 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTacchi 2.0: A Low Computational Cost and Comprehensive Dynamic Contact Simulator for Vision-based Tactile Sensors
Mar 12, 2025With the development of robotics technology, some tactile sensors, such as vision-based sensors, have been applied to contact-rich robotics tasks. However, the durability of vision-based tactile sensors significantly increases the cost of tactile information acquisition. Utilizing simulation to generate tactile data has emerged as a reliable approach to address this issue. While data-driven methods for tactile data generation lack robustness, finite element methods (FEM) based approaches require significant computational costs. To address these issues, we integrated a pinhole camera model into the low computational cost vision-based tactile simulator Tacchi that used the Material Point Method (MPM) as the simulated method, completing the simulation of marker motion images. We upgraded Tacchi and introduced Tacchi 2.0. This simulator can simulate tactile images, marked motion images, and joint images under different motion states like pressing, slipping, and rotating. Experimental results demonstrate the reliability of our method and its robustness across various vision-based tactile sensors.
Reproducibility Assessment of Magnetic Resonance Spectroscopy of Pregenual Anterior Cingulate Cortex across Sessions and Vendors via the Cloud Computing Platform CloudBrain-MRS
Mar 06, 2025



Given the need to elucidate the mechanisms underlying illnesses and their treatment, as well as the lack of harmonization of acquisition and post-processing protocols among different magnetic resonance system vendors, this work is to determine if metabolite concentrations obtained from different sessions, machine models and even different vendors of 3 T scanners can be highly reproducible and be pooled for diagnostic analysis, which is very valuable for the research of rare diseases. Participants underwent magnetic resonance imaging (MRI) scanning once on two separate days within one week (one session per day, each session including two proton magnetic resonance spectroscopy (1H-MRS) scans with no more than a 5-minute interval between scans (no off-bed activity)) on each machine. were analyzed for reliability of within- and between- sessions using the coefficient of variation (CV) and intraclass correlation coefficient (ICC), and for reproducibility of across the machines using correlation coefficient. As for within- and between- session, all CV values for a group of all the first or second scans of a session, or for a session were almost below 20%, and most of the ICCs for metabolites range from moderate (0.4-0.59) to excellent (0.75-1), indicating high data reliability. When it comes to the reproducibility across the three scanners, all Pearson correlation coefficients across the three machines approached 1 with most around 0.9, and majority demonstrated statistical significance (P<0.01). Additionally, the intra-vendor reproducibility was greater than the inter-vendor ones.
An artificially intelligent magnetic resonance spectroscopy quantification method: Comparison between QNet and LCModel on the cloud computing platform CloudBrain-MRS
Mar 06, 2025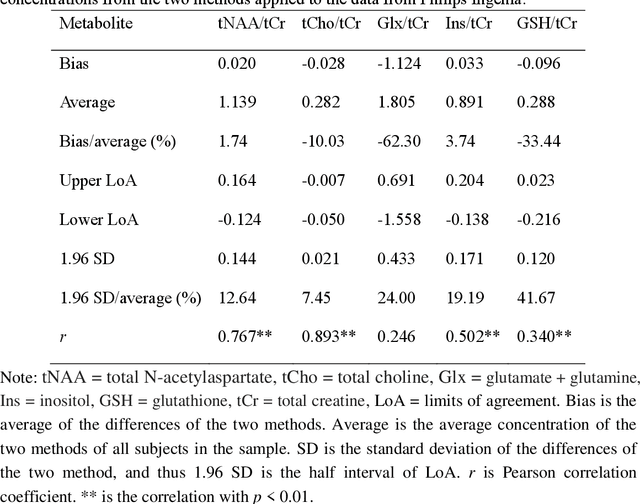

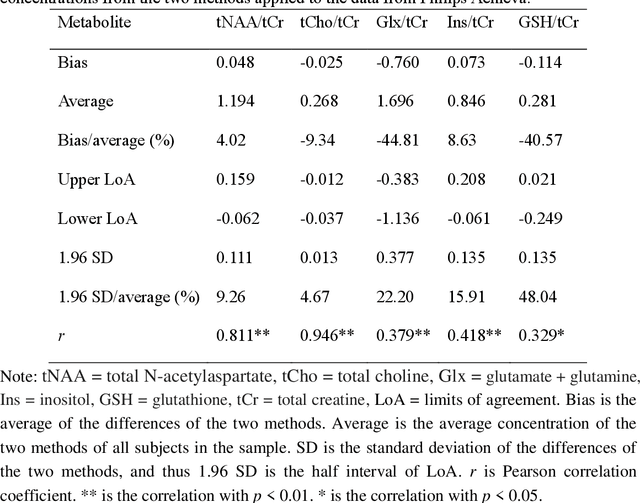
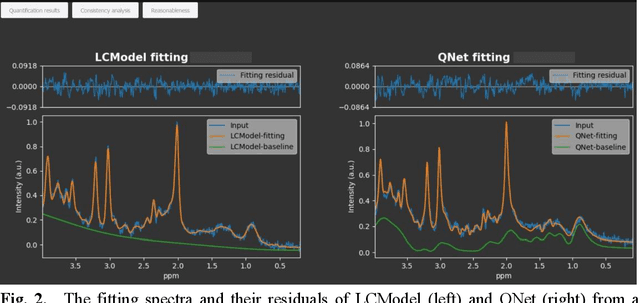
