 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen Polymer Challenge: Post-Competition Report
Dec 09, 2025Machine learning (ML) offers a powerful path toward discovering sustainable polymer materials, but progress has been limited by the lack of large, high-quality, and openly accessible polymer datasets. The Open Polymer Challenge (OPC) addresses this gap by releasing the first community-developed benchmark for polymer informatics, featuring a dataset with 10K polymers and 5 properties: thermal conductivity, radius of gyration, density, fractional free volume, and glass transition temperature. The challenge centers on multi-task polymer property prediction, a core step in virtual screening pipelines for materials discovery. Participants developed models under realistic constraints that include small data, label imbalance, and heterogeneous simulation sources, using techniques such as feature-based augmentation, transfer learning, self-supervised pretraining, and targeted ensemble strategies. The competition also revealed important lessons about data preparation, distribution shifts, and cross-group simulation consistency, informing best practices for future large-scale polymer datasets. The resulting models, analysis, and released data create a new foundation for molecular AI in polymer science and are expected to accelerate the development of sustainable and energy-efficient materials. Along with the competition, we release the test dataset at https://www.kaggle.com/datasets/alexliu99/neurips-open-polymer-prediction-2025-test-data. We also release the data generation pipeline at https://github.com/sobinalosious/ADEPT, which simulates more than 25 properties, including thermal conductivity, radius of gyration, and density.
Learning Repetition-Invariant Representations for Polymer Informatics
May 15, 2025Polymers are large macromolecules composed of repeating structural units known as monomers and are widely applied in fields such as energy storage, construction, medicine, and aerospace. However, existing graph neural network methods, though effective for small molecules, only model the single unit of polymers and fail to produce consistent vector representations for the true polymer structure with varying numbers of units. To address this challenge, we introduce Graph Repetition Invariance (GRIN), a novel method to learn polymer representations that are invariant to the number of repeating units in their graph representations. GRIN integrates a graph-based maximum spanning tree alignment with repeat-unit augmentation to ensure structural consistency. We provide theoretical guarantees for repetition-invariance from both model and data perspectives, demonstrating that three repeating units are the minimal augmentation required for optimal invariant representation learning. GRIN outperforms state-of-the-art baselines on both homopolymer and copolymer benchmarks, learning stable, repetition-invariant representations that generalize effectively to polymer chains of unseen sizes.
Predicting Stress and Damage in Carbon Fiber-Reinforced Composites Deformation Process using Composite U-Net Surrogate Model
Apr 19, 2025Carbon fiber-reinforced composites (CFRC) are pivotal in advanced engineering applications due to their exceptional mechanical properties. A deep understanding of CFRC behavior under mechanical loading is essential for optimizing performance in demanding applications such as aerospace structures. While traditional Finite Element Method (FEM) simulations, including advanced techniques like Interface-enriched Generalized FEM (IGFEM), offer valuable insights, they can struggle with computational efficiency. Existing data-driven surrogate models partially address these challenges by predicting propagated damage or stress-strain behavior but fail to comprehensively capture the evolution of stress and damage throughout the entire deformation history, including crack initiation and propagation. This study proposes a novel auto-regressive composite U-Net deep learning model to simultaneously predict stress and damage fields during CFRC deformation. By leveraging the U-Net architecture's ability to capture spatial features and integrate macro- and micro-scale phenomena, the proposed model overcomes key limitations of prior approaches. The model achieves high accuracy in predicting evolution of stress and damage distribution within the microstructure of a CFRC under unidirectional strain, offering a speed-up of over 60 times compared to IGFEM.
Implicit Neural Differential Model for Spatiotemporal Dynamics
Apr 03, 2025Hybrid neural-physics modeling frameworks through differentiable programming have emerged as powerful tools in scientific machine learning, enabling the integration of known physics with data-driven learning to improve prediction accuracy and generalizability. However, most existing hybrid frameworks rely on explicit recurrent formulations, which suffer from numerical instability and error accumulation during long-horizon forecasting. In this work, we introduce Im-PiNDiff, a novel implicit physics-integrated neural differentiable solver for stable and accurate modeling of spatiotemporal dynamics. Inspired by deep equilibrium models, Im-PiNDiff advances the state using implicit fixed-point layers, enabling robust long-term simulation while remaining fully end-to-end differentiable. To enable scalable training, we introduce a hybrid gradient propagation strategy that integrates adjoint-state methods with reverse-mode automatic differentiation. This approach eliminates the need to store intermediate solver states and decouples memory complexity from the number of solver iterations, significantly reducing training overhead. We further incorporate checkpointing techniques to manage memory in long-horizon rollouts. Numerical experiments on various spatiotemporal PDE systems, including advection-diffusion processes, Burgers' dynamics, and multi-physics chemical vapor infiltration processes, demonstrate that Im-PiNDiff achieves superior predictive performance, enhanced numerical stability, and substantial reductions in memory and runtime cost relative to explicit and naive implicit baselines. This work provides a principled, efficient, and scalable framework for hybrid neural-physics modeling.
