 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Geometric Priors in U-Net Variants for Polyp Segmentation
Jan 24, 2026Accurate and robust polyp segmentation is essential for early colorectal cancer detection and for computer-aided diagnosis. While convolutional neural network-, Transformer-, and Mamba-based U-Net variants have achieved strong performance, they still struggle to capture geometric and structural cues, especially in low-contrast or cluttered colonoscopy scenes. To address this challenge, we propose a novel Geometric Prior-guided Module (GPM) that injects explicit geometric priors into U-Net-based architectures for polyp segmentation. Specifically, we fine-tune the Visual Geometry Grounded Transformer (VGGT) on a simulated ColonDepth dataset to estimate depth maps of polyp images tailored to the endoscopic domain. These depth maps are then processed by GPM to encode geometric priors into the encoder's feature maps, where they are further refined using spatial and channel attention mechanisms that emphasize both local spatial and global channel information. GPM is plug-and-play and can be seamlessly integrated into diverse U-Net variants. Extensive experiments on five public polyp segmentation datasets demonstrate consistent gains over three strong baselines. Code and the generated depth maps are available at: https://github.com/fvazqu/GPM-PolypSeg
R-GenIMA: Integrating Neuroimaging and Genetics with Interpretable Multimodal AI for Alzheimer's Disease Progression
Dec 22, 2025Early detection of Alzheimer's disease (AD) requires models capable of integrating macro-scale neuroanatomical alterations with micro-scale genetic susceptibility, yet existing multimodal approaches struggle to align these heterogeneous signals. We introduce R-GenIMA, an interpretable multimodal large language model that couples a novel ROI-wise vision transformer with genetic prompting to jointly model structural MRI and single nucleotide polymorphisms (SNPs) variations. By representing each anatomically parcellated brain region as a visual token and encoding SNP profiles as structured text, the framework enables cross-modal attention that links regional atrophy patterns to underlying genetic factors. Applied to the ADNI cohort, R-GenIMA achieves state-of-the-art performance in four-way classification across normal cognition (NC), subjective memory concerns (SMC), mild cognitive impairment (MCI), and AD. Beyond predictive accuracy, the model yields biologically meaningful explanations by identifying stage-specific brain regions and gene signatures, as well as coherent ROI-Gene association patterns across the disease continuum. Attention-based attribution revealed genes consistently enriched for established GWAS-supported AD risk loci, including APOE, BIN1, CLU, and RBFOX1. Stage-resolved neuroanatomical signatures identified shared vulnerability hubs across disease stages alongside stage-specific patterns: striatal involvement in subjective decline, frontotemporal engagement during prodromal impairment, and consolidated multimodal network disruption in AD. These results demonstrate that interpretable multimodal AI can synthesize imaging and genetics to reveal mechanistic insights, providing a foundation for clinically deployable tools that enable earlier risk stratification and inform precision therapeutic strategies in Alzheimer's disease.
Inferred global dense residue transition graphs from primary structure sequences enable protein interaction prediction via directed graph convolutional neural networks
Oct 15, 2025Introduction Accurate prediction of protein-protein interactions (PPIs) is crucial for understanding cellular functions and advancing drug development. Existing in-silico methods use direct sequence embeddings from Protein Language Models (PLMs). Others use Graph Neural Networks (GNNs) for 3D protein structures. This study explores less computationally intensive alternatives. We introduce a novel framework for downstream PPI prediction through link prediction. Methods We introduce a two-stage graph representation learning framework, ProtGram-DirectGCN. First, we developed ProtGram. This approach models a protein's primary structure as a hierarchy of globally inferred n-gram graphs. In these graphs, residue transition probabilities define edge weights. Each edge connects a pair of residues in a directed graph. The probabilities are aggregated from a large corpus of sequences. Second, we propose DirectGCN, a custom directed graph convolutional neural network. This model features a unique convolutional layer. It processes information through separate path-specific transformations: incoming, outgoing, and undirected. A shared transformation is also applied. These paths are combined via a learnable gating mechanism. We apply DirectGCN to ProtGram graphs to learn residue-level embeddings. These embeddings are pooled via attention to generate protein-level embeddings for prediction. Results We first established the efficacy of DirectGCN on standard node classification benchmarks. Its performance matches established methods on general datasets. The model excels at complex, directed graphs with dense, heterophilic structures. When applied to PPI prediction, the full ProtGram-DirectGCN framework delivers robust predictive power. This strong performance holds even with limited training data.