Objctives: This work aimed to statistically compare the metabolite quantification of human brain magnetic resonance spectroscopy (MRS) between the deep learning method QNet and the classical method LCModel through an easy-to-use intelligent cloud computing platform CloudBrain-MRS. Materials and Methods: In this retrospective study, two 3 T MRI scanners Philips Ingenia and Achieva collected 61 and 46 in vivo 1H magnetic resonance (MR) spectra of healthy participants, respectively, from the brain region of pregenual anterior cingulate cortex from September to October 2021. The analyses of Bland-Altman, Pearson correlation and reasonability were performed to assess the degree of agreement, linear correlation and reasonability between the two quantification methods. Results: Fifteen healthy volunteers (12 females and 3 males, age range: 21-35 years, mean age/standard deviation = 27.4/3.9 years) were recruited. The analyses of Bland-Altman, Pearson correlation and reasonability showed high to good consistency and very strong to moderate correlation between the two methods for quantification of total N-acetylaspartate (tNAA), total choline (tCho), and inositol (Ins) (relative half interval of limits of agreement = 3.04%, 9.3%, and 18.5%, respectively; Pearson correlation coefficient r = 0.775, 0.927, and 0.469, respectively). In addition, quantification results of QNet are more likely to be closer to the previous reported average values than those of LCModel. Conclusion: There were high or good degrees of consistency between the quantification results of QNet and LCModel for tNAA, tCho, and Ins, and QNet generally has more reasonable quantification than LCModel.
Conditional Diffusion Model for Electrical Impedance Tomography
Jan 10, 2025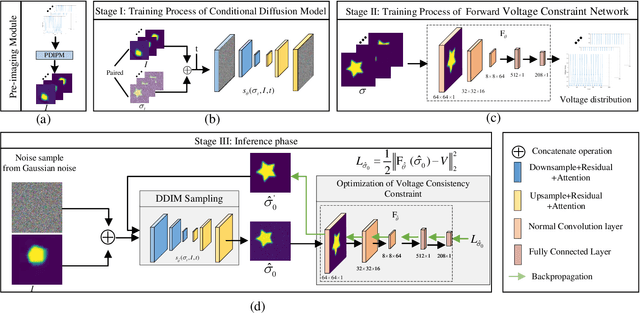

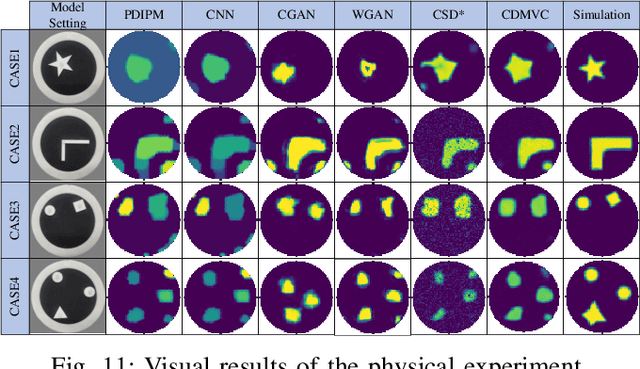
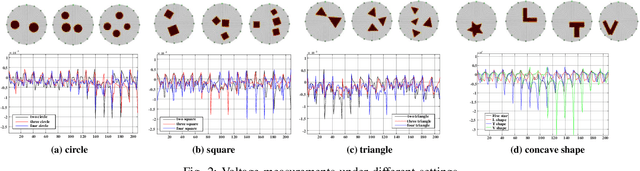
Electrical impedance tomography (EIT) is a non-invasive imaging technique, which has been widely used in the fields of industrial inspection, medical monitoring and tactile sensing. However, due to the inherent non-linearity and ill-conditioned nature of the EIT inverse problem, the reconstructed image is highly sensitive to the measured data, and random noise artifacts often appear in the reconstructed image, which greatly limits the application of EIT. To address this issue, a conditional diffusion model with voltage consistency (CDMVC) is proposed in this study. The method consists of a pre-imaging module, a conditional diffusion model for reconstruction, a forward voltage constraint network and a scheme of voltage consistency constraint during sampling process. The pre-imaging module is employed to generate the initial reconstruction. This serves as a condition for training the conditional diffusion model. Finally, based on the forward voltage constraint network, a voltage consistency constraint is implemented in the sampling phase to incorporate forward information of EIT, thereby enhancing imaging quality. A more complete dataset, including both common and complex concave shapes, is generated. The proposed method is validated using both simulation and physical experiments. Experimental results demonstrate that our method can significantly improves the quality of reconstructed images. In addition, experimental results also demonstrate that our method has good robustness and generalization performance.