POINT$^{2}$: A Polymer Informatics Training and Testing Database
Mar 30, 2025



The advancement of polymer informatics has been significantly propelled by the integration of machine learning (ML) techniques, enabling the rapid prediction of polymer properties and expediting the discovery of high-performance polymeric materials. However, the field lacks a standardized workflow that encompasses prediction accuracy, uncertainty quantification, ML interpretability, and polymer synthesizability. In this study, we introduce POINT$^{2}$ (POlymer INformatics Training and Testing), a comprehensive benchmark database and protocol designed to address these critical challenges. Leveraging the existing labeled datasets and the unlabeled PI1M dataset, a collection of approximately one million virtual polymers generated via a recurrent neural network trained on the realistic polymers, we develop an ensemble of ML models, including Quantile Random Forests, Multilayer Perceptrons with dropout, Graph Neural Networks, and pretrained large language models. These models are coupled with diverse polymer representations such as Morgan, MACCS, RDKit, Topological, Atom Pair fingerprints, and graph-based descriptors to achieve property predictions, uncertainty estimations, model interpretability, and template-based polymerization synthesizability across a spectrum of properties, including gas permeability, thermal conductivity, glass transition temperature, melting temperature, fractional free volume, and density. The POINT$^{2}$ database can serve as a valuable resource for the polymer informatics community for polymer discovery and optimization.
Inverse Molecular Design with Multi-Conditional Diffusion Guidance
Jan 24, 2024Inverse molecular design with diffusion models holds great potential for advancements in material and drug discovery. Despite success in unconditional molecule generation, integrating multiple properties such as synthetic score and gas permeability as condition constraints into diffusion models remains unexplored. We introduce multi-conditional diffusion guidance. The proposed Transformer-based denoising model has a condition encoder that learns the representations of numerical and categorical conditions. The denoising model, consisting of a structure encoder-decoder, is trained for denoising under the representation of conditions. The diffusion process becomes graph-dependent to accurately estimate graph-related noise in molecules, unlike the previous models that focus solely on the marginal distributions of atoms or bonds. We extensively validate our model for multi-conditional polymer and small molecule generation. Results demonstrate our superiority across metrics from distribution learning to condition control for molecular properties. An inverse polymer design task for gas separation with feedback from domain experts further demonstrates its practical utility.
DiffHybrid-UQ: Uncertainty Quantification for Differentiable Hybrid Neural Modeling
Dec 30, 2023The hybrid neural differentiable models mark a significant advancement in the field of scientific machine learning. These models, integrating numerical representations of known physics into deep neural networks, offer enhanced predictive capabilities and show great potential for data-driven modeling of complex physical systems. However, a critical and yet unaddressed challenge lies in the quantification of inherent uncertainties stemming from multiple sources. Addressing this gap, we introduce a novel method, DiffHybrid-UQ, for effective and efficient uncertainty propagation and estimation in hybrid neural differentiable models, leveraging the strengths of deep ensemble Bayesian learning and nonlinear transformations. Specifically, our approach effectively discerns and quantifies both aleatoric uncertainties, arising from data noise, and epistemic uncertainties, resulting from model-form discrepancies and data sparsity. This is achieved within a Bayesian model averaging framework, where aleatoric uncertainties are modeled through hybrid neural models. The unscented transformation plays a pivotal role in enabling the flow of these uncertainties through the nonlinear functions within the hybrid model. In contrast, epistemic uncertainties are estimated using an ensemble of stochastic gradient descent (SGD) trajectories. This approach offers a practical approximation to the posterior distribution of both the network parameters and the physical parameters. Notably, the DiffHybrid-UQ framework is designed for simplicity in implementation and high scalability, making it suitable for parallel computing environments. The merits of the proposed method have been demonstrated through problems governed by both ordinary and partial differentiable equations.
Probabilistic Physics-integrated Neural Differentiable Modeling for Isothermal Chemical Vapor Infiltration Process
Nov 13, 2023



Chemical vapor infiltration (CVI) is a widely adopted manufacturing technique used in producing carbon-carbon and carbon-silicon carbide composites. These materials are especially valued in the aerospace and automotive industries for their robust strength and lightweight characteristics. The densification process during CVI critically influences the final performance, quality, and consistency of these composite materials. Experimentally optimizing the CVI processes is challenging due to long experimental time and large optimization space. To address these challenges, this work takes a modeling-centric approach. Due to the complexities and limited experimental data of the isothermal CVI densification process, we have developed a data-driven predictive model using the physics-integrated neural differentiable (PiNDiff) modeling framework. An uncertainty quantification feature has been embedded within the PiNDiff method, bolstering the model's reliability and robustness. Through comprehensive numerical experiments involving both synthetic and real-world manufacturing data, the proposed method showcases its capability in modeling densification during the CVI process. This research highlights the potential of the PiNDiff framework as an instrumental tool for advancing our understanding, simulation, and optimization of the CVI manufacturing process, particularly when faced with sparse data and an incomplete description of the underlying physics.
