 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatiotemporal Link Formation Prediction in Social Learning Networks Using Graph Neural Networks
Apr 20, 2026Social learning networks (SLNs) are graphical representations that capture student interactions within educational settings (e.g., a classroom), with nodes representing students and edges denoting interactions. Accurately predicting future interactions in these networks (i.e., link prediction) is crucial for enabling effective collaborative learning, supporting timely instructional interventions, and informing the design of effective group-based learning activities. However, traditional link prediction approaches are typically tuned to general online social networks (OSNs), often overlooking the complex, non-Euclidean, and dynamically evolving structure of SLNs, thus limiting their effectiveness in educational settings. In this work, we propose a graph neural network (GNN) framework that jointly considers the temporal evolution within classrooms and spatial aggregation across classrooms to perform link prediction in SLNs. Specifically, we analyze link prediction performance of GNNs over the SLNs of four distinct classrooms across their (i) temporal evolutions (varying time instances), (ii) spatial aggregations (joint SLN analysis), and (iii) varying spatial aggregations at varying temporal evolutions throughout the course. Our results indicate statistically significant performance improvements in the prediction of future links as the courses progress temporally. Aggregating SLNs from multiple classrooms generally enhances model performance as well, especially in sparser datasets. Moreover, we find that jointly leveraging both the temporal evolution and spatial aggregation of SLNs significantly outperforms conventional baseline approaches that analyze classrooms in isolation. Our findings demonstrate the efficacy of educationally meaningful link predictions, with direct implications for early-course decision-making and scalable learning analytics in and across classroom settings.
RE-MCDF: Closed-Loop Multi-Expert LLM Reasoning for Knowledge-Grounded Clinical Diagnosis
Feb 01, 2026Electronic medical records (EMRs), particularly in neurology, are inherently heterogeneous, sparse, and noisy, which poses significant challenges for large language models (LLMs) in clinical diagnosis. In such settings, single-agent systems are vulnerable to self-reinforcing errors, as their predictions lack independent validation and can drift toward spurious conclusions. Although recent multi-agent frameworks attempt to mitigate this issue through collaborative reasoning, their interactions are often shallow and loosely structured, failing to reflect the rigorous, evidence-driven processes used by clinical experts. More fundamentally, existing approaches largely ignore the rich logical dependencies among diseases, such as mutual exclusivity, pathological compatibility, and diagnostic confusion. This limitation prevents them from ruling out clinically implausible hypotheses, even when sufficient evidence is available. To overcome these, we propose RE-MCDF, a relation-enhanced multi-expert clinical diagnosis framework. RE-MCDF introduces a generation--verification--revision closed-loop architecture that integrates three complementary components: (i) a primary expert that generates candidate diagnoses and supporting evidence, (ii) a laboratory expert that dynamically prioritizes heterogeneous clinical indicators, and (iii) a multi-relation awareness and evaluation expert group that explicitly enforces inter-disease logical constraints. Guided by a medical knowledge graph (MKG), the first two experts adaptively reweight EMR evidence, while the expert group validates and corrects candidate diagnoses to ensure logical consistency. Extensive experiments on the neurology subset of CMEMR (NEEMRs) and on our curated dataset (XMEMRs) demonstrate that RE-MCDF consistently outperforms state-of-the-art baselines in complex diagnostic scenarios.
Sporadic Gradient Tracking over Directed Graphs: A Theoretical Perspective on Decentralized Federated Learning
Jan 31, 2026Decentralized Federated Learning (DFL) enables clients with local data to collaborate in a peer-to-peer manner to train a generalized model. In this paper, we unify two branches of work that have separately solved important challenges in DFL: (i) gradient tracking techniques for mitigating data heterogeneity and (ii) accounting for diverse availability of resources across clients. We propose $\textit{Sporadic Gradient Tracking}$ ($\texttt{Spod-GT}$), the first DFL algorithm that incorporates these factors over general directed graphs by allowing (i) client-specific gradient computation frequencies and (ii) heterogeneous and asymmetric communication frequencies. We conduct a rigorous convergence analysis of our methodology with relaxed assumptions on gradient estimation variance and gradient diversity of clients, providing consensus and optimality guarantees for GT over directed graphs despite intermittent client participation. Through numerical experiments on image classification datasets, we demonstrate the efficacy of $\texttt{Spod-GT}$ compared to well-known GT baselines.