Adapting a Segmentation Foundation Model for Medical Image Classification
May 09, 2025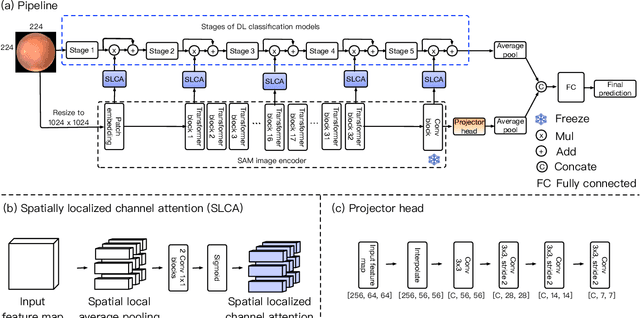
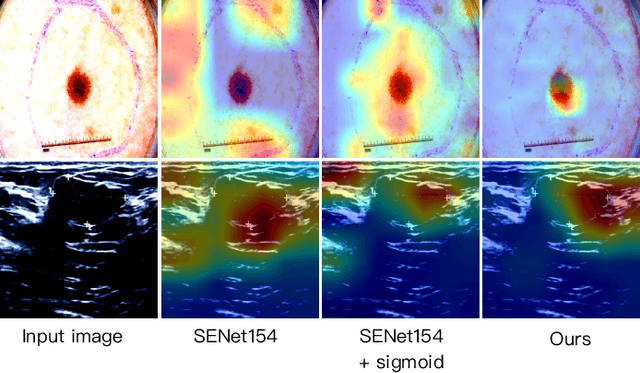
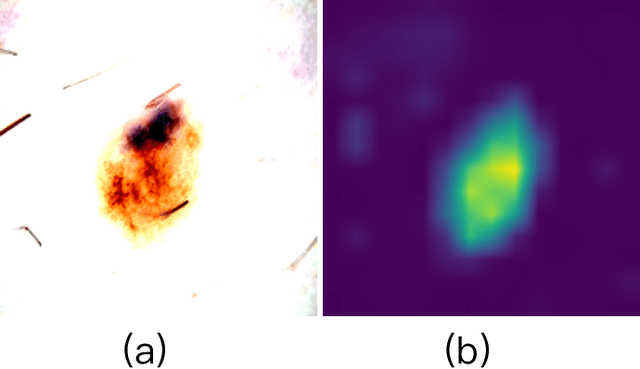
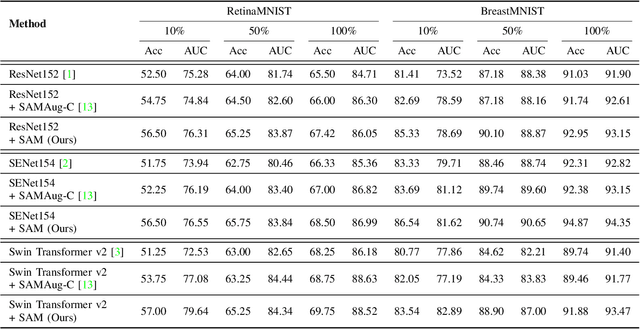
Recent advancements in foundation models, such as the Segment Anything Model (SAM), have shown strong performance in various vision tasks, particularly image segmentation, due to their impressive zero-shot segmentation capabilities. However, effectively adapting such models for medical image classification is still a less explored topic. In this paper, we introduce a new framework to adapt SAM for medical image classification. First, we utilize the SAM image encoder as a feature extractor to capture segmentation-based features that convey important spatial and contextual details of the image, while freezing its weights to avoid unnecessary overhead during training. Next, we propose a novel Spatially Localized Channel Attention (SLCA) mechanism to compute spatially localized attention weights for the feature maps. The features extracted from SAM's image encoder are processed through SLCA to compute attention weights, which are then integrated into deep learning classification models to enhance their focus on spatially relevant or meaningful regions of the image, thus improving classification performance. Experimental results on three public medical image classification datasets demonstrate the effectiveness and data-efficiency of our approach.
