 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamID-Omni: Unified Framework for Controllable Human-Centric Audio-Video Generation
Feb 12, 2026Recent advancements in foundation models have revolutionized joint audio-video generation. However, existing approaches typically treat human-centric tasks including reference-based audio-video generation (R2AV), video editing (RV2AV) and audio-driven video animation (RA2V) as isolated objectives. Furthermore, achieving precise, disentangled control over multiple character identities and voice timbres within a single framework remains an open challenge. In this paper, we propose DreamID-Omni, a unified framework for controllable human-centric audio-video generation. Specifically, we design a Symmetric Conditional Diffusion Transformer that integrates heterogeneous conditioning signals via a symmetric conditional injection scheme. To resolve the pervasive identity-timbre binding failures and speaker confusion in multi-person scenarios, we introduce a Dual-Level Disentanglement strategy: Synchronized RoPE at the signal level to ensure rigid attention-space binding, and Structured Captions at the semantic level to establish explicit attribute-subject mappings. Furthermore, we devise a Multi-Task Progressive Training scheme that leverages weakly-constrained generative priors to regularize strongly-constrained tasks, preventing overfitting and harmonizing disparate objectives. Extensive experiments demonstrate that DreamID-Omni achieves comprehensive state-of-the-art performance across video, audio, and audio-visual consistency, even outperforming leading proprietary commercial models. We will release our code to bridge the gap between academic research and commercial-grade applications.
DreamID-V:Bridging the Image-to-Video Gap for High-Fidelity Face Swapping via Diffusion Transformer
Jan 04, 2026Video Face Swapping (VFS) requires seamlessly injecting a source identity into a target video while meticulously preserving the original pose, expression, lighting, background, and dynamic information. Existing methods struggle to maintain identity similarity and attribute preservation while preserving temporal consistency. To address the challenge, we propose a comprehensive framework to seamlessly transfer the superiority of Image Face Swapping (IFS) to the video domain. We first introduce a novel data pipeline SyncID-Pipe that pre-trains an Identity-Anchored Video Synthesizer and combines it with IFS models to construct bidirectional ID quadruplets for explicit supervision. Building upon paired data, we propose the first Diffusion Transformer-based framework DreamID-V, employing a core Modality-Aware Conditioning module to discriminatively inject multi-model conditions. Meanwhile, we propose a Synthetic-to-Real Curriculum mechanism and an Identity-Coherence Reinforcement Learning strategy to enhance visual realism and identity consistency under challenging scenarios. To address the issue of limited benchmarks, we introduce IDBench-V, a comprehensive benchmark encompassing diverse scenes. Extensive experiments demonstrate DreamID-V outperforms state-of-the-art methods and further exhibits exceptional versatility, which can be seamlessly adapted to various swap-related tasks.
Is FISHER All You Need in The Multi-AUV Underwater Target Tracking Task?
Dec 05, 2024



It is significant to employ multiple autonomous underwater vehicles (AUVs) to execute the underwater target tracking task collaboratively. However, it's pretty challenging to meet various prerequisites utilizing traditional control methods. Therefore, we propose an effective two-stage learning from demonstrations training framework, FISHER, to highlight the adaptability of reinforcement learning (RL) methods in the multi-AUV underwater target tracking task, while addressing its limitations such as extensive requirements for environmental interactions and the challenges in designing reward functions. The first stage utilizes imitation learning (IL) to realize policy improvement and generate offline datasets. To be specific, we introduce multi-agent discriminator-actor-critic based on improvements of the generative adversarial IL algorithm and multi-agent IL optimization objective derived from the Nash equilibrium condition. Then in the second stage, we develop multi-agent independent generalized decision transformer, which analyzes the latent representation to match the future states of high-quality samples rather than reward function, attaining further enhanced policies capable of handling various scenarios. Besides, we propose a simulation to simulation demonstration generation procedure to facilitate the generation of expert demonstrations in underwater environments, which capitalizes on traditional control methods and can easily accomplish the domain transfer to obtain demonstrations. Extensive simulation experiments from multiple scenarios showcase that FISHER possesses strong stability, multi-task performance and capability of generalization.
Two-Timescale Model Caching and Resource Allocation for Edge-Enabled AI-Generated Content Services
Nov 03, 2024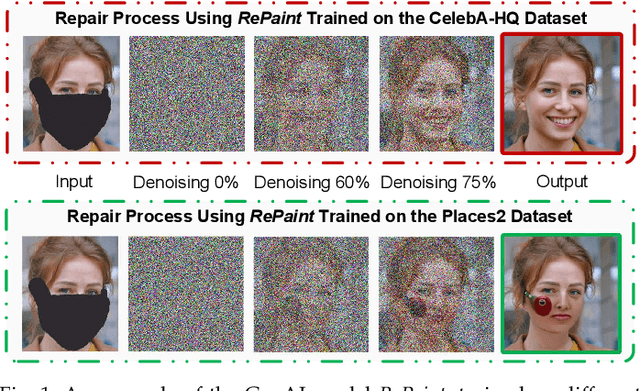

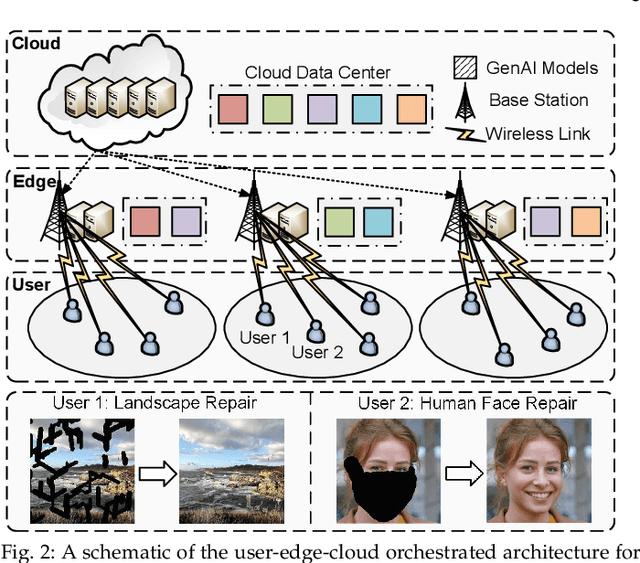

Generative AI (GenAI) has emerged as a transformative technology, enabling customized and personalized AI-generated content (AIGC) services. In this paper, we address challenges of edge-enabled AIGC service provisioning, which remain underexplored in the literature. These services require executing GenAI models with billions of parameters, posing significant obstacles to resource-limited wireless edge. We subsequently introduce the formulation of joint model caching and resource allocation for AIGC services to balance a trade-off between AIGC quality and latency metrics. We obtain mathematical relationships of these metrics with the computational resources required by GenAI models via experimentation. Afterward, we decompose the formulation into a model caching subproblem on a long-timescale and a resource allocation subproblem on a short-timescale. Since the variables to be solved are discrete and continuous, respectively, we leverage a double deep Q-network (DDQN) algorithm to solve the former subproblem and propose a diffusion-based deep deterministic policy gradient (D3PG) algorithm to solve the latter. The proposed D3PG algorithm makes an innovative use of diffusion models as the actor network to determine optimal resource allocation decisions. Consequently, we integrate these two learning methods within the overarching two-timescale deep reinforcement learning (T2DRL) algorithm, the performance of which is studied through comparative numerical simulations.