 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFiAt-Net: Detecting Fibroatheroma Plaque Cap in 3D Intravascular OCT Images
Sep 13, 2024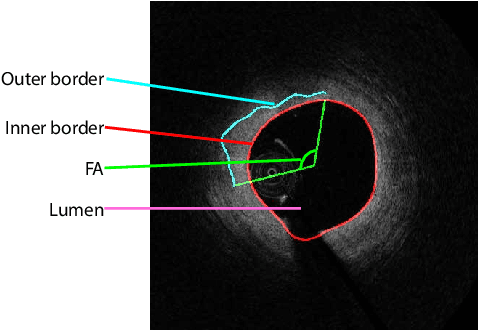

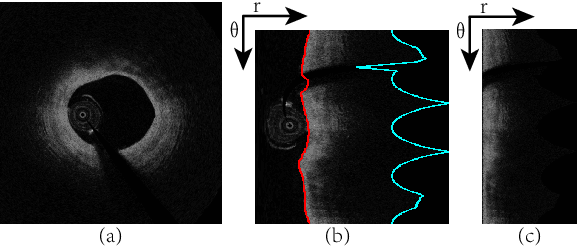
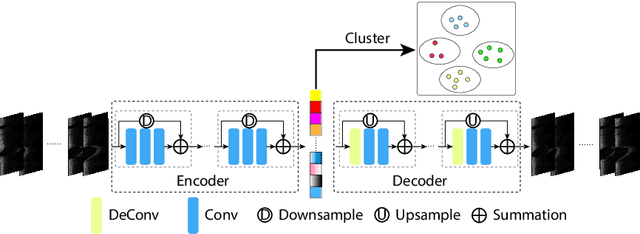
The key manifestation of coronary artery disease (CAD) is development of fibroatheromatous plaque, the cap of which may rupture and subsequently lead to coronary artery blocking and heart attack. As such, quantitative analysis of coronary plaque, its plaque cap, and consequently the cap's likelihood to rupture are of critical importance when assessing a risk of cardiovascular events. This paper reports a new deep learning based approach, called FiAt-Net, for detecting angular extent of fibroatheroma (FA) and segmenting its cap in 3D intravascular optical coherence tomography (IVOCT) images. IVOCT 2D image frames are first associated with distinct clusters and data from each cluster are used for model training. As plaque is typically focal and thus unevenly distributed, a binary partitioning method is employed to identify FA plaque areas to focus on to mitigate the data imbalance issue. Additional image representations (called auxiliary images) are generated to capture IVOCT intensity changes to help distinguish FA and non-FA areas on the coronary wall. Information in varying scales is derived from the original IVOCT and auxiliary images, and a multi-head self-attention mechanism is employed to fuse such information. Our FiAt-Net achieved high performance on a 3D IVOCT coronary image dataset, demonstrating its effectiveness in accurately detecting FA cap in IVOCT images.
Spectral U-Net: Enhancing Medical Image Segmentation via Spectral Decomposition
Sep 13, 2024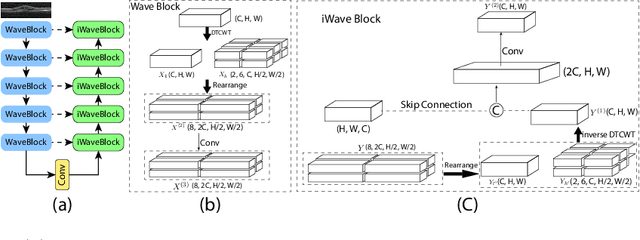

