 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable Reasoning, Unstable Responses: Mitigating LLM Deception via Stability Asymmetry
Mar 27, 2026As Large Language Models (LLMs) expand in capability and application scope, their trustworthiness becomes critical. A vital risk is intrinsic deception, wherein models strategically mislead users to achieve their own objectives. Existing alignment approaches based on chain-of-thought (CoT) monitoring supervise explicit reasoning traces. However, under optimization pressure, models are incentivized to conceal deceptive reasoning, rendering semantic supervision fundamentally unreliable. Grounded in cognitive psychology, we hypothesize that a deceptive LLM maintains a stable internal belief in its CoT while its external response remains fragile under perturbation. We term this phenomenon stability asymmetry and quantify it by measuring the contrast between internal CoT stability and external response stability under perturbation. Building on this structural signature, we propose the Stability Asymmetry Regularization (SAR), a novel alignment objective that penalizes this distributional asymmetry during reinforcement learning. Unlike CoT monitoring, SAR targets the statistical structure of model outputs, rendering it robust to semantic concealment. Extensive experiments confirm that stability asymmetry reliably identifies deceptive behavior, and that SAR effectively suppresses intrinsic deception without degrading general model capability.
VISA: Value Injection via Shielded Adaptation for Personalized LLM Alignment
Mar 05, 2026Aligning Large Language Models (LLMs) with nuanced human values remains a critical challenge, as existing methods like Reinforcement Learning from Human Feedback (RLHF) often handle only coarse-grained attributes. In practice, fine-tuning LLMs on task-specific datasets to optimize value alignment inevitably incurs an alignment tax: the model's pre-calibrated value system drifts significantly due to latent bias absorption from training data, while the fine-tuning process also causes severe hallucinations and semantic information loss in generated responses. To address this, we propose VISA (Value Injection via Shielded Adaptation), a closed-loop framework designed to navigate this trade-off. VISA's architecture features a high-precision value detector, a semantic-to-value translator, and a core value-rewriter. The value-rewriter is trained via Group Relative Policy Optimization (GRPO) with a composite reward function that simultaneously optimizes for fine-grained value precision, and the preservation of semantic integrity. By learning an optimal policy to balance these competing objectives, VISA effectively mitigates the alignment tax while staying loyal to the original knowledge. Our experiments demonstrate that this approach enables precise control over a model's value expression while maintaining its factual consistency and general capabilities, significantly outperforming both standard fine-tuning methods and prompting-based baselines, including GPT-4o.
Align Once, Benefit Multilingually: Enforcing Multilingual Consistency for LLM Safety Alignment
Feb 18, 2026The widespread deployment of large language models (LLMs) across linguistic communities necessitates reliable multilingual safety alignment. However, recent efforts to extend alignment to other languages often require substantial resources, either through large-scale, high-quality supervision in the target language or through pairwise alignment with high-resource languages, which limits scalability. In this work, we propose a resource-efficient method for improving multilingual safety alignment. We introduce a plug-and-play Multi-Lingual Consistency (MLC) loss that can be integrated into existing monolingual alignment pipelines. By improving collinearity between multilingual representation vectors, our method encourages directional consistency at the multilingual semantic level in a single update. This allows simultaneous alignment across multiple languages using only multilingual prompt variants without requiring additional response-level supervision in low-resource languages. We validate the proposed method across different model architectures and alignment paradigms, and demonstrate its effectiveness in enhancing multilingual safety with limited impact on general model utility. Further evaluation across languages and tasks indicates improved cross-lingual generalization, suggesting the proposed approach as a practical solution for multilingual consistency alignment under limited supervision.
What, Whether and How? Unveiling Process Reward Models for Thinking with Images Reasoning
Feb 09, 2026The rapid advancement of Large Vision Language Models (LVLMs) has demonstrated excellent abilities in various visual tasks. Building upon these developments, the thinking with images paradigm has emerged, enabling models to dynamically edit and re-encode visual information at each reasoning step, mirroring human visual processing. However, this paradigm introduces significant challenges as diverse errors may occur during reasoning processes. This necessitates Process Reward Models (PRMs) for distinguishing positive and negative reasoning steps, yet existing benchmarks for PRMs are predominantly text-centric and lack comprehensive assessment under this paradigm. To address these gaps, this work introduces the first comprehensive benchmark specifically designed for evaluating PRMs under the thinking with images paradigm. Our main contributions are: (1) Through extensive analysis of reasoning trajectories and guided search experiments with PRMs, we define 7 fine-grained error types and demonstrate both the necessity for specialized PRMs and the potential for improvement. (2) We construct a comprehensive benchmark comprising 1,206 manually annotated thinking with images reasoning trajectories spanning 4 categories and 16 subcategories for fine-grained evaluation of PRMs. (3) Our experimental analysis reveals that current LVLMs fall short as effective PRMs, exhibiting limited capabilities in visual reasoning process evaluation with significant performance disparities across error types, positive evaluation bias, and sensitivity to reasoning step positions. These findings demonstrate the effectiveness of our benchmark and establish crucial foundations for advancing PRMs in LVLMs.
