 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK-Sort Eval: Efficient Preference Evaluation for Visual Generation via Corrected VLM-as-a-Judge
Feb 10, 2026The rapid development of visual generative models raises the need for more scalable and human-aligned evaluation methods. While the crowdsourced Arena platforms offer human preference assessments by collecting human votes, they are costly and time-consuming, inherently limiting their scalability. Leveraging vision-language model (VLMs) as substitutes for manual judgments presents a promising solution. However, the inherent hallucinations and biases of VLMs hinder alignment with human preferences, thus compromising evaluation reliability. Additionally, the static evaluation approach lead to low efficiency. In this paper, we propose K-Sort Eval, a reliable and efficient VLM-based evaluation framework that integrates posterior correction and dynamic matching. Specifically, we curate a high-quality dataset from thousands of human votes in K-Sort Arena, with each instance containing the outputs and rankings of K models. When evaluating a new model, it undergoes (K+1)-wise free-for-all comparisons with existing models, and the VLM provide the rankings. To enhance alignment and reliability, we propose a posterior correction method, which adaptively corrects the posterior probability in Bayesian updating based on the consistency between the VLM prediction and human supervision. Moreover, we propose a dynamic matching strategy, which balances uncertainty and diversity to maximize the expected benefit of each comparison, thus ensuring more efficient evaluation. Extensive experiments show that K-Sort Eval delivers evaluation results consistent with K-Sort Arena, typically requiring fewer than 90 model runs, demonstrating both its efficiency and reliability.
HUG-VAS: A Hierarchical NURBS-Based Generative Model for Aortic Geometry Synthesis and Controllable Editing
Jul 15, 2025Accurate characterization of vascular geometry is essential for cardiovascular diagnosis and treatment planning. Traditional statistical shape modeling (SSM) methods rely on linear assumptions, limiting their expressivity and scalability to complex topologies such as multi-branch vascular structures. We introduce HUG-VAS, a Hierarchical NURBS Generative model for Vascular geometry Synthesis, which integrates NURBS surface parameterization with diffusion-based generative modeling to synthesize realistic, fine-grained aortic geometries. Trained with 21 patient-specific samples, HUG-VAS generates anatomically faithful aortas with supra-aortic branches, yielding biomarker distributions that closely match those of the original dataset. HUG-VAS adopts a hierarchical architecture comprising a denoising diffusion model that generates centerlines and a guided diffusion model that synthesizes radial profiles conditioned on those centerlines, thereby capturing two layers of anatomical variability. Critically, the framework supports zero-shot conditional generation from image-derived priors, enabling practical applications such as interactive semi-automatic segmentation, robust reconstruction under degraded imaging conditions, and implantable device optimization. To our knowledge, HUG-VAS is the first SSM framework to bridge image-derived priors with generative shape modeling via a unified integration of NURBS parameterization and hierarchical diffusion processes.
Batched Self-Consistency Improves LLM Relevance Assessment and Ranking
May 18, 2025Given some information need, Large Language Models (LLMs) are increasingly used for candidate text relevance assessment, typically using a one-by-one pointwise (PW) strategy where each LLM call evaluates one candidate at a time. Meanwhile, it has been shown that LLM performance can be improved through self-consistency: prompting the LLM to do the same task multiple times (possibly in perturbed ways) and then aggregating the responses. To take advantage of self-consistency, we hypothesize that batched PW strategies, where multiple passages are judged in one LLM call, are better suited than one-by-one PW methods since a larger input context can induce more diverse LLM sampling across self-consistency calls. We first propose several candidate batching strategies to create prompt diversity across self-consistency calls through subset reselection and permutation. We then test our batched PW methods on relevance assessment and ranking tasks against one-by-one PW and listwise LLM ranking baselines with and without self-consistency, using three passage retrieval datasets and GPT-4o, Claude Sonnet 3, and Amazon Nova Pro. We find that batched PW methods outperform all baselines, and show that batching can greatly amplify the positive effects of self-consistency. For instance, on our legal search dataset, GPT-4o one-by-one PW ranking NDCG@10 improves only from 44.9% to 46.8% without self-consistency vs. with 15 self consistency calls, while batched PW ranking improves from 43.8% to 51.3%, respectively.