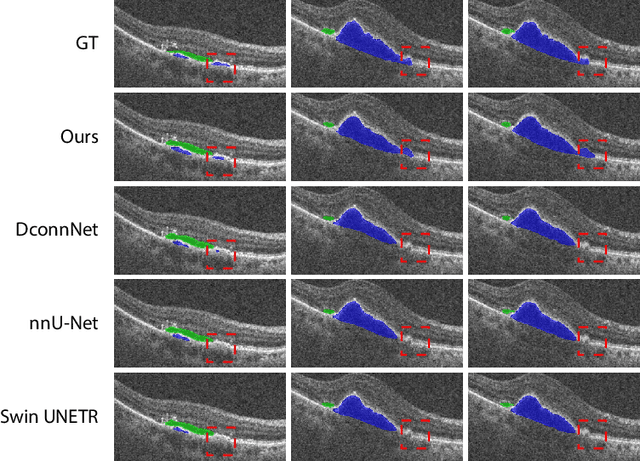

This paper introduces Spectral U-Net, a novel deep learning network based on spectral decomposition, by exploiting Dual Tree Complex Wavelet Transform (DTCWT) for down-sampling and inverse Dual Tree Complex Wavelet Transform (iDTCWT) for up-sampling. We devise the corresponding Wave-Block and iWave-Block, integrated into the U-Net architecture, aiming at mitigating information loss during down-sampling and enhancing detail reconstruction during up-sampling. In the encoder, we first decompose the feature map into high and low-frequency components using DTCWT, enabling down-sampling while mitigating information loss. In the decoder, we utilize iDTCWT to reconstruct higher-resolution feature maps from down-sampled features. Evaluations on the Retina Fluid, Brain Tumor, and Liver Tumor segmentation datasets with the nnU-Net framework demonstrate the superiority of the proposed Spectral U-Net.
Boosting Medical Image Classification with Segmentation Foundation Model
Jun 16, 2024
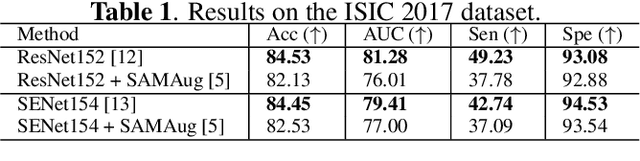
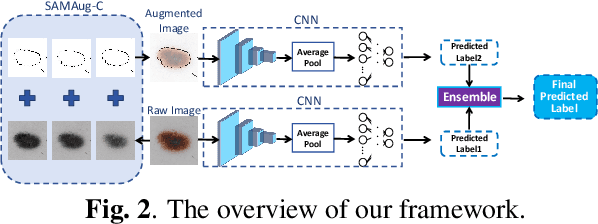
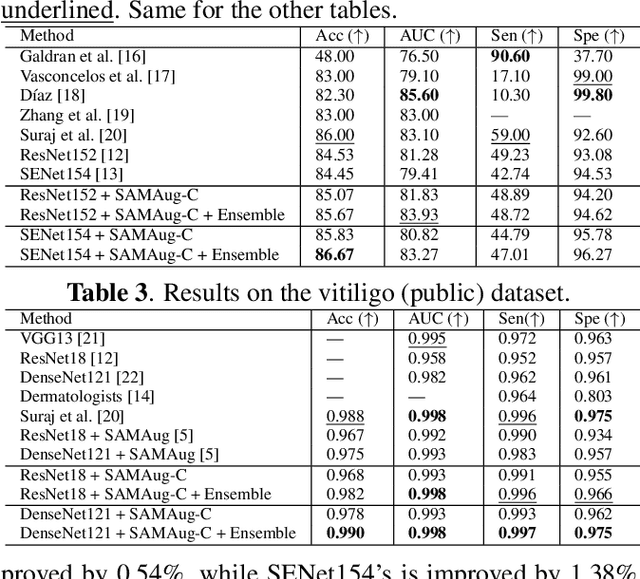
The Segment Anything Model (SAM) exhibits impressive capabilities in zero-shot segmentation for natural images. Recently, SAM has gained a great deal of attention for its applications in medical image segmentation. However, to our best knowledge, no studies have shown how to harness the power of SAM for medical image classification. To fill this gap and make SAM a true ``foundation model'' for medical image analysis, it is highly desirable to customize SAM specifically for medical image classification. In this paper, we introduce SAMAug-C, an innovative augmentation method based on SAM for augmenting classification datasets by generating variants of the original images. The augmented datasets can be used to train a deep learning classification model, thereby boosting the classification performance. Furthermore, we propose a novel framework that simultaneously processes raw and SAMAug-C augmented image input, capitalizing on the complementary information that is offered by both. Experiments on three public datasets validate the effectiveness of our new approach.
U-Net v2: Rethinking the Skip Connections of U-Net for Medical Image Segmentation
Nov 29, 2023



In this paper, we introduce U-Net v2, a new robust and efficient U-Net variant for medical image segmentation. It aims to augment the infusion of semantic information into low-level features while simultaneously refining high-level features with finer details. For an input image, we begin by extracting multi-level features with a deep neural network encoder. Next, we enhance the feature map of each level by infusing semantic information from higher-level features and integrating finer details from lower-level features through Hadamard product. Our novel skip connections empower features of all the levels with enriched semantic characteristics and intricate details. The improved features are subsequently transmitted to the decoder for further processing and segmentation. Our method can be seamlessly integrated into any Encoder-Decoder network. We evaluate our method on several public medical image segmentation datasets for skin lesion segmentation and polyp segmentation, and the experimental results demonstrate the segmentation accuracy of our new method over state-of-the-art methods, while preserving memory and computational efficiency. Code is available at: https://github.com/yaoppeng/U-Net\_v2
PHG-Net: Persistent Homology Guided Medical Image Classification
Nov 28, 2023