AssistantX: An LLM-Powered Proactive Assistant in Collaborative Human-Populated Environment
Sep 26, 2024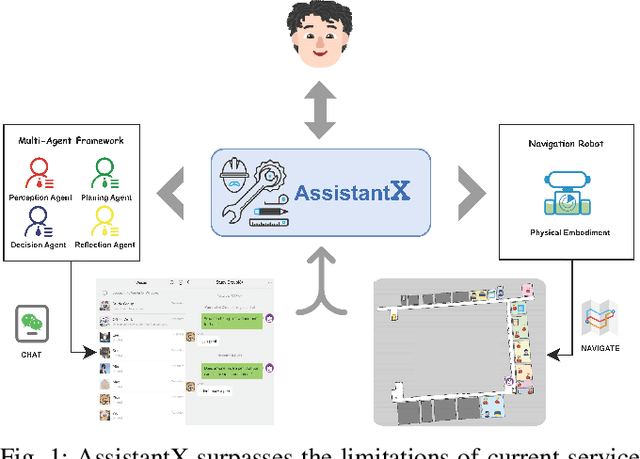
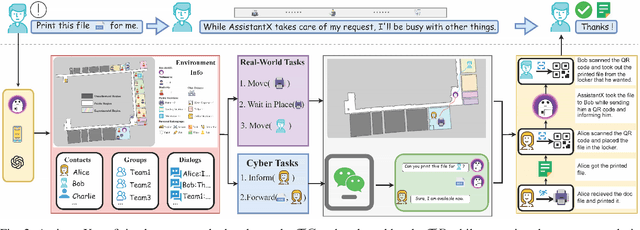
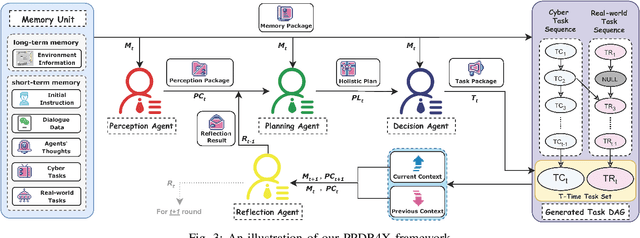
The increasing demand for intelligent assistants in human-populated environments has motivated significant research in autonomous robotic systems. Traditional service robots and virtual assistants, however, struggle with real-world task execution due to their limited capacity for dynamic reasoning and interaction, particularly when human collaboration is required. Recent developments in Large Language Models have opened new avenues for improving these systems, enabling more sophisticated reasoning and natural interaction capabilities. In this paper, we introduce AssistantX, an LLM-powered proactive assistant designed to operate autonomously in a physical office environment. Unlike conventional service robots, AssistantX leverages a novel multi-agent architecture, PPDR4X, which provides advanced inference capabilities and comprehensive collaboration awareness. By effectively bridging the gap between virtual operations and physical interactions, AssistantX demonstrates robust performance in managing complex real-world scenarios. Our evaluation highlights the architecture's effectiveness, showing that AssistantX can respond to clear instructions, actively retrieve supplementary information from memory, and proactively seek collaboration from team members to ensure successful task completion. More details and videos can be found at https://assistantx-agent.github.io/AssistantX/.
