 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense2MoE: Pushing the Pareto Frontier of On-Device LLMs via Unified Pruning and Upcycling
May 26, 2026The Mixture of Experts MoE architecture is highly promising for resource constrained on device deployments yet training these models from scratch incurs prohibitive costs Current methods attempt to alleviate this by upcycling dense models into MoEs however they often introduce parameter redundancy that degrades inference efficiency Alternatively standard layer pruning mitigates redundancy but inevitably compromises model accuracy To resolve this dilemma we propose Dense2MoE a novel framework that unifies pruning and upcycling through Layer Fusion UpCycling LF UC Guided by hardware Roofline theory Dense2MoE systematically overcomes the inference memory wall by pruning bandwidth heavy attention modules from redundant layers while repurposing their Multi Layer Perceptrons MLPs into MoE experts This structural innovation preserves the models core capabilities and strictly limits active parameters via selective token routing With a modest continual pre training budget Dense2MoE efficiently converts publicly available dense LLMs into on device ready MoE models Extensive experiments demonstrate that Dense2MoE significantly advances the Pareto frontier for on device inference latency versus model accuracy outperforming dense baselines state of the art compression and standard upcycling methods
Lngram: N-gram Conditional Memory in Latent Space
May 24, 2026Sequence modeling requires both compositional reasoning and local static knowledge retrieval, yet standard Transformers handle both through dense computation. Engram partially decouples retrieval from the backbone, but its token-based keys remain tied to text tokenization and hash compression. We propose Lngram, a latent-space conditional memory module that learns discrete symbols directly from hidden states and performs N-gram lookup over these symbols. This design removes the dependence on tokenizer IDs and naturally extends to non-text modalities. In our evaluated settings, Lngram outperforms Transformer and Engram baselines, consistently reduces perplexity in long-context language modeling, and effectively injects domain knowledge when added post hoc to pretrained models. Joint training with the backbone further surpasses full fine-tuning, while experiments on vision-language and vision-language-action tasks show overall gains. Analyses with LogitLens and CKA suggest that Lngram enables prediction-relevant information to emerge earlier, increasing effective depth with limited inference and memory overhead. Code is available at https://github.com/zyaaa-ux/Lngram.
TS-MLLM: A Multi-Modal Large Language Model-based Framework for Industrial Time-Series Big Data Analysis
Mar 08, 2026Accurate analysis of industrial time-series big data is critical for the Prognostics and Health Management (PHM) of industrial equipment. While recent advancements in Large Language Models (LLMs) have shown promise in time-series analysis, existing methods typically focus on single-modality adaptations, failing to exploit the complementary nature of temporal signals, frequency-domain visual representations, and textual knowledge information. In this paper, we propose TS-MLLM, a unified multi-modal large language model framework designed to jointly model temporal signals, frequency-domain images, and textual domain knowledge. Specifically, we first develop an Industrial time-series Patch Modeling branch to capture long-range temporal dynamics. To integrate cross-modal priors, we introduce a Spectrum-aware Vision-Language Model Adaptation (SVLMA) mechanism that enables the model to internalize frequency-domain patterns and semantic context. Furthermore, a Temporal-centric Multi-modal Attention Fusion (TMAF) mechanism is designed to actively retrieve relevant visual and textual cues using temporal features as queries, ensuring deep cross-modal alignment. Extensive experiments on multiple industrial benchmarks demonstrate that TS-MLLM significantly outperforms state-of-the-art methods, particularly in few-shot and complex scenarios. The results validate our framework's superior robustness, efficiency, and generalization capabilities for industrial time-series prediction.