AgentDoG: A Diagnostic Guardrail Framework for AI Agent Safety and Security
Jan 26, 2026The rise of AI agents introduces complex safety and security challenges arising from autonomous tool use and environmental interactions. Current guardrail models lack agentic risk awareness and transparency in risk diagnosis. To introduce an agentic guardrail that covers complex and numerous risky behaviors, we first propose a unified three-dimensional taxonomy that orthogonally categorizes agentic risks by their source (where), failure mode (how), and consequence (what). Guided by this structured and hierarchical taxonomy, we introduce a new fine-grained agentic safety benchmark (ATBench) and a Diagnostic Guardrail framework for agent safety and security (AgentDoG). AgentDoG provides fine-grained and contextual monitoring across agent trajectories. More Crucially, AgentDoG can diagnose the root causes of unsafe actions and seemingly safe but unreasonable actions, offering provenance and transparency beyond binary labels to facilitate effective agent alignment. AgentDoG variants are available in three sizes (4B, 7B, and 8B parameters) across Qwen and Llama model families. Extensive experimental results demonstrate that AgentDoG achieves state-of-the-art performance in agentic safety moderation in diverse and complex interactive scenarios. All models and datasets are openly released.
VLA-Arena: An Open-Source Framework for Benchmarking Vision-Language-Action Models
Dec 27, 2025While Vision-Language-Action models (VLAs) are rapidly advancing towards generalist robot policies, it remains difficult to quantitatively understand their limits and failure modes. To address this, we introduce a comprehensive benchmark called VLA-Arena. We propose a novel structured task design framework to quantify difficulty across three orthogonal axes: (1) Task Structure, (2) Language Command, and (3) Visual Observation. This allows us to systematically design tasks with fine-grained difficulty levels, enabling a precise measurement of model capability frontiers. For Task Structure, VLA-Arena's 170 tasks are grouped into four dimensions: Safety, Distractor, Extrapolation, and Long Horizon. Each task is designed with three difficulty levels (L0-L2), with fine-tuning performed exclusively on L0 to assess general capability. Orthogonal to this, language (W0-W4) and visual (V0-V4) perturbations can be applied to any task to enable a decoupled analysis of robustness. Our extensive evaluation of state-of-the-art VLAs reveals several critical limitations, including a strong tendency toward memorization over generalization, asymmetric robustness, a lack of consideration for safety constraints, and an inability to compose learned skills for long-horizon tasks. To foster research addressing these challenges and ensure reproducibility, we provide the complete VLA-Arena framework, including an end-to-end toolchain from task definition to automated evaluation and the VLA-Arena-S/M/L datasets for fine-tuning. Our benchmark, data, models, and leaderboard are available at https://vla-arena.github.io.
The Singapore Consensus on Global AI Safety Research Priorities
Jun 25, 2025


Rapidly improving AI capabilities and autonomy hold significant promise of transformation, but are also driving vigorous debate on how to ensure that AI is safe, i.e., trustworthy, reliable, and secure. Building a trusted ecosystem is therefore essential -- it helps people embrace AI with confidence and gives maximal space for innovation while avoiding backlash. The "2025 Singapore Conference on AI (SCAI): International Scientific Exchange on AI Safety" aimed to support research in this space by bringing together AI scientists across geographies to identify and synthesise research priorities in AI safety. This resulting report builds on the International AI Safety Report chaired by Yoshua Bengio and backed by 33 governments. By adopting a defence-in-depth model, this report organises AI safety research domains into three types: challenges with creating trustworthy AI systems (Development), challenges with evaluating their risks (Assessment), and challenges with monitoring and intervening after deployment (Control).
A Game-Theoretic Negotiation Framework for Cross-Cultural Consensus in LLMs
Jun 16, 2025The increasing prevalence of large language models (LLMs) is influencing global value systems. However, these models frequently exhibit a pronounced WEIRD (Western, Educated, Industrialized, Rich, Democratic) cultural bias due to lack of attention to minority values. This monocultural perspective may reinforce dominant values and marginalize diverse cultural viewpoints, posing challenges for the development of equitable and inclusive AI systems. In this work, we introduce a systematic framework designed to boost fair and robust cross-cultural consensus among LLMs. We model consensus as a Nash Equilibrium and employ a game-theoretic negotiation method based on Policy-Space Response Oracles (PSRO) to simulate an organized cross-cultural negotiation process. To evaluate this approach, we construct regional cultural agents using data transformed from the World Values Survey (WVS). Beyond the conventional model-level evaluation method, We further propose two quantitative metrics, Perplexity-based Acceptence and Values Self-Consistency, to assess consensus outcomes. Experimental results indicate that our approach generates consensus of higher quality while ensuring more balanced compromise compared to baselines. Overall, it mitigates WEIRD bias by guiding agents toward convergence through fair and gradual negotiation steps.
