 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLMEB: Long-horizon Memory Embedding Benchmark
Mar 19, 2026Memory embeddings are crucial for memory-augmented systems, such as OpenClaw, but their evaluation is underexplored in current text embedding benchmarks, which narrowly focus on traditional passage retrieval and fail to assess models' ability to handle long-horizon memory retrieval tasks involving fragmented, context-dependent, and temporally distant information. To address this, we introduce the Long-horizon Memory Embedding Benchmark (LMEB), a comprehensive framework that evaluates embedding models' capabilities in handling complex, long-horizon memory retrieval tasks. LMEB spans 22 datasets and 193 zero-shot retrieval tasks across 4 memory types: episodic, dialogue, semantic, and procedural, with both AI-generated and human-annotated data. These memory types differ in terms of level of abstraction and temporal dependency, capturing distinct aspects of memory retrieval that reflect the diverse challenges of the real world. We evaluate 15 widely used embedding models, ranging from hundreds of millions to ten billion parameters. The results reveal that (1) LMEB provides a reasonable level of difficulty; (2) Larger models do not always perform better; (3) LMEB and MTEB exhibit orthogonality. This suggests that the field has yet to converge on a universal model capable of excelling across all memory retrieval tasks, and that performance in traditional passage retrieval may not generalize to long-horizon memory retrieval. In summary, by providing a standardized and reproducible evaluation framework, LMEB fills a crucial gap in memory embedding evaluation, driving further advancements in text embedding for handling long-term, context-dependent memory retrieval. LMEB is available at https://github.com/KaLM-Embedding/LMEB.
Designing Persuasive Social Robots for Health Behavior Change: A Systematic Review of Behavior Change Strategies and Evaluation Methods
Jan 13, 2026Social robots are increasingly applied as health behavior change interventions, yet actionable knowledge to guide their design and evaluation remains limited. This systematic review synthesizes (1) the behavior change strategies used in existing HRI studies employing social robots to promote health behavior change, and (2) the evaluation methods applied to assess behavior change outcomes. Relevant literature was identified through systematic database searches and hand searches. Analysis of 39 studies revealed four overarching categories of behavior change strategies: coaching strategies, counseling strategies, social influence strategies, and persuasion-enhancing strategies. These strategies highlight the unique affordances of social robots as behavior change interventions and offer valuable design heuristics. The review also identified key characteristics of current evaluation practices, including study designs, settings, durations, and outcome measures, on the basis of which we propose several directions for future HRI research.
Open Polymer Challenge: Post-Competition Report
Dec 09, 2025Machine learning (ML) offers a powerful path toward discovering sustainable polymer materials, but progress has been limited by the lack of large, high-quality, and openly accessible polymer datasets. The Open Polymer Challenge (OPC) addresses this gap by releasing the first community-developed benchmark for polymer informatics, featuring a dataset with 10K polymers and 5 properties: thermal conductivity, radius of gyration, density, fractional free volume, and glass transition temperature. The challenge centers on multi-task polymer property prediction, a core step in virtual screening pipelines for materials discovery. Participants developed models under realistic constraints that include small data, label imbalance, and heterogeneous simulation sources, using techniques such as feature-based augmentation, transfer learning, self-supervised pretraining, and targeted ensemble strategies. The competition also revealed important lessons about data preparation, distribution shifts, and cross-group simulation consistency, informing best practices for future large-scale polymer datasets. The resulting models, analysis, and released data create a new foundation for molecular AI in polymer science and are expected to accelerate the development of sustainable and energy-efficient materials. Along with the competition, we release the test dataset at https://www.kaggle.com/datasets/alexliu99/neurips-open-polymer-prediction-2025-test-data. We also release the data generation pipeline at https://github.com/sobinalosious/ADEPT, which simulates more than 25 properties, including thermal conductivity, radius of gyration, and density.