Hardware Co-Design Scaling Laws via Roofline Modelling for On-Device LLMs
Feb 10, 2026Vision-Language-Action Models (VLAs) have emerged as a key paradigm of Physical AI and are increasingly deployed in autonomous vehicles, robots, and smart spaces. In these resource-constrained on-device settings, selecting an appropriate large language model (LLM) backbone is a critical challenge: models must balance accuracy with strict inference latency and hardware efficiency constraints. This makes hardware-software co-design a game-changing requirement for on-device LLM deployment, where each hardware platform demands a tailored architectural solution. We propose a hardware co-design law that jointly captures model accuracy and inference performance. Specifically, we model training loss as an explicit function of architectural hyperparameters and characterise inference latency via roofline modelling. We empirically evaluate 1,942 candidate architectures on NVIDIA Jetson Orin, training 170 selected models for 10B tokens each to fit a scaling law relating architecture to training loss. By coupling this scaling law with latency modelling, we establish a direct accuracy-latency correspondence and identify the Pareto frontier for hardware co-designed LLMs. We further formulate architecture search as a joint optimisation over precision and performance, deriving feasible design regions under industrial hardware and application budgets. Our approach reduces architecture selection from months to days. At the same latency as Qwen2.5-0.5B on the target hardware, our co-designed architecture achieves 19.42% lower perplexity on WikiText-2. To our knowledge, this is the first principled and operational framework for hardware co-design scaling laws in on-device LLM deployment. We will make the code and related checkpoints publicly available.
SMAR: Soft Modality-Aware Routing Strategy for MoE-based Multimodal Large Language Models Preserving Language Capabilities
Jun 06, 2025Mixture of Experts (MoE) architectures have become a key approach for scaling large language models, with growing interest in extending them to multimodal tasks. Existing methods to build multimodal MoE models either incur high training costs or suffer from degraded language capabilities when adapting pretrained models. To address this, we propose Soft ModalityAware Routing (SMAR), a novel regularization technique that uses Kullback Leibler divergence to control routing probability distributions across modalities, encouraging expert specialization without modifying model architecture or heavily relying on textual data. Experiments on visual instruction tuning show that SMAR preserves language ability at 86.6% retention with only 2.5% pure text, outperforming baselines while maintaining strong multimodal performance. Our approach offers a practical and efficient solution to balance modality differentiation and language capabilities in multimodal MoE models.
StreamLink: Large-Language-Model Driven Distributed Data Engineering System
May 27, 2025Large Language Models (LLMs) have shown remarkable proficiency in natural language understanding (NLU), opening doors for innovative applications. We introduce StreamLink - an LLM-driven distributed data system designed to improve the efficiency and accessibility of data engineering tasks. We build StreamLink on top of distributed frameworks such as Apache Spark and Hadoop to handle large data at scale. One of the important design philosophies of StreamLink is to respect user data privacy by utilizing local fine-tuned LLMs instead of a public AI service like ChatGPT. With help from domain-adapted LLMs, we can improve our system's understanding of natural language queries from users in various scenarios and simplify the procedure of generating database queries like the Structured Query Language (SQL) for information processing. We also incorporate LLM-based syntax and security checkers to guarantee the reliability and safety of each generated query. StreamLink illustrates the potential of merging generative LLMs with distributed data processing for comprehensive and user-centric data engineering. With this architecture, we allow users to interact with complex database systems at different scales in a user-friendly and security-ensured manner, where the SQL generation reaches over 10\% of execution accuracy compared to baseline methods, and allow users to find the most concerned item from hundreds of millions of items within a few seconds using natural language.
FreeGraftor: Training-Free Cross-Image Feature Grafting for Subject-Driven Text-to-Image Generation
Apr 22, 2025Subject-driven image generation aims to synthesize novel scenes that faithfully preserve subject identity from reference images while adhering to textual guidance, yet existing methods struggle with a critical trade-off between fidelity and efficiency. Tuning-based approaches rely on time-consuming and resource-intensive subject-specific optimization, while zero-shot methods fail to maintain adequate subject consistency. In this work, we propose FreeGraftor, a training-free framework that addresses these limitations through cross-image feature grafting. Specifically, FreeGraftor employs semantic matching and position-constrained attention fusion to transfer visual details from reference subjects to the generated image. Additionally, our framework incorporates a novel noise initialization strategy to preserve geometry priors of reference subjects for robust feature matching. Extensive qualitative and quantitative experiments demonstrate that our method enables precise subject identity transfer while maintaining text-aligned scene synthesis. Without requiring model fine-tuning or additional training, FreeGraftor significantly outperforms existing zero-shot and training-free approaches in both subject fidelity and text alignment. Furthermore, our framework can seamlessly extend to multi-subject generation, making it practical for real-world deployment. Our code is available at https://github.com/Nihukat/FreeGraftor.