Topo-VM-UNetV2: Encoding Topology into Vision Mamba UNet for Polyp Segmentation
May 09, 2025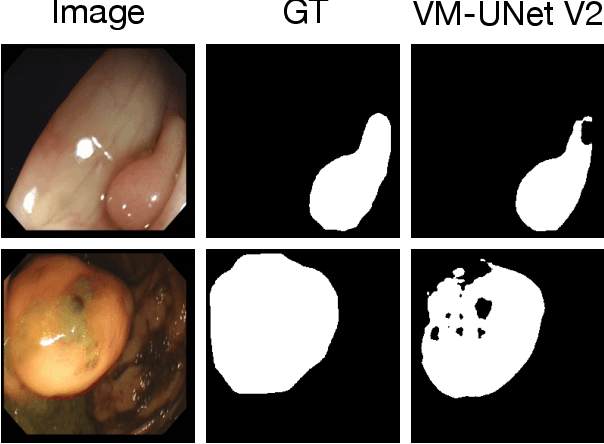
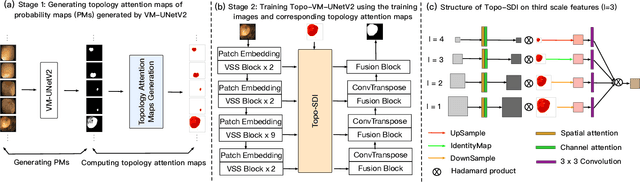


Convolutional neural network (CNN) and Transformer-based architectures are two dominant deep learning models for polyp segmentation. However, CNNs have limited capability for modeling long-range dependencies, while Transformers incur quadratic computational complexity. Recently, State Space Models such as Mamba have been recognized as a promising approach for polyp segmentation because they not only model long-range interactions effectively but also maintain linear computational complexity. However, Mamba-based architectures still struggle to capture topological features (e.g., connected components, loops, voids), leading to inaccurate boundary delineation and polyp segmentation. To address these limitations, we propose a new approach called Topo-VM-UNetV2, which encodes topological features into the Mamba-based state-of-the-art polyp segmentation model, VM-UNetV2. Our method consists of two stages: Stage 1: VM-UNetV2 is used to generate probability maps (PMs) for the training and test images, which are then used to compute topology attention maps. Specifically, we first compute persistence diagrams of the PMs, then we generate persistence score maps by assigning persistence values (i.e., the difference between death and birth times) of each topological feature to its birth location, finally we transform persistence scores into attention weights using the sigmoid function. Stage 2: These topology attention maps are integrated into the semantics and detail infusion (SDI) module of VM-UNetV2 to form a topology-guided semantics and detail infusion (Topo-SDI) module for enhancing the segmentation results. Extensive experiments on five public polyp segmentation datasets demonstrate the effectiveness of our proposed method. The code will be made publicly available.
White Light Specular Reflection Data Augmentation for Deep Learning Polyp Detection
May 08, 2025Colorectal cancer is one of the deadliest cancers today, but it can be prevented through early detection of malignant polyps in the colon, primarily via colonoscopies. While this method has saved many lives, human error remains a significant challenge, as missing a polyp could have fatal consequences for the patient. Deep learning (DL) polyp detectors offer a promising solution. However, existing DL polyp detectors often mistake white light reflections from the endoscope for polyps, which can lead to false positives.To address this challenge, in this paper, we propose a novel data augmentation approach that artificially adds more white light reflections to create harder training scenarios. Specifically, we first generate a bank of artificial lights using the training dataset. Then we find the regions of the training images that we should not add these artificial lights on. Finally, we propose a sliding window method to add the artificial light to the areas that fit of the training images, resulting in augmented images. By providing the model with more opportunities to make mistakes, we hypothesize that it will also have more chances to learn from those mistakes, ultimately improving its performance in polyp detection. Experimental results demonstrate the effectiveness of our new data augmentation method.
GenAI for Simulation Model in Model-Based Systems Engineering
Mar 09, 2025Generative AI (GenAI) has demonstrated remarkable capabilities in code generation, and its integration into complex product modeling and simulation code generation can significantly enhance the efficiency of the system design phase in Model-Based Systems Engineering (MBSE). In this study, we introduce a generative system design methodology framework for MBSE, offering a practical approach for the intelligent generation of simulation models for system physical properties. First, we employ inference techniques, generative models, and integrated modeling and simulation languages to construct simulation models for system physical properties based on product design documents. Subsequently, we fine-tune the language model used for simulation model generation on an existing library of simulation models and additional datasets generated through generative modeling. Finally, we introduce evaluation metrics for the generated simulation models for system physical properties. Our proposed approach to simulation model generation presents the innovative concept of scalable templates for simulation models. Using these templates, GenAI generates simulation models for system physical properties through code completion. The experimental results demonstrate that, for mainstream open-source Transformer-based models, the quality of the simulation model is significantly improved using the simulation model generation method proposed in this paper.