POINT$^{2}$: A Polymer Informatics Training and Testing Database
Mar 30, 2025



The advancement of polymer informatics has been significantly propelled by the integration of machine learning (ML) techniques, enabling the rapid prediction of polymer properties and expediting the discovery of high-performance polymeric materials. However, the field lacks a standardized workflow that encompasses prediction accuracy, uncertainty quantification, ML interpretability, and polymer synthesizability. In this study, we introduce POINT$^{2}$ (POlymer INformatics Training and Testing), a comprehensive benchmark database and protocol designed to address these critical challenges. Leveraging the existing labeled datasets and the unlabeled PI1M dataset, a collection of approximately one million virtual polymers generated via a recurrent neural network trained on the realistic polymers, we develop an ensemble of ML models, including Quantile Random Forests, Multilayer Perceptrons with dropout, Graph Neural Networks, and pretrained large language models. These models are coupled with diverse polymer representations such as Morgan, MACCS, RDKit, Topological, Atom Pair fingerprints, and graph-based descriptors to achieve property predictions, uncertainty estimations, model interpretability, and template-based polymerization synthesizability across a spectrum of properties, including gas permeability, thermal conductivity, glass transition temperature, melting temperature, fractional free volume, and density. The POINT$^{2}$ database can serve as a valuable resource for the polymer informatics community for polymer discovery and optimization.
A Criterion for Extending Continuous-Mixture Identifiability Results
Mar 05, 2025For continuous mixtures of random variables, we provide a simple criterion -- generating-function accessibility -- to extend previously known kernel-based identifiability (or unidentifiability) results to new kernel distributions. This criterion, based on functional relationships between the relevant kernels' moment-generating functions or Laplace transforms, may be applied to continuous mixtures of both discrete and continuous random variables. To illustrate the proposed approach, we present results for several specific kernels.
From Abstract to Actionable: Pairwise Shapley Values for Explainable AI
Feb 18, 2025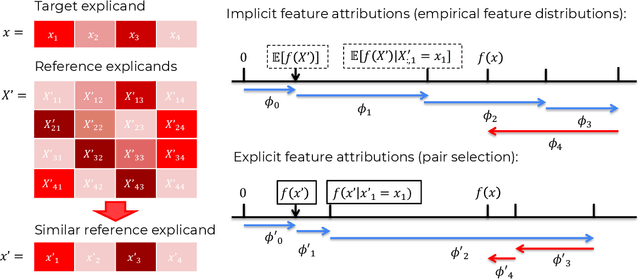

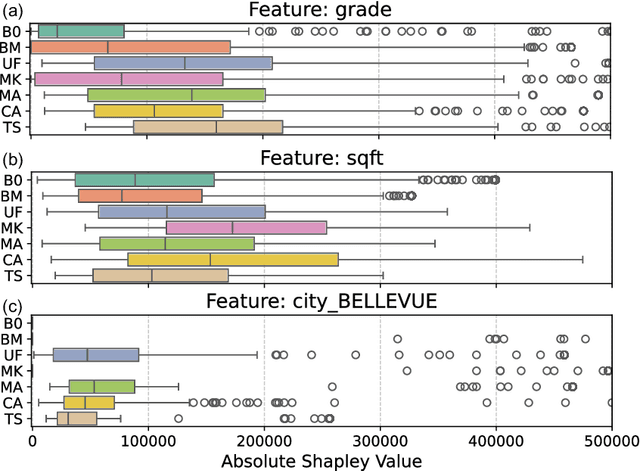
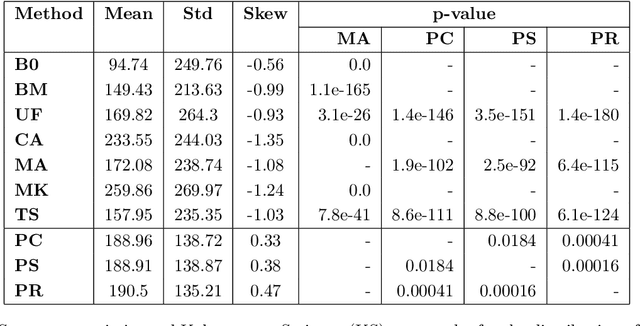
Explainable AI (XAI) is critical for ensuring transparency, accountability, and trust in machine learning systems as black-box models are increasingly deployed within high-stakes domains. Among XAI methods, Shapley values are widely used for their fairness and consistency axioms. However, prevalent Shapley value approximation methods commonly rely on abstract baselines or computationally intensive calculations, which can limit their interpretability and scalability. To address such challenges, we propose Pairwise Shapley Values, a novel framework that grounds feature attributions in explicit, human-relatable comparisons between pairs of data instances proximal in feature space. Our method introduces pairwise reference selection combined with single-value imputation to deliver intuitive, model-agnostic explanations while significantly reducing computational overhead. Here, we demonstrate that Pairwise Shapley Values enhance interpretability across diverse regression and classification scenarios--including real estate pricing, polymer property prediction, and drug discovery datasets. We conclude that the proposed methods enable more transparent AI systems and advance the real-world applicability of XAI.