GenAI for Simulation Model in Model-Based Systems Engineering
Mar 09, 2025Generative AI (GenAI) has demonstrated remarkable capabilities in code generation, and its integration into complex product modeling and simulation code generation can significantly enhance the efficiency of the system design phase in Model-Based Systems Engineering (MBSE). In this study, we introduce a generative system design methodology framework for MBSE, offering a practical approach for the intelligent generation of simulation models for system physical properties. First, we employ inference techniques, generative models, and integrated modeling and simulation languages to construct simulation models for system physical properties based on product design documents. Subsequently, we fine-tune the language model used for simulation model generation on an existing library of simulation models and additional datasets generated through generative modeling. Finally, we introduce evaluation metrics for the generated simulation models for system physical properties. Our proposed approach to simulation model generation presents the innovative concept of scalable templates for simulation models. Using these templates, GenAI generates simulation models for system physical properties through code completion. The experimental results demonstrate that, for mainstream open-source Transformer-based models, the quality of the simulation model is significantly improved using the simulation model generation method proposed in this paper.
Collab-Overcooked: Benchmarking and Evaluating Large Language Models as Collaborative Agents
Feb 27, 2025
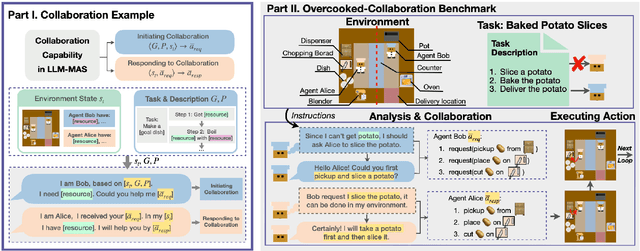

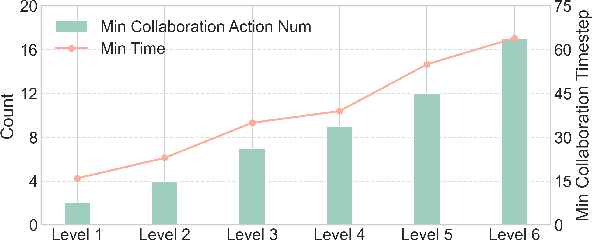
Large language models (LLMs) based agent systems have made great strides in real-world applications beyond traditional NLP tasks. This paper proposes a new LLM-powered Multi-Agent System (LLM-MAS) benchmark, Collab-Overcooked, built on the popular Overcooked-AI game with more applicable and challenging tasks in interactive environments. Collab-Overcooked extends existing benchmarks from two novel perspectives. First, it provides a multi-agent framework supporting diverse tasks and objectives and encourages collaboration through natural language communication. Second, it introduces a spectrum of process-oriented evaluation metrics to assess the fine-grained collaboration capabilities of different LLM agents, a dimension often overlooked in prior work. We conduct extensive experiments over 10 popular LLMs and show that, while the LLMs present a strong ability in goal interpretation, there is a significant discrepancy in active collaboration and continuous adaption that are critical for efficiently fulfilling complicated tasks. Notably, we highlight the strengths and weaknesses in LLM-MAS and provide insights for improving and evaluating LLM-MAS on a unified and open-sourced benchmark. Environments, 30 open-ended tasks, and an integrated evaluation package are now publicly available at https://github.com/YusaeMeow/Collab-Overcooked.
