 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen Polymer Challenge: Post-Competition Report
Dec 09, 2025Machine learning (ML) offers a powerful path toward discovering sustainable polymer materials, but progress has been limited by the lack of large, high-quality, and openly accessible polymer datasets. The Open Polymer Challenge (OPC) addresses this gap by releasing the first community-developed benchmark for polymer informatics, featuring a dataset with 10K polymers and 5 properties: thermal conductivity, radius of gyration, density, fractional free volume, and glass transition temperature. The challenge centers on multi-task polymer property prediction, a core step in virtual screening pipelines for materials discovery. Participants developed models under realistic constraints that include small data, label imbalance, and heterogeneous simulation sources, using techniques such as feature-based augmentation, transfer learning, self-supervised pretraining, and targeted ensemble strategies. The competition also revealed important lessons about data preparation, distribution shifts, and cross-group simulation consistency, informing best practices for future large-scale polymer datasets. The resulting models, analysis, and released data create a new foundation for molecular AI in polymer science and are expected to accelerate the development of sustainable and energy-efficient materials. Along with the competition, we release the test dataset at https://www.kaggle.com/datasets/alexliu99/neurips-open-polymer-prediction-2025-test-data. We also release the data generation pipeline at https://github.com/sobinalosious/ADEPT, which simulates more than 25 properties, including thermal conductivity, radius of gyration, and density.
Learning Repetition-Invariant Representations for Polymer Informatics
May 15, 2025Polymers are large macromolecules composed of repeating structural units known as monomers and are widely applied in fields such as energy storage, construction, medicine, and aerospace. However, existing graph neural network methods, though effective for small molecules, only model the single unit of polymers and fail to produce consistent vector representations for the true polymer structure with varying numbers of units. To address this challenge, we introduce Graph Repetition Invariance (GRIN), a novel method to learn polymer representations that are invariant to the number of repeating units in their graph representations. GRIN integrates a graph-based maximum spanning tree alignment with repeat-unit augmentation to ensure structural consistency. We provide theoretical guarantees for repetition-invariance from both model and data perspectives, demonstrating that three repeating units are the minimal augmentation required for optimal invariant representation learning. GRIN outperforms state-of-the-art baselines on both homopolymer and copolymer benchmarks, learning stable, repetition-invariant representations that generalize effectively to polymer chains of unseen sizes.
Motif-aware Attribute Masking for Molecular Graph Pre-training
Sep 08, 2023



Attribute reconstruction is used to predict node or edge features in the pre-training of graph neural networks. Given a large number of molecules, they learn to capture structural knowledge, which is transferable for various downstream property prediction tasks and vital in chemistry, biomedicine, and material science. Previous strategies that randomly select nodes to do attribute masking leverage the information of local neighbors However, the over-reliance of these neighbors inhibits the model's ability to learn from higher-level substructures. For example, the model would learn little from predicting three carbon atoms in a benzene ring based on the other three but could learn more from the inter-connections between the functional groups, or called chemical motifs. In this work, we propose and investigate motif-aware attribute masking strategies to capture inter-motif structures by leveraging the information of atoms in neighboring motifs. Once each graph is decomposed into disjoint motifs, the features for every node within a sample motif are masked. The graph decoder then predicts the masked features of each node within the motif for reconstruction. We evaluate our approach on eight molecular property prediction datasets and demonstrate its advantages.
Semi-Supervised Graph Imbalanced Regression
May 20, 2023Data imbalance is easily found in annotated data when the observations of certain continuous label values are difficult to collect for regression tasks. When they come to molecule and polymer property predictions, the annotated graph datasets are often small because labeling them requires expensive equipment and effort. To address the lack of examples of rare label values in graph regression tasks, we propose a semi-supervised framework to progressively balance training data and reduce model bias via self-training. The training data balance is achieved by (1) pseudo-labeling more graphs for under-represented labels with a novel regression confidence measurement and (2) augmenting graph examples in latent space for remaining rare labels after data balancing with pseudo-labels. The former is to identify quality examples from unlabeled data whose labels are confidently predicted and sample a subset of them with a reverse distribution from the imbalanced annotated data. The latter collaborates with the former to target a perfect balance using a novel label-anchored mixup algorithm. We perform experiments in seven regression tasks on graph datasets. Results demonstrate that the proposed framework significantly reduces the error of predicted graph properties, especially in under-represented label areas.