Robot-Initiated Social Control of Sedentary Behavior: Comparing the Impact of Relationship- and Target-Focused Strategies
Feb 12, 2025



To design social robots to effectively promote health behavior change, it is essential to understand how people respond to various health communication strategies employed by these robots. This study examines the effectiveness of two types of social control strategies from a social robot, relationship-focused strategies (emphasizing relational consequences) and target-focused strategies (emphasizing health consequences), in encouraging people to reduce sedentary behavior. A two-session lab experiment was conducted (n = 135), where participants first played a game with a robot, followed by the robot persuading them to stand up and move using one of the strategies. Half of the participants joined a second session to have a repeated interaction with the robot. Results showed that relationship-focused strategies motivated participants to stay active longer. Repeated sessions did not strengthen participants' relationship with the robot, but those who felt more attached to the robot responded more actively to the target-focused strategies. These findings offer valuable insights for designing persuasive strategies for social robots in health communication contexts.
Benchmarking Complex Instruction-Following with Multiple Constraints Composition
Jul 04, 2024



Instruction following is one of the fundamental capabilities of large language models (LLMs). As the ability of LLMs is constantly improving, they have been increasingly applied to deal with complex human instructions in real-world scenarios. Therefore, how to evaluate the ability of complex instruction-following of LLMs has become a critical research problem. Existing benchmarks mainly focus on modeling different types of constraints in human instructions while neglecting the composition of different constraints, which is an indispensable constituent in complex instructions. To this end, we propose ComplexBench, a benchmark for comprehensively evaluating the ability of LLMs to follow complex instructions composed of multiple constraints. We propose a hierarchical taxonomy for complex instructions, including 4 constraint types, 19 constraint dimensions, and 4 composition types, and manually collect a high-quality dataset accordingly. To make the evaluation reliable, we augment LLM-based evaluators with rules to effectively verify whether generated texts can satisfy each constraint and composition. Furthermore, we obtain the final evaluation score based on the dependency structure determined by different composition types. ComplexBench identifies significant deficiencies in existing LLMs when dealing with complex instructions with multiple constraints composition.
Demonstrating HumanTHOR: A Simulation Platform and Benchmark for Human-Robot Collaboration in a Shared Workspace
Jun 10, 2024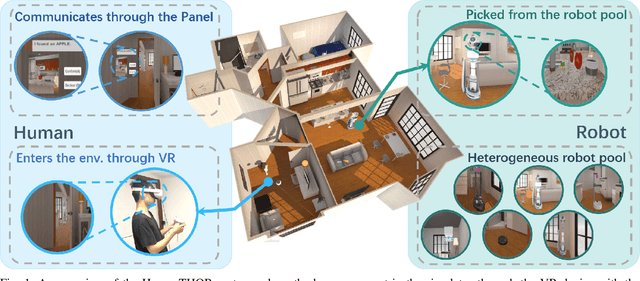



Human-robot collaboration (HRC) in a shared workspace has become a common pattern in real-world robot applications and has garnered significant research interest. However, most existing studies for human-in-the-loop (HITL) collaboration with robots in a shared workspace evaluate in either simplified game environments or physical platforms, falling short in limited realistic significance or limited scalability. To support future studies, we build an embodied framework named HumanTHOR, which enables humans to act in the simulation environment through VR devices to support HITL collaborations in a shared workspace. To validate our system, we build a benchmark of everyday tasks and conduct a preliminary user study with two baseline algorithms. The results show that the robot can effectively assist humans in collaboration, demonstrating the significance of HRC. The comparison among different levels of baselines affirms that our system can adequately evaluate robot capabilities and serve as a benchmark for different robot algorithms. The experimental results also indicate that there is still much room in the area and our system can provide a preliminary foundation for future HRC research in a shared workspace. More information about the simulation environment, experiment videos, benchmark descriptions, and additional supplementary materials can be found on the website: https://sites.google.com/view/humanthor/.