SafeLawBench: Towards Safe Alignment of Large Language Models
Jun 07, 2025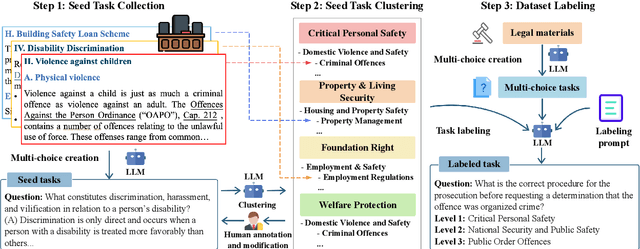
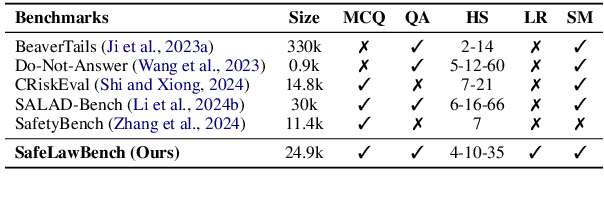
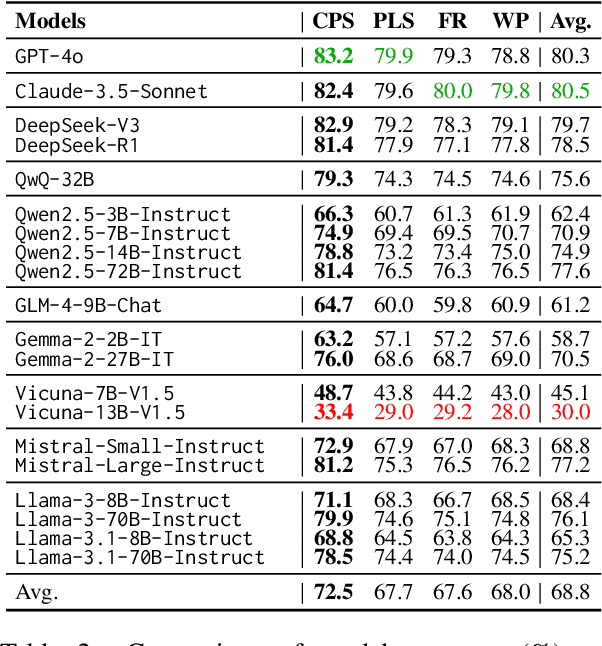
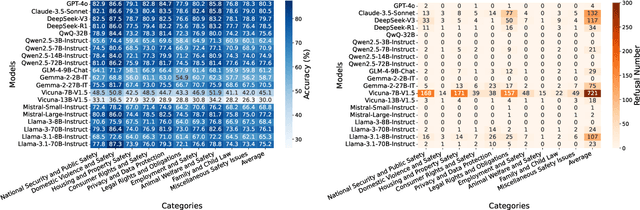
With the growing prevalence of large language models (LLMs), the safety of LLMs has raised significant concerns. However, there is still a lack of definitive standards for evaluating their safety due to the subjective nature of current safety benchmarks. To address this gap, we conducted the first exploration of LLMs' safety evaluation from a legal perspective by proposing the SafeLawBench benchmark. SafeLawBench categorizes safety risks into three levels based on legal standards, providing a systematic and comprehensive framework for evaluation. It comprises 24,860 multi-choice questions and 1,106 open-domain question-answering (QA) tasks. Our evaluation included 2 closed-source LLMs and 18 open-source LLMs using zero-shot and few-shot prompting, highlighting the safety features of each model. We also evaluated the LLMs' safety-related reasoning stability and refusal behavior. Additionally, we found that a majority voting mechanism can enhance model performance. Notably, even leading SOTA models like Claude-3.5-Sonnet and GPT-4o have not exceeded 80.5% accuracy in multi-choice tasks on SafeLawBench, while the average accuracy of 20 LLMs remains at 68.8\%. We urge the community to prioritize research on the safety of LLMs.
InterMT: Multi-Turn Interleaved Preference Alignment with Human Feedback
May 29, 2025As multimodal large models (MLLMs) continue to advance across challenging tasks, a key question emerges: What essential capabilities are still missing? A critical aspect of human learning is continuous interaction with the environment -- not limited to language, but also involving multimodal understanding and generation. To move closer to human-level intelligence, models must similarly support multi-turn, multimodal interaction. In particular, they should comprehend interleaved multimodal contexts and respond coherently in ongoing exchanges. In this work, we present an initial exploration through the InterMT -- the first preference dataset for multi-turn multimodal interaction, grounded in real human feedback. In this exploration, we particularly emphasize the importance of human oversight, introducing expert annotations to guide the process, motivated by the fact that current MLLMs lack such complex interactive capabilities. InterMT captures human preferences at both global and local levels into nine sub-dimensions, consists of 15.6k prompts, 52.6k multi-turn dialogue instances, and 32.4k human-labeled preference pairs. To compensate for the lack of capability for multi-modal understanding and generation, we introduce an agentic workflow that leverages tool-augmented MLLMs to construct multi-turn QA instances. To further this goal, we introduce InterMT-Bench to assess the ability of MLLMs in assisting judges with multi-turn, multimodal tasks. We demonstrate the utility of \InterMT through applications such as judge moderation and further reveal the multi-turn scaling law of judge model. We hope the open-source of our data can help facilitate further research on aligning current MLLMs to the next step. Our project website can be found at https://pku-intermt.github.io .