AIGC for Industrial Time Series: From Deep Generative Models to Large Generative Models
Jul 16, 2024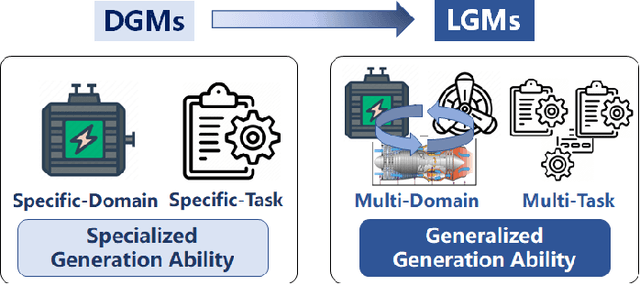
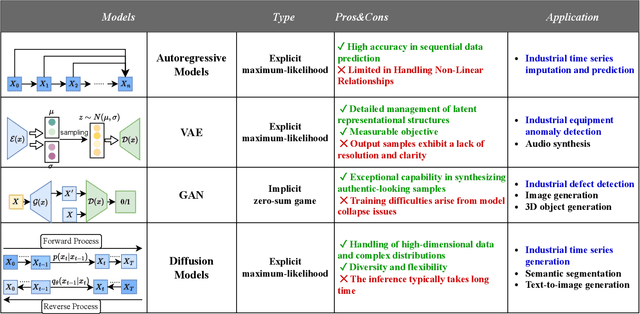
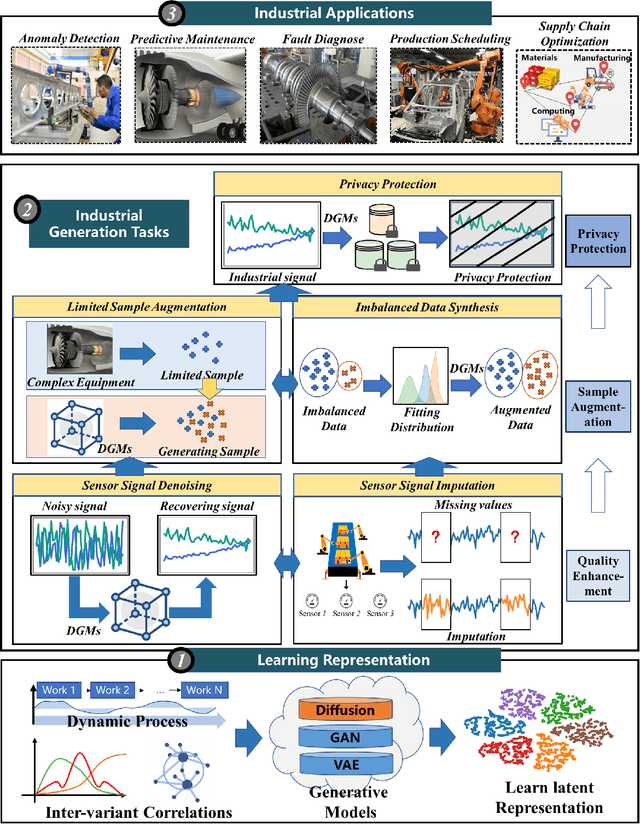
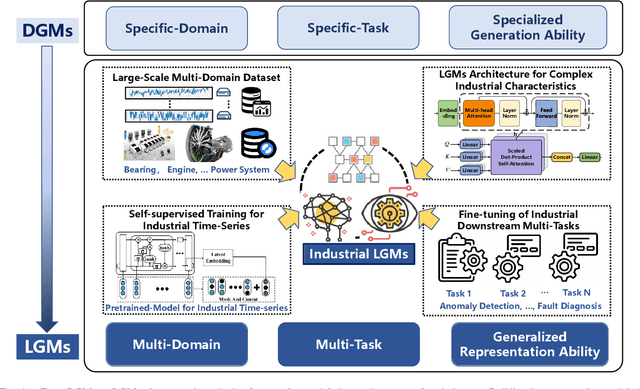
With the remarkable success of generative models like ChatGPT, Artificial Intelligence Generated Content (AIGC) is undergoing explosive development. Not limited to text and images, generative models can generate industrial time series data, addressing challenges such as the difficulty of data collection and data annotation. Due to their outstanding generation ability, they have been widely used in Internet of Things, metaverse, and cyber-physical-social systems to enhance the efficiency of industrial production. In this paper, we present a comprehensive overview of generative models for industrial time series from deep generative models (DGMs) to large generative models (LGMs). First, a DGM-based AIGC framework is proposed for industrial time series generation. Within this framework, we survey advanced industrial DGMs and present a multi-perspective categorization. Furthermore, we systematically analyze the critical technologies required to construct industrial LGMs from four aspects: large-scale industrial dataset, LGMs architecture for complex industrial characteristics, self-supervised training for industrial time series, and fine-tuning of industrial downstream tasks. Finally, we conclude the challenges and future directions to enable the development of generative models in industry.