ELSA: Efficient LLM-Centric Split Aggregation for Privacy-Aware Hierarchical Federated Learning over Resource-Constrained Edge Networks
Jan 20, 2026Training large language models (LLMs) at the network edge faces fundamental challenges arising from device resource constraints, severe data heterogeneity, and heightened privacy risks. To address these, we propose ELSA (Efficient LLM-centric Split Aggregation), a novel framework that systematically integrates split learning (SL) and hierarchical federated learning (HFL) for distributed LLM fine-tuning over resource-constrained edge networks. ELSA introduces three key innovations. First, it employs a task-agnostic, behavior-aware client clustering mechanism that constructs semantic fingerprints using public probe inputs and symmetric KL divergence, further enhanced by prediction-consistency-based trust scoring and latency-aware edge assignment to jointly address data heterogeneity, client unreliability, and communication constraints. Second, it splits the LLM into three parts across clients and edge servers, with the cloud used only for adapter aggregation, enabling an effective balance between on-device computation cost and global convergence stability. Third, it incorporates a lightweight communication scheme based on computational sketches combined with semantic subspace orthogonal perturbation (SS-OP) to reduce communication overhead while mitigating privacy leakage during model exchanges. Experiments across diverse NLP tasks demonstrate that ELSA consistently outperforms state-of-the-art methods in terms of adaptability, convergence behavior, and robustness, establishing a scalable and privacy-aware solution for edge-side LLM fine-tuning under resource constraints.
Game-Theoretic Safe Multi-Agent Motion Planning with Reachability Analysis for Dynamic and Uncertain Environments (Extended Version)
Nov 15, 2025Ensuring safe, robust, and scalable motion planning for multi-agent systems in dynamic and uncertain environments is a persistent challenge, driven by complex inter-agent interactions, stochastic disturbances, and model uncertainties. To overcome these challenges, particularly the computational complexity of coupled decision-making and the need for proactive safety guarantees, we propose a Reachability-Enhanced Dynamic Potential Game (RE-DPG) framework, which integrates game-theoretic coordination into reachability analysis. This approach formulates multi-agent coordination as a dynamic potential game, where the Nash equilibrium (NE) defines optimal control strategies across agents. To enable scalability and decentralized execution, we develop a Neighborhood-Dominated iterative Best Response (ND-iBR) scheme, built upon an iterated $\varepsilon$-BR (i$\varepsilon$-BR) process that guarantees finite-step convergence to an $\varepsilon$-NE. This allows agents to compute strategies based on local interactions while ensuring theoretical convergence guarantees. Furthermore, to ensure safety under uncertainty, we integrate a Multi-Agent Forward Reachable Set (MA-FRS) mechanism into the cost function, explicitly modeling uncertainty propagation and enforcing collision avoidance constraints. Through both simulations and real-world experiments in 2D and 3D environments, we validate the effectiveness of RE-DPG across diverse operational scenarios.