Leveraging Large Language Model for Heterogeneous Ad Hoc Teamwork Collaboration
Jun 18, 2024



Compared with the widely investigated homogeneous multi-robot collaboration, heterogeneous robots with different capabilities can provide a more efficient and flexible collaboration for more complex tasks. In this paper, we consider a more challenging heterogeneous ad hoc teamwork collaboration problem where an ad hoc robot joins an existing heterogeneous team for a shared goal. Specifically, the ad hoc robot collaborates with unknown teammates without prior coordination, and it is expected to generate an appropriate cooperation policy to improve the efficiency of the whole team. To solve this challenging problem, we leverage the remarkable potential of the large language model (LLM) to establish a decentralized heterogeneous ad hoc teamwork collaboration framework that focuses on generating reasonable policy for an ad hoc robot to collaborate with original heterogeneous teammates. A training-free hierarchical dynamic planner is developed using the LLM together with the newly proposed Interactive Reflection of Thoughts (IRoT) method for the ad hoc agent to adapt to different teams. We also build a benchmark testing dataset to evaluate the proposed framework in the heterogeneous ad hoc multi-agent tidying-up task. Extensive comparison and ablation experiments are conducted in the benchmark to demonstrate the effectiveness of the proposed framework. We have also employed the proposed framework in physical robots in a real-world scenario. The experimental videos can be found at https://youtu.be/wHYP5T2WIp0.
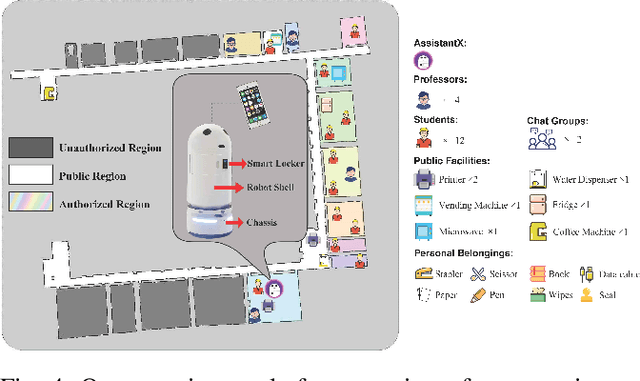
Demonstrating HumanTHOR: A Simulation Platform and Benchmark for Human-Robot Collaboration in a Shared Workspace
Jun 10, 2024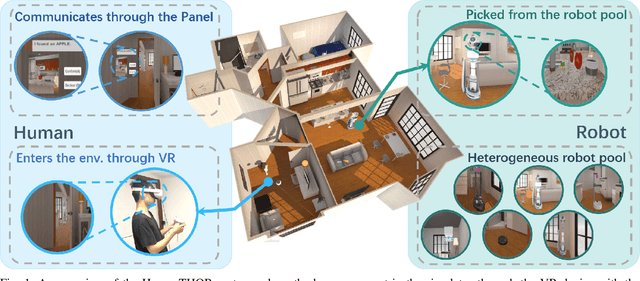



Human-robot collaboration (HRC) in a shared workspace has become a common pattern in real-world robot applications and has garnered significant research interest. However, most existing studies for human-in-the-loop (HITL) collaboration with robots in a shared workspace evaluate in either simplified game environments or physical platforms, falling short in limited realistic significance or limited scalability. To support future studies, we build an embodied framework named HumanTHOR, which enables humans to act in the simulation environment through VR devices to support HITL collaborations in a shared workspace. To validate our system, we build a benchmark of everyday tasks and conduct a preliminary user study with two baseline algorithms. The results show that the robot can effectively assist humans in collaboration, demonstrating the significance of HRC. The comparison among different levels of baselines affirms that our system can adequately evaluate robot capabilities and serve as a benchmark for different robot algorithms. The experimental results also indicate that there is still much room in the area and our system can provide a preliminary foundation for future HRC research in a shared workspace. More information about the simulation environment, experiment videos, benchmark descriptions, and additional supplementary materials can be found on the website: https://sites.google.com/view/humanthor/.
CompetEvo: Towards Morphological Evolution from Competition
May 28, 2024



Training an agent to adapt to specific tasks through co-optimization of morphology and control has widely attracted attention. However, whether there exists an optimal configuration and tactics for agents in a multiagent competition scenario is still an issue that is challenging to definitively conclude. In this context, we propose competitive evolution (CompetEvo), which co-evolves agents' designs and tactics in confrontation. We build arenas consisting of three animals and their evolved derivatives, placing agents with different morphologies in direct competition with each other. The results reveal that our method enables agents to evolve a more suitable design and strategy for fighting compared to fixed-morph agents, allowing them to obtain advantages in combat scenarios. Moreover, we demonstrate the amazing and impressive behaviors that emerge when confrontations are conducted under asymmetrical morphs.
Stimulate the Potential of Robots via Competition
Mar 15, 2024



It is common for us to feel pressure in a competition environment, which arises from the desire to obtain success comparing with other individuals or opponents. Although we might get anxious under the pressure, it could also be a drive for us to stimulate our potentials to the best in order to keep up with others. Inspired by this, we propose a competitive learning framework which is able to help individual robot to acquire knowledge from the competition, fully stimulating its dynamics potential in the race. Specifically, the competition information among competitors is introduced as the additional auxiliary signal to learn advantaged actions. We further build a Multiagent-Race environment, and extensive experiments are conducted, demonstrating that robots trained in competitive environments outperform ones that are trained with SoTA algorithms in single robot environment.