Unsupervised Learning for Class Distribution Mismatch
May 11, 2025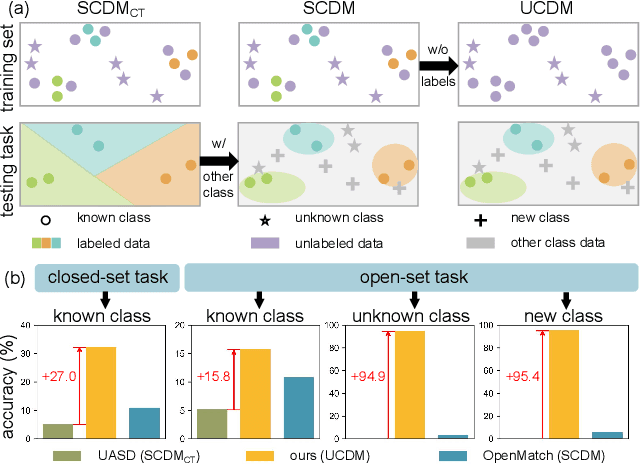

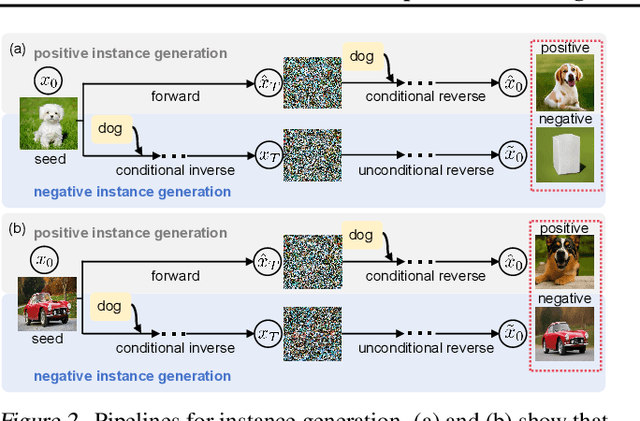

Class distribution mismatch (CDM) refers to the discrepancy between class distributions in training data and target tasks. Previous methods address this by designing classifiers to categorize classes known during training, while grouping unknown or new classes into an "other" category. However, they focus on semi-supervised scenarios and heavily rely on labeled data, limiting their applicability and performance. To address this, we propose Unsupervised Learning for Class Distribution Mismatch (UCDM), which constructs positive-negative pairs from unlabeled data for classifier training. Our approach randomly samples images and uses a diffusion model to add or erase semantic classes, synthesizing diverse training pairs. Additionally, we introduce a confidence-based labeling mechanism that iteratively assigns pseudo-labels to valuable real-world data and incorporates them into the training process. Extensive experiments on three datasets demonstrate UCDM's superiority over previous semi-supervised methods. Specifically, with a 60% mismatch proportion on Tiny-ImageNet dataset, our approach, without relying on labeled data, surpasses OpenMatch (with 40 labels per class) by 35.1%, 63.7%, and 72.5% in classifying known, unknown, and new classes.
Implicit Neural Differential Model for Spatiotemporal Dynamics
Apr 03, 2025Hybrid neural-physics modeling frameworks through differentiable programming have emerged as powerful tools in scientific machine learning, enabling the integration of known physics with data-driven learning to improve prediction accuracy and generalizability. However, most existing hybrid frameworks rely on explicit recurrent formulations, which suffer from numerical instability and error accumulation during long-horizon forecasting. In this work, we introduce Im-PiNDiff, a novel implicit physics-integrated neural differentiable solver for stable and accurate modeling of spatiotemporal dynamics. Inspired by deep equilibrium models, Im-PiNDiff advances the state using implicit fixed-point layers, enabling robust long-term simulation while remaining fully end-to-end differentiable. To enable scalable training, we introduce a hybrid gradient propagation strategy that integrates adjoint-state methods with reverse-mode automatic differentiation. This approach eliminates the need to store intermediate solver states and decouples memory complexity from the number of solver iterations, significantly reducing training overhead. We further incorporate checkpointing techniques to manage memory in long-horizon rollouts. Numerical experiments on various spatiotemporal PDE systems, including advection-diffusion processes, Burgers' dynamics, and multi-physics chemical vapor infiltration processes, demonstrate that Im-PiNDiff achieves superior predictive performance, enhanced numerical stability, and substantial reductions in memory and runtime cost relative to explicit and naive implicit baselines. This work provides a principled, efficient, and scalable framework for hybrid neural-physics modeling.