TAP: Two-Stage Adaptive Personalization of Multi-task and Multi-Modal Foundation Models in Federated Learning
Sep 30, 2025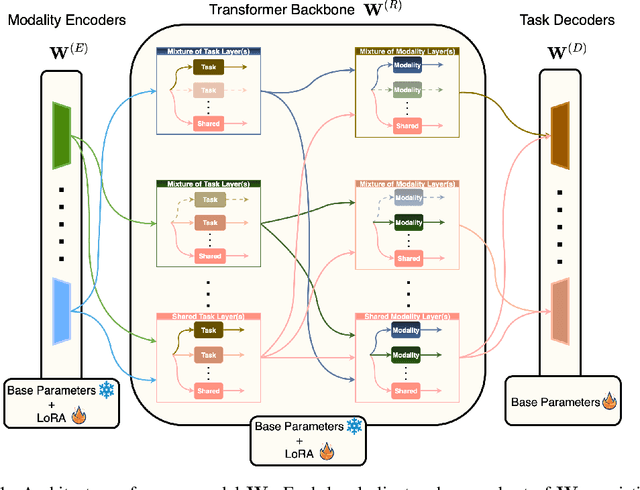
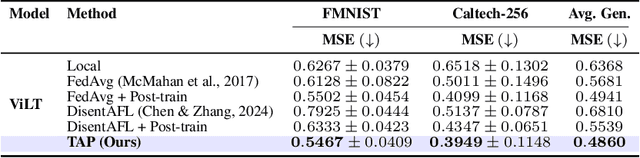
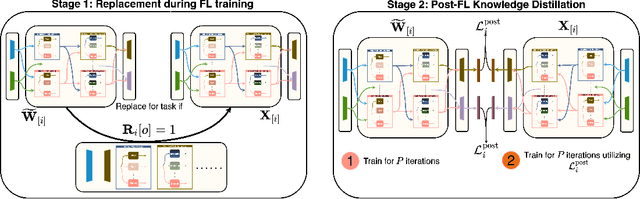
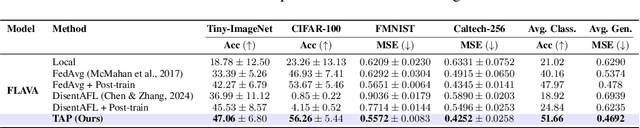
Federated Learning (FL), despite demonstrating impressive capabilities in the training of multiple models in a decentralized manner, has been shown to produce a final model not necessarily well-suited to the needs of each client. While extensive work has been conducted on how to create tailored personalized models, called Personalized Federated Learning (PFL), less attention has been given to personalization via fine-tuning of foundation models with multi-task and multi-modal properties. Moreover, there exists a lack of understanding in the literature on how to fine-tune and personalize such models in a setting that is heterogeneous across clients not only in data, but also in tasks and modalities. To address this gap in the literature, we propose TAP (Two-Stage Adaptive Personalization), which (i) leverages mismatched model architectures between the clients and server to selectively conduct replacement operations when it benefits a client's local tasks and (ii) engages in post-FL knowledge distillation for capturing beneficial general knowledge without compromising personalization. We also introduce the first convergence analysis of the server model under its modality-task pair architecture, and demonstrate that as the number of modality-task pairs increases, its ability to cater to all tasks suffers. Through extensive experiments, we demonstrate the effectiveness of our proposed algorithm across a variety of datasets and tasks in comparison to a multitude of baselines. Implementation code is publicly available at https://github.com/lee3296/TAP.
Bringing Multi-Modal Multi-Task Federated Foundation Models to Education Domain: Prospects and Challenges
Sep 09, 2025Multi-modal multi-task (M3T) foundation models (FMs) have recently shown transformative potential in artificial intelligence, with emerging applications in education. However, their deployment in real-world educational settings is hindered by privacy regulations, data silos, and limited domain-specific data availability. We introduce M3T Federated Foundation Models (FedFMs) for education: a paradigm that integrates federated learning (FL) with M3T FMs to enable collaborative, privacy-preserving training across decentralized institutions while accommodating diverse modalities and tasks. Subsequently, this position paper aims to unveil M3T FedFMs as a promising yet underexplored approach to the education community, explore its potentials, and reveal its related future research directions. We outline how M3T FedFMs can advance three critical pillars of next-generation intelligent education systems: (i) privacy preservation, by keeping sensitive multi-modal student and institutional data local; (ii) personalization, through modular architectures enabling tailored models for students, instructors, and institutions; and (iii) equity and inclusivity, by facilitating participation from underrepresented and resource-constrained entities. We finally identify various open research challenges, including studying of (i) inter-institution heterogeneous privacy regulations, (ii) the non-uniformity of data modalities' characteristics, (iii) the unlearning approaches for M3T FedFMs, (iv) the continual learning frameworks for M3T FedFMs, and (v) M3T FedFM model interpretability, which must be collectively addressed for practical deployment.