Hierarchical LoG Bayesian Neural Network for Enhanced Aorta Segmentation
Jan 18, 2025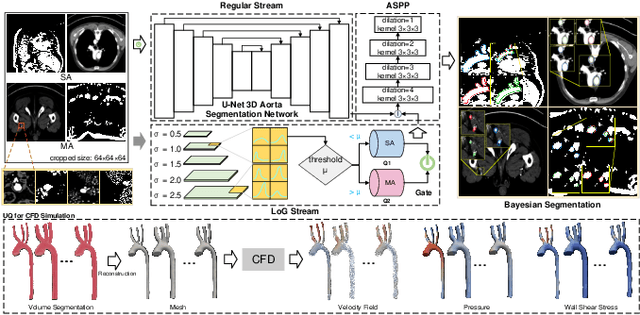



Accurate segmentation of the aorta and its associated arch branches is crucial for diagnosing aortic diseases. While deep learning techniques have significantly improved aorta segmentation, they remain challenging due to the intricate multiscale structure and the complexity of the surrounding tissues. This paper presents a novel approach for enhancing aorta segmentation using a Bayesian neural network-based hierarchical Laplacian of Gaussian (LoG) model. Our model consists of a 3D U-Net stream and a hierarchical LoG stream: the former provides an initial aorta segmentation, and the latter enhances blood vessel detection across varying scales by learning suitable LoG kernels, enabling self-adaptive handling of different parts of the aorta vessels with significant scale differences. We employ a Bayesian method to parameterize the LoG stream and provide confidence intervals for the segmentation results, ensuring robustness and reliability of the prediction for vascular medical image analysts. Experimental results show that our model can accurately segment main and supra-aortic vessels, yielding at least a 3% gain in the Dice coefficient over state-of-the-art methods across multiple volumes drawn from two aorta datasets, and can provide reliable confidence intervals for different parts of the aorta. The code is available at https://github.com/adlsn/LoGBNet.
Sli2Vol+: Segmenting 3D Medical Images Based on an Object Estimation Guided Correspondence Flow Network
Nov 21, 2024



Deep learning (DL) methods have shown remarkable successes in medical image segmentation, often using large amounts of annotated data for model training. However, acquiring a large number of diverse labeled 3D medical image datasets is highly difficult and expensive. Recently, mask propagation DL methods were developed to reduce the annotation burden on 3D medical images. For example, Sli2Vol~\cite{yeung2021sli2vol} proposed a self-supervised framework (SSF) to learn correspondences by matching neighboring slices via slice reconstruction in the training stage; the learned correspondences were then used to propagate a labeled slice to other slices in the test stage. But, these methods are still prone to error accumulation due to the inter-slice propagation of reconstruction errors. Also, they do not handle discontinuities well, which can occur between consecutive slices in 3D images, as they emphasize exploiting object continuity. To address these challenges, in this work, we propose a new SSF, called \proposed, {for segmenting any anatomical structures in 3D medical images using only a single annotated slice per training and testing volume.} Specifically, in the training stage, we first propagate an annotated 2D slice of a training volume to the other slices, generating pseudo-labels (PLs). Then, we develop a novel Object Estimation Guided Correspondence Flow Network to learn reliable correspondences between consecutive slices and corresponding PLs in a self-supervised manner. In the test stage, such correspondences are utilized to propagate a single annotated slice to the other slices of a test volume. We demonstrate the effectiveness of our method on various medical image segmentation tasks with different datasets, showing better generalizability across different organs, modalities, and modals. Code is available at \url{https://github.com/adlsn/Sli2Volplus}
FCNR: Fast Compressive Neural Representation of Visualization Images
Jul 24, 2024



We present FCNR, a fast compressive neural representation for tens of thousands of visualization images under varying viewpoints and timesteps. The existing NeRVI solution, albeit enjoying a high compression ratio, incurs slow speeds in encoding and decoding. Built on the recent advances in stereo image compression, FCNR assimilates stereo context modules and joint context transfer modules to compress image pairs. Our solution significantly improves encoding and decoding speed while maintaining high reconstruction quality and satisfying compression ratio. To demonstrate its effectiveness, we compare FCNR with state-of-the-art neural compression methods, including E-NeRV, HNeRV, NeRVI, and ECSIC. The source code can be found at https://github.com/YunfeiLu0112/FCNR.