 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive UAV-Assisted Hierarchical Federated Learning: Optimizing Energy, Latency, and Resilience for Dynamic Smart IoT Networks
Mar 08, 2025



Hierarchical Federated Learning (HFL) introduces intermediate aggregation layers, addressing the limitations of conventional Federated Learning (FL) in geographically dispersed environments with limited communication infrastructure. An application of HFL is in smart IoT systems, such as remote monitoring, disaster response, and battlefield operations, where cellular connectivity is often unreliable or unavailable. In these scenarios, UAVs serve as mobile aggregators, providing connectivity to the terrestrial IoT devices. This paper studies an HFL architecture for energy-constrained UAVs in smart IoT systems, pioneering a solution to minimize global training cost increased caused by UAV disconnection. In light of this, we formulate a joint optimization problem involving learning configuration, bandwidth allocation, and device-to-UAV association, and perform global aggregation in time before UAV drops disconnect and redeployment of UAVs. The problem explicitly accounts for the dynamic nature of IoT devices and their interruptible communications and is unveiled to be NP-hard. To address this, we decompose it into three subproblems. First, we optimize the learning configuration and bandwidth allocation using an augmented Lagrangian function to reduce training costs. Second, we propose a device fitness score, integrating data heterogeneity (via Kullback-Leibler divergence), device-to-UAV distances, and IoT device resources, and develop a twin-delayed deep deterministic policy gradient (TD3)-based algorithm for dynamic device-to-UAV assignment. Third, We introduce a low-complexity two-stage greedy strategy for finding the location of UAVs redeployment and selecting the appropriate global aggregator UAV. Experiments on real-world datasets demonstrate significant cost reductions and robust performance under communication interruptions.
Towards Seamless Hierarchical Federated Learning under Intermittent Client Participation: A Stagewise Decision-Making Methodology
Feb 13, 2025Federated Learning (FL) offers a pioneering distributed learning paradigm that enables devices/clients to build a shared global model. This global model is obtained through frequent model transmissions between clients and a central server, which may cause high latency, energy consumption, and congestion over backhaul links. To overcome these drawbacks, Hierarchical Federated Learning (HFL) has emerged, which organizes clients into multiple clusters and utilizes edge nodes (e.g., edge servers) for intermediate model aggregations between clients and the central server. Current research on HFL mainly focus on enhancing model accuracy, latency, and energy consumption in scenarios with a stable/fixed set of clients. However, addressing the dynamic availability of clients -- a critical aspect of real-world scenarios -- remains underexplored. This study delves into optimizing client selection and client-to-edge associations in HFL under intermittent client participation so as to minimize overall system costs (i.e., delay and energy), while achieving fast model convergence. We unveil that achieving this goal involves solving a complex NP-hard problem. To tackle this, we propose a stagewise methodology that splits the solution into two stages, referred to as Plan A and Plan B. Plan A focuses on identifying long-term clients with high chance of participation in subsequent model training rounds. Plan B serves as a backup, selecting alternative clients when long-term clients are unavailable during model training rounds. This stagewise methodology offers a fresh perspective on client selection that can enhance both HFL and conventional FL via enabling low-overhead decision-making processes. Through evaluations on MNIST and CIFAR-10 datasets, we show that our methodology outperforms existing benchmarks in terms of model accuracy and system costs.
