while maintaining low energy consumption. This work marks a significant step forward in developing efficient and accurate SNN architectures.
Spiking Neural Networks for Temporal Processing: Status Quo and Future Prospects
Feb 13, 2025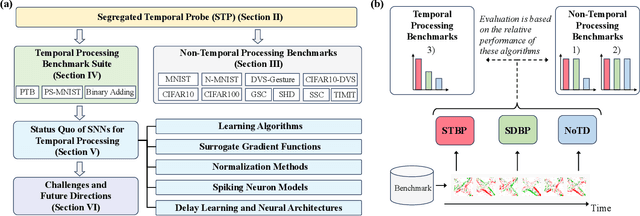

Temporal processing is fundamental for both biological and artificial intelligence systems, as it enables the comprehension of dynamic environments and facilitates timely responses. Spiking Neural Networks (SNNs) excel in handling such data with high efficiency, owing to their rich neuronal dynamics and sparse activity patterns. Given the recent surge in the development of SNNs, there is an urgent need for a comprehensive evaluation of their temporal processing capabilities. In this paper, we first conduct an in-depth assessment of commonly used neuromorphic benchmarks, revealing critical limitations in their ability to evaluate the temporal processing capabilities of SNNs. To bridge this gap, we further introduce a benchmark suite consisting of three temporal processing tasks characterized by rich temporal dynamics across multiple timescales. Utilizing this benchmark suite, we perform a thorough evaluation of recently introduced SNN approaches to elucidate the current status of SNNs in temporal processing. Our findings indicate significant advancements in recently developed spiking neuron models and neural architectures regarding their temporal processing capabilities, while also highlighting a performance gap in handling long-range dependencies when compared to state-of-the-art non-spiking models. Finally, we discuss the key challenges and outline potential avenues for future research.
CausalCOMRL: Context-Based Offline Meta-Reinforcement Learning with Causal Representation
Feb 03, 2025



Context-based offline meta-reinforcement learning (OMRL) methods have achieved appealing success by leveraging pre-collected offline datasets to develop task representations that guide policy learning. However, current context-based OMRL methods often introduce spurious correlations, where task components are incorrectly correlated due to confounders. These correlations can degrade policy performance when the confounders in the test task differ from those in the training task. To address this problem, we propose CausalCOMRL, a context-based OMRL method that integrates causal representation learning. This approach uncovers causal relationships among the task components and incorporates the causal relationships into task representations, enhancing the generalizability of RL agents. We further improve the distinction of task representations from different tasks by using mutual information optimization and contrastive learning. Utilizing these causal task representations, we employ SAC to optimize policies on meta-RL benchmarks. Experimental results show that CausalCOMRL achieves better performance than other methods on most benchmarks.