Deep Separable Spatiotemporal Learning for Fast Dynamic Cardiac MRI
Feb 24, 2024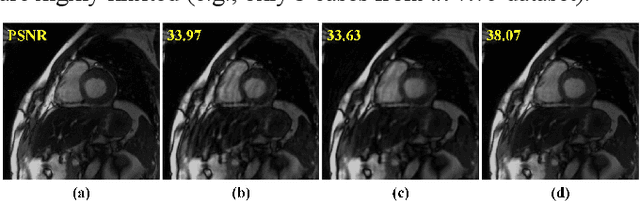
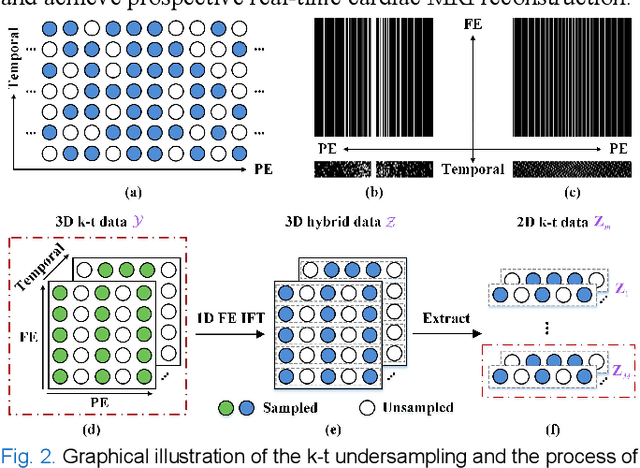
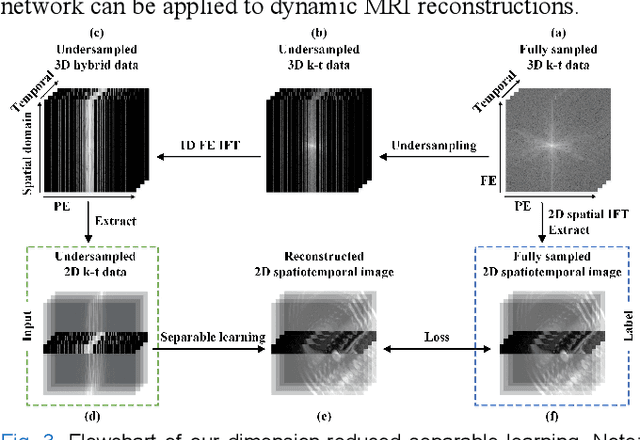
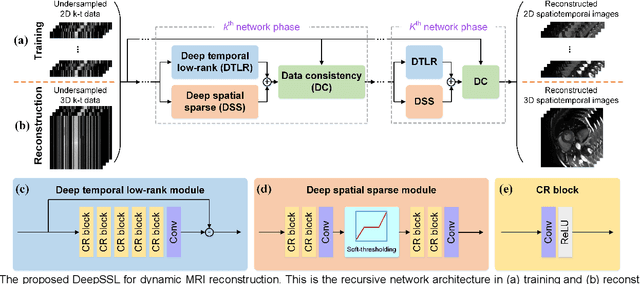
Dynamic magnetic resonance imaging (MRI) plays an indispensable role in cardiac diagnosis. To enable fast imaging, the k-space data can be undersampled but the image reconstruction poses a great challenge of high-dimensional processing. This challenge leads to necessitate extensive training data in many deep learning reconstruction methods. This work proposes a novel and efficient approach, leveraging a dimension-reduced separable learning scheme that excels even with highly limited training data. We further integrate it with spatiotemporal priors to develop a Deep Separable Spatiotemporal Learning network (DeepSSL), which unrolls an iteration process of a reconstruction model with both temporal low-rankness and spatial sparsity. Intermediate outputs are visualized to provide insights into the network's behavior and enhance its interpretability. Extensive results on cardiac cine datasets show that the proposed DeepSSL is superior to the state-of-the-art methods visually and quantitatively, while reducing the demand for training cases by up to 75%. And its preliminary adaptability to cardiac patients has been verified through experienced radiologists' and cardiologists' blind reader study. Additionally, DeepSSL also benefits for achieving the downstream task of cardiac segmentation with higher accuracy and shows robustness in prospective real-time cardiac MRI.