Data-Centric Learning from Unlabeled Graphs with Diffusion Model
Mar 17, 2023
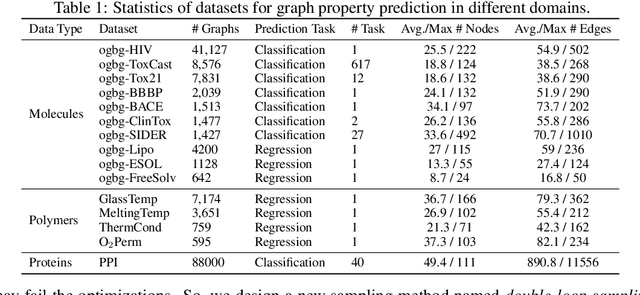
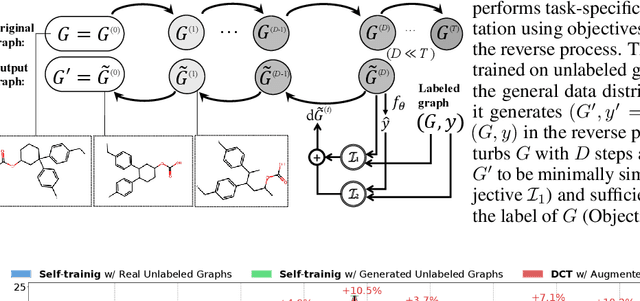
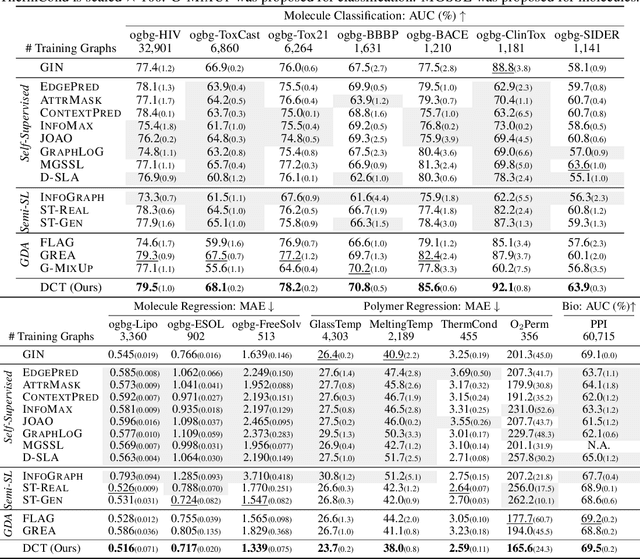
Graph property prediction tasks are important and numerous. While each task offers a small size of labeled examples, unlabeled graphs have been collected from various sources and at a large scale. A conventional approach is training a model with the unlabeled graphs on self-supervised tasks and then fine-tuning the model on the prediction tasks. However, the self-supervised task knowledge could not be aligned or sometimes conflicted with what the predictions needed. In this paper, we propose to extract the knowledge underlying the large set of unlabeled graphs as a specific set of useful data points to augment each property prediction model. We use a diffusion model to fully utilize the unlabeled graphs and design two new objectives to guide the model's denoising process with each task's labeled data to generate task-specific graph examples and their labels. Experiments demonstrate that our data-centric approach performs significantly better than fourteen existing various methods on fifteen tasks. The performance improvement brought by unlabeled data is visible as the generated labeled examples unlike self-supervised learning.