AI-Powered Automated Model Construction for Patient-Specific CFD Simulations of Aortic Flows
Mar 16, 2025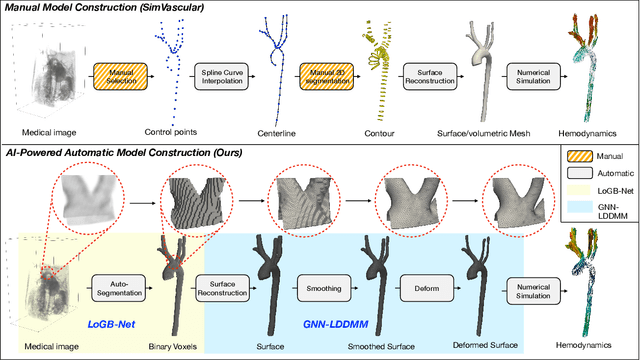

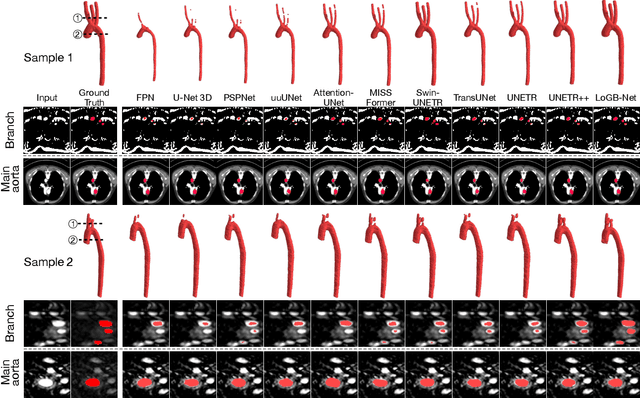
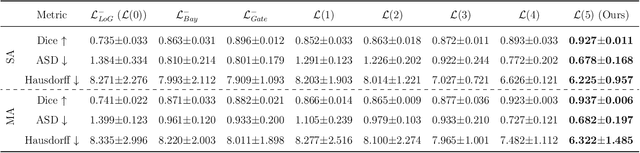
Image-based modeling is essential for understanding cardiovascular hemodynamics and advancing the diagnosis and treatment of cardiovascular diseases. Constructing patient-specific vascular models remains labor-intensive, error-prone, and time-consuming, limiting their clinical applications. This study introduces a deep-learning framework that automates the creation of simulation-ready vascular models from medical images. The framework integrates a segmentation module for accurate voxel-based vessel delineation with a surface deformation module that performs anatomically consistent and unsupervised surface refinements guided by medical image data. By unifying voxel segmentation and surface deformation into a single cohesive pipeline, the framework addresses key limitations of existing methods, enhancing geometric accuracy and computational efficiency. Evaluated on publicly available datasets, the proposed approach demonstrates state-of-the-art performance in segmentation and mesh quality while significantly reducing manual effort and processing time. This work advances the scalability and reliability of image-based computational modeling, facilitating broader applications in clinical and research settings.
