 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamID-V:Bridging the Image-to-Video Gap for High-Fidelity Face Swapping via Diffusion Transformer
Jan 04, 2026Video Face Swapping (VFS) requires seamlessly injecting a source identity into a target video while meticulously preserving the original pose, expression, lighting, background, and dynamic information. Existing methods struggle to maintain identity similarity and attribute preservation while preserving temporal consistency. To address the challenge, we propose a comprehensive framework to seamlessly transfer the superiority of Image Face Swapping (IFS) to the video domain. We first introduce a novel data pipeline SyncID-Pipe that pre-trains an Identity-Anchored Video Synthesizer and combines it with IFS models to construct bidirectional ID quadruplets for explicit supervision. Building upon paired data, we propose the first Diffusion Transformer-based framework DreamID-V, employing a core Modality-Aware Conditioning module to discriminatively inject multi-model conditions. Meanwhile, we propose a Synthetic-to-Real Curriculum mechanism and an Identity-Coherence Reinforcement Learning strategy to enhance visual realism and identity consistency under challenging scenarios. To address the issue of limited benchmarks, we introduce IDBench-V, a comprehensive benchmark encompassing diverse scenes. Extensive experiments demonstrate DreamID-V outperforms state-of-the-art methods and further exhibits exceptional versatility, which can be seamlessly adapted to various swap-related tasks.
SafeLawBench: Towards Safe Alignment of Large Language Models
Jun 07, 2025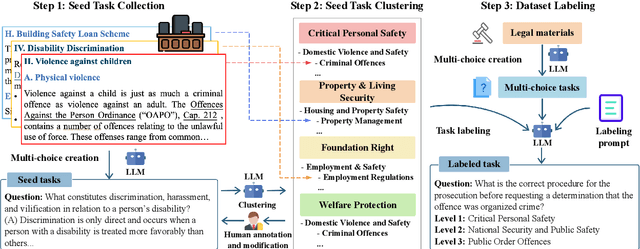
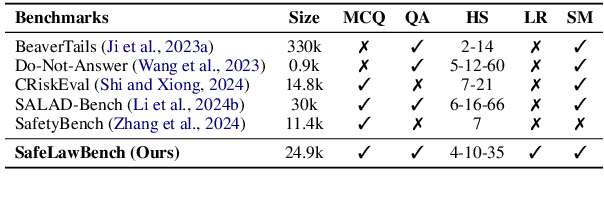
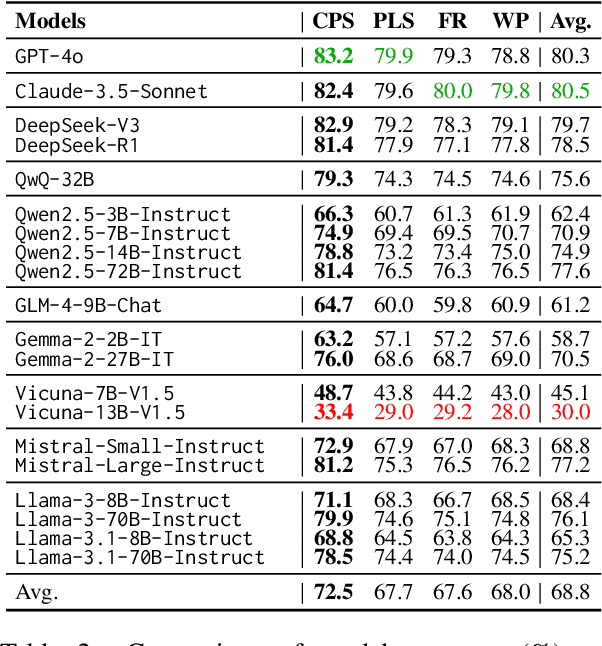
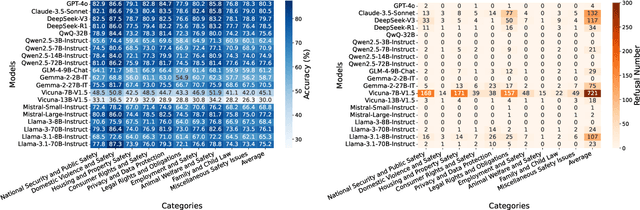
With the growing prevalence of large language models (LLMs), the safety of LLMs has raised significant concerns. However, there is still a lack of definitive standards for evaluating their safety due to the subjective nature of current safety benchmarks. To address this gap, we conducted the first exploration of LLMs' safety evaluation from a legal perspective by proposing the SafeLawBench benchmark. SafeLawBench categorizes safety risks into three levels based on legal standards, providing a systematic and comprehensive framework for evaluation. It comprises 24,860 multi-choice questions and 1,106 open-domain question-answering (QA) tasks. Our evaluation included 2 closed-source LLMs and 18 open-source LLMs using zero-shot and few-shot prompting, highlighting the safety features of each model. We also evaluated the LLMs' safety-related reasoning stability and refusal behavior. Additionally, we found that a majority voting mechanism can enhance model performance. Notably, even leading SOTA models like Claude-3.5-Sonnet and GPT-4o have not exceeded 80.5% accuracy in multi-choice tasks on SafeLawBench, while the average accuracy of 20 LLMs remains at 68.8\%. We urge the community to prioritize research on the safety of LLMs.