Modern deep neural networks have achieved great successes in medical image analysis. However, the features captured by convolutional neural networks (CNNs) or Transformers tend to be optimized for pixel intensities and neglect key anatomical structures such as connected components and loops. In this paper, we propose a persistent homology guided approach (PHG-Net) that explores topological features of objects for medical image classification. For an input image, we first compute its cubical persistence diagram and extract topological features into a vector representation using a small neural network (called the PH module). The extracted topological features are then incorporated into the feature map generated by CNN or Transformer for feature fusion. The PH module is lightweight and capable of integrating topological features into any CNN or Transformer architectures in an end-to-end fashion. We evaluate our PHG-Net on three public datasets and demonstrate its considerable improvements on the target classification tasks over state-of-the-art methods.
Keep Your Friends Close & Enemies Farther: Debiasing Contrastive Learning with Spatial Priors in 3D Radiology Images
Nov 16, 2022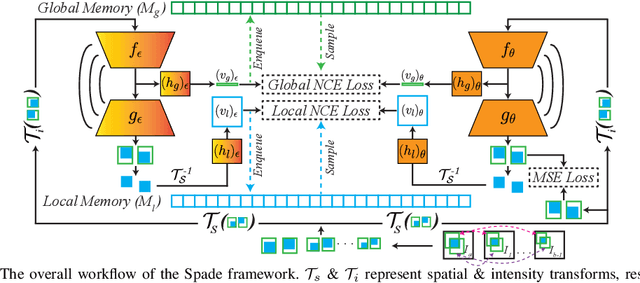
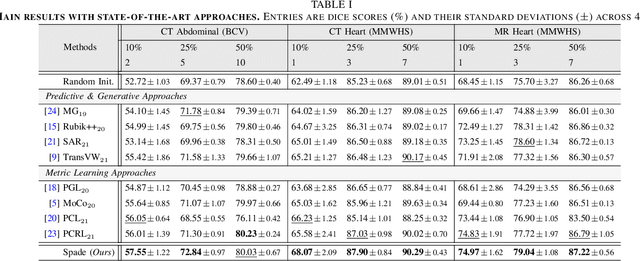
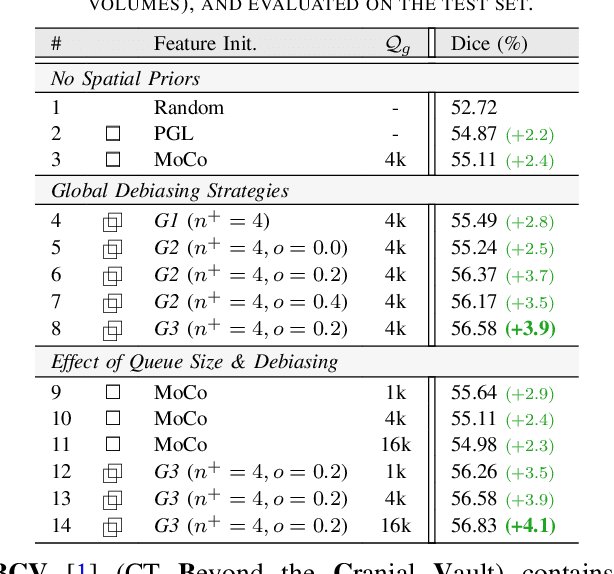
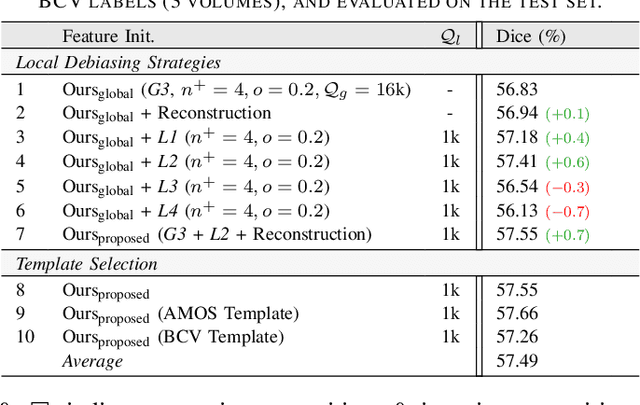
Understanding of spatial attributes is central to effective 3D radiology image analysis where crop-based learning is the de facto standard. Given an image patch, its core spatial properties (e.g., position & orientation) provide helpful priors on expected object sizes, appearances, and structures through inherent anatomical consistencies. Spatial correspondences, in particular, can effectively gauge semantic similarities between inter-image regions, while their approximate extraction requires no annotations or overbearing computational costs. However, recent 3D contrastive learning approaches either neglect correspondences or fail to maximally capitalize on them. To this end, we propose an extensible 3D contrastive framework (Spade, for Spatial Debiasing) that leverages extracted correspondences to select more effective positive & negative samples for representation learning. Our method learns both globally invariant and locally equivariant representations with downstream segmentation in mind. We also propose separate selection strategies for global & local scopes that tailor to their respective representational requirements. Compared to recent state-of-the-art approaches, Spade shows notable improvements on three downstream segmentation tasks (CT Abdominal Organ, CT Heart, MR Heart).