Semi-Supervised Graph Imbalanced Regression
May 20, 2023Data imbalance is easily found in annotated data when the observations of certain continuous label values are difficult to collect for regression tasks. When they come to molecule and polymer property predictions, the annotated graph datasets are often small because labeling them requires expensive equipment and effort. To address the lack of examples of rare label values in graph regression tasks, we propose a semi-supervised framework to progressively balance training data and reduce model bias via self-training. The training data balance is achieved by (1) pseudo-labeling more graphs for under-represented labels with a novel regression confidence measurement and (2) augmenting graph examples in latent space for remaining rare labels after data balancing with pseudo-labels. The former is to identify quality examples from unlabeled data whose labels are confidently predicted and sample a subset of them with a reverse distribution from the imbalanced annotated data. The latter collaborates with the former to target a perfect balance using a novel label-anchored mixup algorithm. We perform experiments in seven regression tasks on graph datasets. Results demonstrate that the proposed framework significantly reduces the error of predicted graph properties, especially in under-represented label areas.
Data-Centric Learning from Unlabeled Graphs with Diffusion Model
Mar 17, 2023
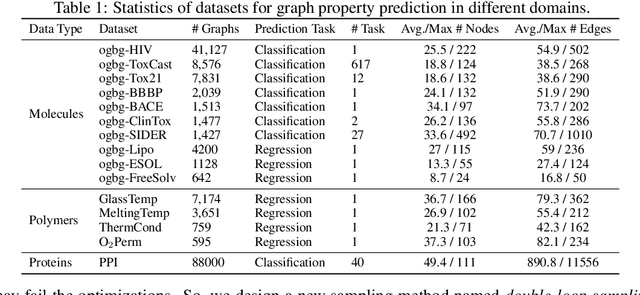
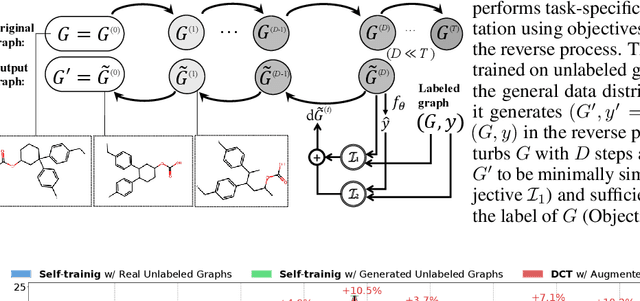
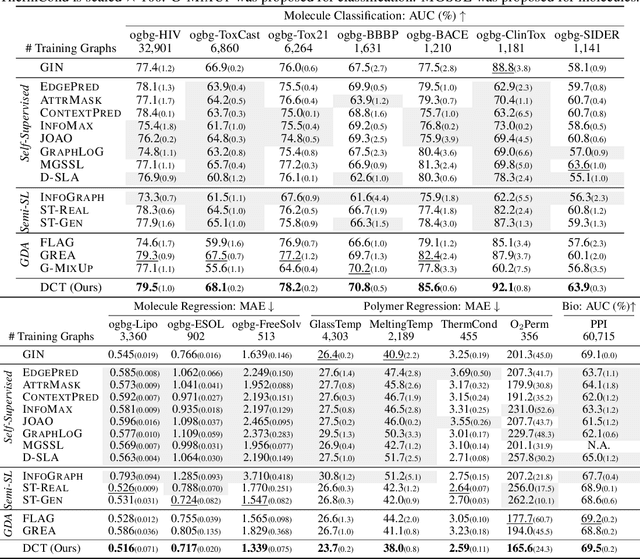
Graph property prediction tasks are important and numerous. While each task offers a small size of labeled examples, unlabeled graphs have been collected from various sources and at a large scale. A conventional approach is training a model with the unlabeled graphs on self-supervised tasks and then fine-tuning the model on the prediction tasks. However, the self-supervised task knowledge could not be aligned or sometimes conflicted with what the predictions needed. In this paper, we propose to extract the knowledge underlying the large set of unlabeled graphs as a specific set of useful data points to augment each property prediction model. We use a diffusion model to fully utilize the unlabeled graphs and design two new objectives to guide the model's denoising process with each task's labeled data to generate task-specific graph examples and their labels. Experiments demonstrate that our data-centric approach performs significantly better than fourteen existing various methods on fifteen tasks. The performance improvement brought by unlabeled data is visible as the generated labeled examples unlike self-supervised learning.