DreamID: High-Fidelity and Fast diffusion-based Face Swapping via Triplet ID Group Learning
Apr 20, 2025In this paper, we introduce DreamID, a diffusion-based face swapping model that achieves high levels of ID similarity, attribute preservation, image fidelity, and fast inference speed. Unlike the typical face swapping training process, which often relies on implicit supervision and struggles to achieve satisfactory results. DreamID establishes explicit supervision for face swapping by constructing Triplet ID Group data, significantly enhancing identity similarity and attribute preservation. The iterative nature of diffusion models poses challenges for utilizing efficient image-space loss functions, as performing time-consuming multi-step sampling to obtain the generated image during training is impractical. To address this issue, we leverage the accelerated diffusion model SD Turbo, reducing the inference steps to a single iteration, enabling efficient pixel-level end-to-end training with explicit Triplet ID Group supervision. Additionally, we propose an improved diffusion-based model architecture comprising SwapNet, FaceNet, and ID Adapter. This robust architecture fully unlocks the power of the Triplet ID Group explicit supervision. Finally, to further extend our method, we explicitly modify the Triplet ID Group data during training to fine-tune and preserve specific attributes, such as glasses and face shape. Extensive experiments demonstrate that DreamID outperforms state-of-the-art methods in terms of identity similarity, pose and expression preservation, and image fidelity. Overall, DreamID achieves high-quality face swapping results at 512*512 resolution in just 0.6 seconds and performs exceptionally well in challenging scenarios such as complex lighting, large angles, and occlusions.
AnyDressing: Customizable Multi-Garment Virtual Dressing via Latent Diffusion Models
Dec 05, 2024



Recent advances in garment-centric image generation from text and image prompts based on diffusion models are impressive. However, existing methods lack support for various combinations of attire, and struggle to preserve the garment details while maintaining faithfulness to the text prompts, limiting their performance across diverse scenarios. In this paper, we focus on a new task, i.e., Multi-Garment Virtual Dressing, and we propose a novel AnyDressing method for customizing characters conditioned on any combination of garments and any personalized text prompts. AnyDressing comprises two primary networks named GarmentsNet and DressingNet, which are respectively dedicated to extracting detailed clothing features and generating customized images. Specifically, we propose an efficient and scalable module called Garment-Specific Feature Extractor in GarmentsNet to individually encode garment textures in parallel. This design prevents garment confusion while ensuring network efficiency. Meanwhile, we design an adaptive Dressing-Attention mechanism and a novel Instance-Level Garment Localization Learning strategy in DressingNet to accurately inject multi-garment features into their corresponding regions. This approach efficiently integrates multi-garment texture cues into generated images and further enhances text-image consistency. Additionally, we introduce a Garment-Enhanced Texture Learning strategy to improve the fine-grained texture details of garments. Thanks to our well-craft design, AnyDressing can serve as a plug-in module to easily integrate with any community control extensions for diffusion models, improving the diversity and controllability of synthesized images. Extensive experiments show that AnyDressing achieves state-of-the-art results.