Hierarchical LoG Bayesian Neural Network for Enhanced Aorta Segmentation
Jan 18, 2025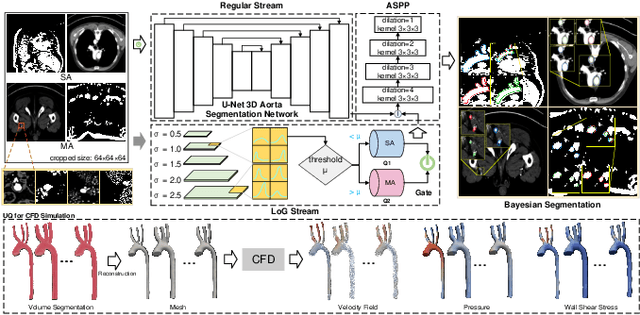



Accurate segmentation of the aorta and its associated arch branches is crucial for diagnosing aortic diseases. While deep learning techniques have significantly improved aorta segmentation, they remain challenging due to the intricate multiscale structure and the complexity of the surrounding tissues. This paper presents a novel approach for enhancing aorta segmentation using a Bayesian neural network-based hierarchical Laplacian of Gaussian (LoG) model. Our model consists of a 3D U-Net stream and a hierarchical LoG stream: the former provides an initial aorta segmentation, and the latter enhances blood vessel detection across varying scales by learning suitable LoG kernels, enabling self-adaptive handling of different parts of the aorta vessels with significant scale differences. We employ a Bayesian method to parameterize the LoG stream and provide confidence intervals for the segmentation results, ensuring robustness and reliability of the prediction for vascular medical image analysts. Experimental results show that our model can accurately segment main and supra-aortic vessels, yielding at least a 3% gain in the Dice coefficient over state-of-the-art methods across multiple volumes drawn from two aorta datasets, and can provide reliable confidence intervals for different parts of the aorta. The code is available at https://github.com/adlsn/LoGBNet.
Personalized Clustering via Targeted Representation Learning
Dec 18, 2024



Clustering traditionally aims to reveal a natural grouping structure model from unlabeled data. However, this model may not always align with users' preference. In this paper, we propose a personalized clustering method that explicitly performs targeted representation learning by interacting with users via modicum task information (e.g., $\textit{must-link}$ or $\textit{cannot-link}$ pairs) to guide the clustering direction. We query users with the most informative pairs, i.e., those pairs most hard to cluster and those most easy to miscluster, to facilitate the representation learning in terms of the clustering preference. Moreover, by exploiting attention mechanism, the targeted representation is learned and augmented. By leveraging the targeted representation and constrained constrastive loss as well, personalized clustering is obtained. Theoretically, we verify that the risk of personalized clustering is tightly bounded, guaranteeing that active queries to users do mitigate the clustering risk. Experimentally, extensive results show that our method performs well across different clustering tasks and datasets, even with a limited number of queries.
CoNFiLD-inlet: Synthetic Turbulence Inflow Using Generative Latent Diffusion Models with Neural Fields
Nov 21, 2024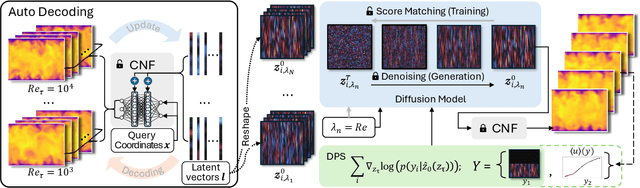
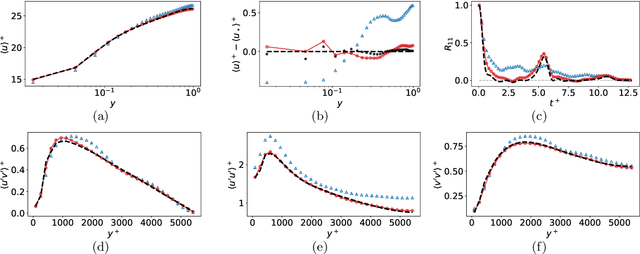
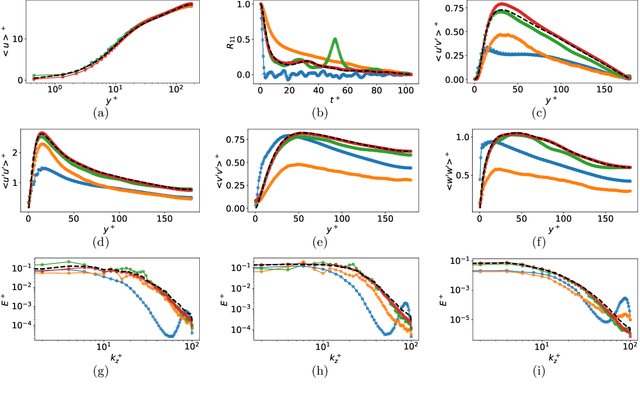
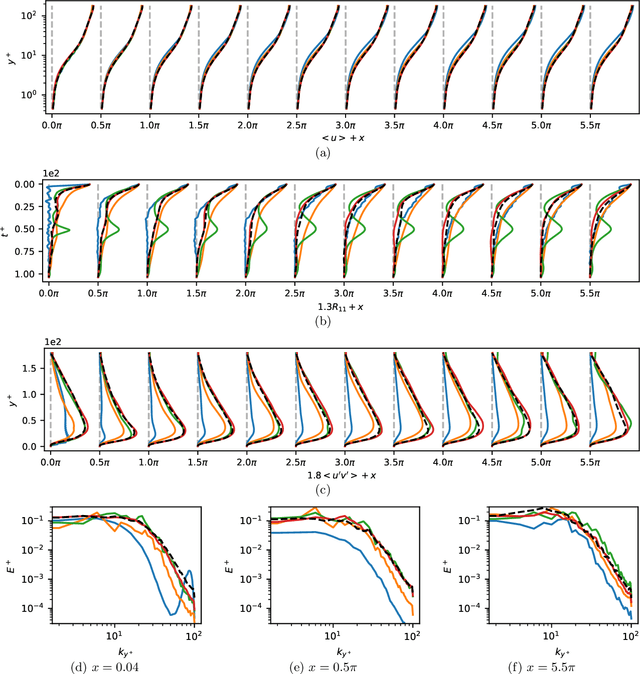