Hierarchical Federated Foundation Models over Wireless Networks for Multi-Modal Multi-Task Intelligence: Integration of Edge Learning with D2D/P2P-Enabled Fog Learning Architectures
Sep 03, 2025


The rise of foundation models (FMs) has reshaped the landscape of machine learning. As these models continued to grow, leveraging geo-distributed data from wireless devices has become increasingly critical, giving rise to federated foundation models (FFMs). More recently, FMs have evolved into multi-modal multi-task (M3T) FMs (e.g., GPT-4) capable of processing diverse modalities across multiple tasks, which motivates a new underexplored paradigm: M3T FFMs. In this paper, we unveil an unexplored variation of M3T FFMs by proposing hierarchical federated foundation models (HF-FMs), which in turn expose two overlooked heterogeneity dimensions to fog/edge networks that have a direct impact on these emerging models: (i) heterogeneity in collected modalities and (ii) heterogeneity in executed tasks across fog/edge nodes. HF-FMs strategically align the modular structure of M3T FMs, comprising modality encoders, prompts, mixture-of-experts (MoEs), adapters, and task heads, with the hierarchical nature of fog/edge infrastructures. Moreover, HF-FMs enable the optional usage of device-to-device (D2D) communications, enabling horizontal module relaying and localized cooperative training among nodes when feasible. Through delving into the architectural design of HF-FMs, we highlight their unique capabilities along with a series of tailored future research directions. Finally, to demonstrate their potential, we prototype HF-FMs in a wireless network setting and release the open-source code for the development of HF-FMs with the goal of fostering exploration in this untapped field (GitHub: https://github.com/payamsiabd/M3T-FFM).
From Federated Learning to $\mathbb{X}$-Learning: Breaking the Barriers of Decentrality Through Random Walks
Sep 03, 2025We provide our perspective on $\mathbb{X}$-Learning ($\mathbb{X}$L), a novel distributed learning architecture that generalizes and extends the concept of decentralization. Our goal is to present a vision for $\mathbb{X}$L, introducing its unexplored design considerations and degrees of freedom. To this end, we shed light on the intuitive yet non-trivial connections between $\mathbb{X}$L, graph theory, and Markov chains. We also present a series of open research directions to stimulate further research.
Multi-Modal Multi-Task (M3T) Federated Foundation Models for Embodied AI: Potentials and Challenges for Edge Integration
May 16, 2025As embodied AI systems become increasingly multi-modal, personalized, and interactive, they must learn effectively from diverse sensory inputs, adapt continually to user preferences, and operate safely under resource and privacy constraints. These challenges expose a pressing need for machine learning models capable of swift, context-aware adaptation while balancing model generalization and personalization. Here, two methods emerge as suitable candidates, each offering parts of these capabilities: Foundation Models (FMs) provide a pathway toward generalization across tasks and modalities, whereas Federated Learning (FL) offers the infrastructure for distributed, privacy-preserving model updates and user-level model personalization. However, when used in isolation, each of these approaches falls short of meeting the complex and diverse capability requirements of real-world embodied environments. In this vision paper, we introduce Federated Foundation Models (FFMs) for embodied AI, a new paradigm that unifies the strengths of multi-modal multi-task (M3T) FMs with the privacy-preserving distributed nature of FL, enabling intelligent systems at the wireless edge. We collect critical deployment dimensions of FFMs in embodied AI ecosystems under a unified framework, which we name "EMBODY": Embodiment heterogeneity, Modality richness and imbalance, Bandwidth and compute constraints, On-device continual learning, Distributed control and autonomy, and Yielding safety, privacy, and personalization. For each, we identify concrete challenges and envision actionable research directions. We also present an evaluation framework for deploying FFMs in embodied AI systems, along with the associated trade-offs.