Inverse Molecular Design with Multi-Conditional Diffusion Guidance
Jan 24, 2024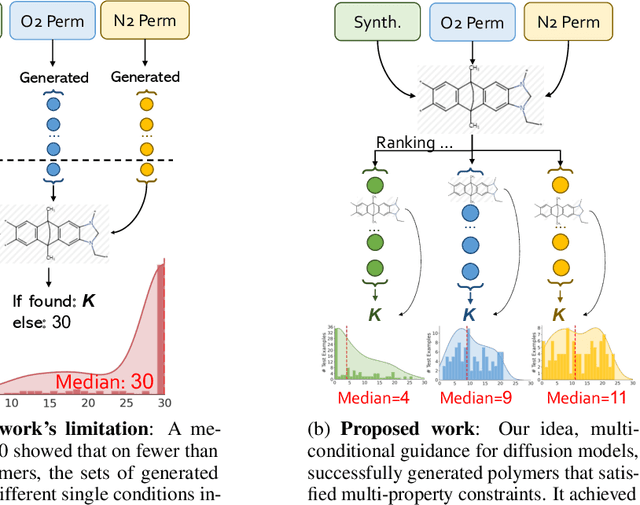
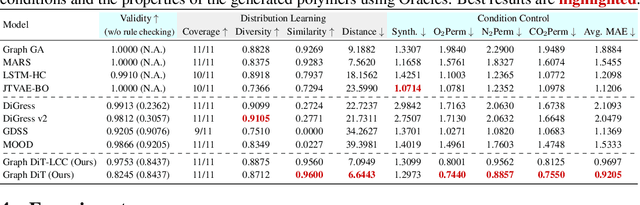
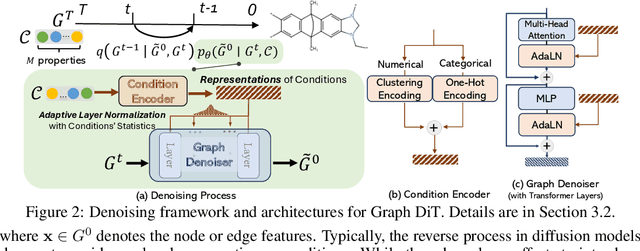
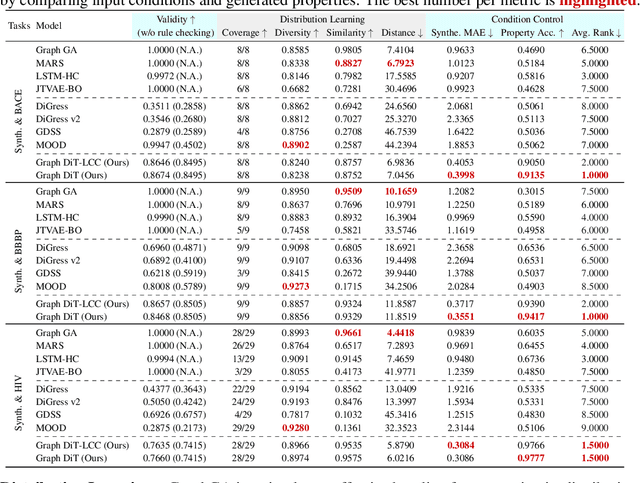
Inverse molecular design with diffusion models holds great potential for advancements in material and drug discovery. Despite success in unconditional molecule generation, integrating multiple properties such as synthetic score and gas permeability as condition constraints into diffusion models remains unexplored. We introduce multi-conditional diffusion guidance. The proposed Transformer-based denoising model has a condition encoder that learns the representations of numerical and categorical conditions. The denoising model, consisting of a structure encoder-decoder, is trained for denoising under the representation of conditions. The diffusion process becomes graph-dependent to accurately estimate graph-related noise in molecules, unlike the previous models that focus solely on the marginal distributions of atoms or bonds. We extensively validate our model for multi-conditional polymer and small molecule generation. Results demonstrate our superiority across metrics from distribution learning to condition control for molecular properties. An inverse polymer design task for gas separation with feedback from domain experts further demonstrates its practical utility.