Eddy-resolving turbulence simulations require stochastic inflow conditions that accurately replicate the complex, multi-scale structures of turbulence. Traditional recycling-based methods rely on computationally expensive precursor simulations, while existing synthetic inflow generators often fail to reproduce realistic coherent structures of turbulence. Recent advances in deep learning (DL) have opened new possibilities for inflow turbulence generation, yet many DL-based methods rely on deterministic, autoregressive frameworks prone to error accumulation, resulting in poor robustness for long-term predictions. In this work, we present CoNFiLD-inlet, a novel DL-based inflow turbulence generator that integrates diffusion models with a conditional neural field (CNF)-encoded latent space to produce realistic, stochastic inflow turbulence. By parameterizing inflow conditions using Reynolds numbers, CoNFiLD-inlet generalizes effectively across a wide range of Reynolds numbers ($Re_\tau$ between $10^3$ and $10^4$) without requiring retraining or parameter tuning. Comprehensive validation through a priori and a posteriori tests in Direct Numerical Simulation (DNS) and Wall-Modeled Large Eddy Simulation (WMLES) demonstrates its high fidelity, robustness, and scalability, positioning it as an efficient and versatile solution for inflow turbulence synthesis.
Semi-Supervised Learning via Weight-aware Distillation under Class Distribution Mismatch
Aug 23, 2023
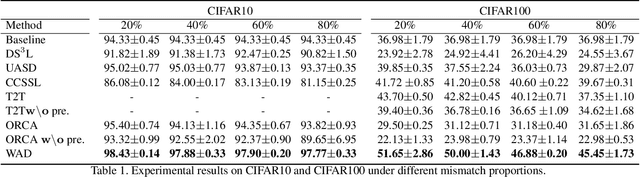


Semi-Supervised Learning (SSL) under class distribution mismatch aims to tackle a challenging problem wherein unlabeled data contain lots of unknown categories unseen in the labeled ones. In such mismatch scenarios, traditional SSL suffers severe performance damage due to the harmful invasion of the instances with unknown categories into the target classifier. In this study, by strict mathematical reasoning, we reveal that the SSL error under class distribution mismatch is composed of pseudo-labeling error and invasion error, both of which jointly bound the SSL population risk. To alleviate the SSL error, we propose a robust SSL framework called Weight-Aware Distillation (WAD) that, by weights, selectively transfers knowledge beneficial to the target task from unsupervised contrastive representation to the target classifier. Specifically, WAD captures adaptive weights and high-quality pseudo labels to target instances by exploring point mutual information (PMI) in representation space to maximize the role of unlabeled data and filter unknown categories. Theoretically, we prove that WAD has a tight upper bound of population risk under class distribution mismatch. Experimentally, extensive results demonstrate that WAD outperforms five state-of-the-art SSL approaches and one standard baseline on two benchmark datasets, CIFAR10 and CIFAR100, and an artificial cross-dataset. The code is available at https://github.com/RUC-DWBI-ML/research/tree/main/WAD-master.