Cloud-Magnetic Resonance Imaging System: In the Era of 6G and Artificial Intelligence
Oct 18, 2023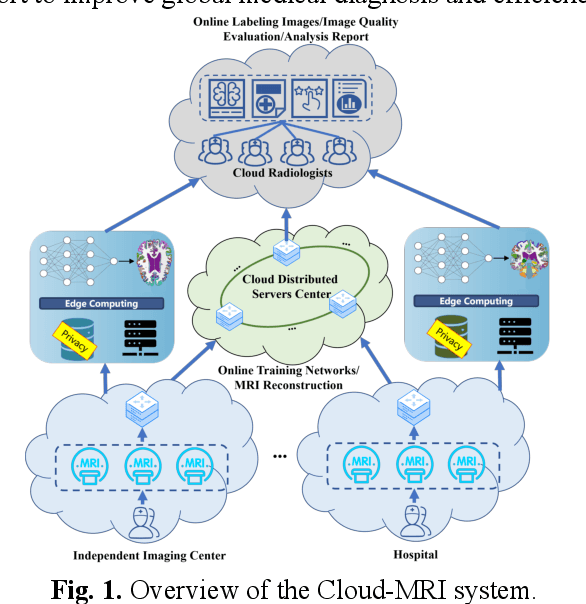
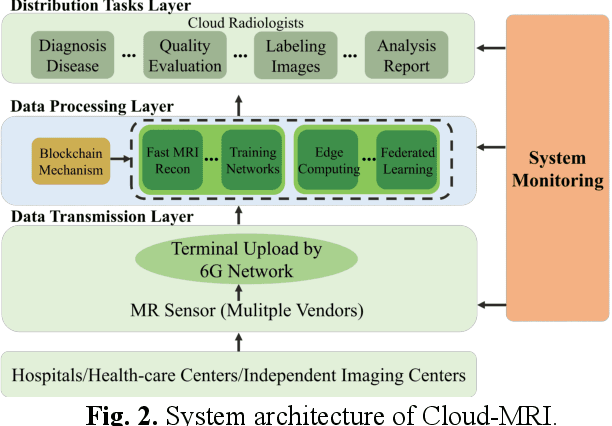
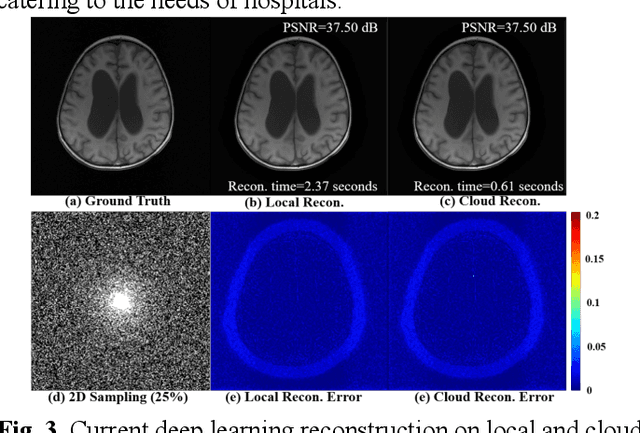
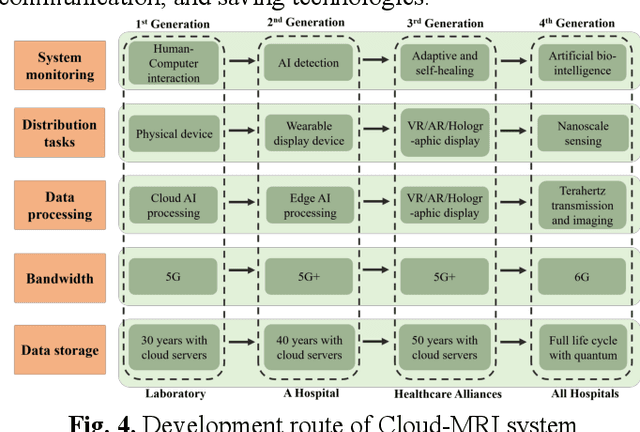
Magnetic Resonance Imaging (MRI) plays an important role in medical diagnosis, generating petabytes of image data annually in large hospitals. This voluminous data stream requires a significant amount of network bandwidth and extensive storage infrastructure. Additionally, local data processing demands substantial manpower and hardware investments. Data isolation across different healthcare institutions hinders cross-institutional collaboration in clinics and research. In this work, we anticipate an innovative MRI system and its four generations that integrate emerging distributed cloud computing, 6G bandwidth, edge computing, federated learning, and blockchain technology. This system is called Cloud-MRI, aiming at solving the problems of MRI data storage security, transmission speed, AI algorithm maintenance, hardware upgrading, and collaborative work. The workflow commences with the transformation of k-space raw data into the standardized Imaging Society for Magnetic Resonance in Medicine Raw Data (ISMRMRD) format. Then, the data are uploaded to the cloud or edge nodes for fast image reconstruction, neural network training, and automatic analysis. Then, the outcomes are seamlessly transmitted to clinics or research institutes for diagnosis and other services. The Cloud-MRI system will save the raw imaging data, reduce the risk of data loss, facilitate inter-institutional medical collaboration, and finally improve diagnostic accuracy and work efficiency.