 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-Timescale Model Caching and Resource Allocation for Edge-Enabled AI-Generated Content Services
Paper and Code
Nov 03, 2024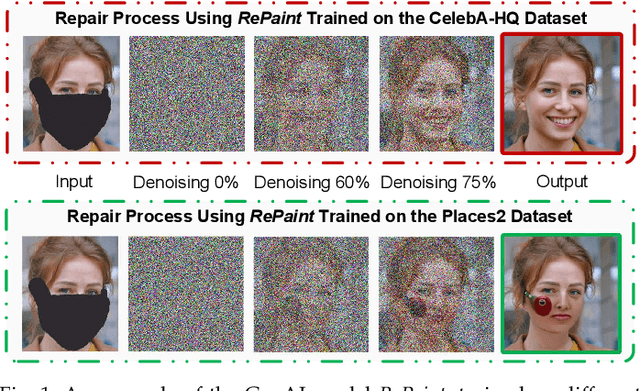

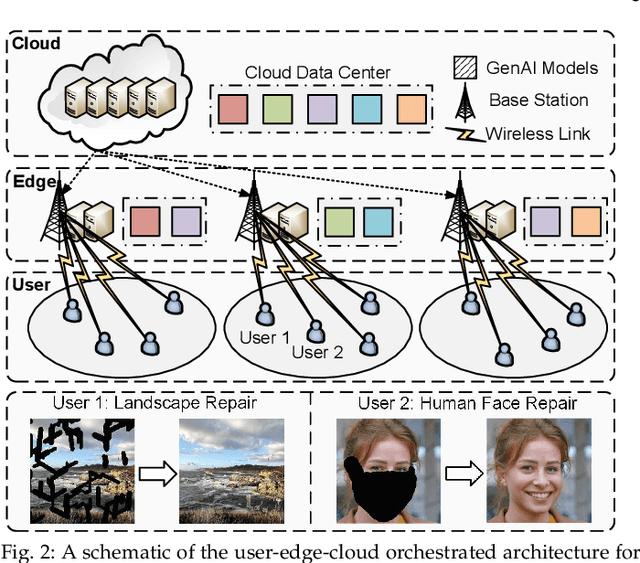

Generative AI (GenAI) has emerged as a transformative technology, enabling customized and personalized AI-generated content (AIGC) services. In this paper, we address challenges of edge-enabled AIGC service provisioning, which remain underexplored in the literature. These services require executing GenAI models with billions of parameters, posing significant obstacles to resource-limited wireless edge. We subsequently introduce the formulation of joint model caching and resource allocation for AIGC services to balance a trade-off between AIGC quality and latency metrics. We obtain mathematical relationships of these metrics with the computational resources required by GenAI models via experimentation. Afterward, we decompose the formulation into a model caching subproblem on a long-timescale and a resource allocation subproblem on a short-timescale. Since the variables to be solved are discrete and continuous, respectively, we leverage a double deep Q-network (DDQN) algorithm to solve the former subproblem and propose a diffusion-based deep deterministic policy gradient (D3PG) algorithm to solve the latter. The proposed D3PG algorithm makes an innovative use of diffusion models as the actor network to determine optimal resource allocation decisions. Consequently, we integrate these two learning methods within the overarching two-timescale deep reinforcement learning (T2DRL) algorithm, the performance of which is studied through comparative numerical simulations.