 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Retrieval Hurts Code Completion: A Diagnostic Study of Stale Repository Context
May 14, 2026Context: Retrieval-augmented code generation relies on cross-file repository context, but retrieved snippets may come from obsolete project states. Objectives: We study whether temporally stale repository snippets act as harmless noise or actively induce current-state-incompatible code. Methods: We conduct a controlled diagnostic study on a curated 17-sample set of production-helper signature changes from five Python repositories. For each sample, we compare current-only, stale-only, no-retrieval, and mixed current/stale retrieval conditions under prompts that hide commit freshness and expected current signatures. Results: Under neutralized prompts, stale-only retrieval induces stale helper references on 15/17 Qwen2.5-Coder-7B-Instruct samples and 13/17 gpt-4.1-mini samples, corresponding to 88.2 and 76.5 percentage-point increases over current-only retrieval. No retrieval produces zero stale references but only 1/17 passing completions. The two models share 75.0% Jaccard overlap among stale-triggering samples, and mixed conditions show that adding valid current evidence largely rescues stale-only failures. Conclusion: Temporal validity of retrieved repository context is a distinct diagnostic variable for Code RAG robustness: stale context can actively bias models toward obsolete repository state rather than merely removing useful evidence.
HCRE: LLM-based Hierarchical Classification for Cross-Document Relation Extraction with a Prediction-then-Verification Strategy
Apr 09, 2026Cross-document relation extraction (RE) aims to identify relations between the head and tail entities located in different documents. Existing approaches typically adopt the paradigm of ``\textit{Small Language Model (SLM) + Classifier}''. However, the limited language understanding ability of SLMs hinders further improvement of their performance. In this paper, we conduct a preliminary study to explore the performance of Large Language Models (LLMs) in cross-document RE. Despite their extensive parameters, our findings indicate that LLMs do not consistently surpass existing SLMs. Further analysis suggests that the underperformance is largely attributed to the challenges posed by the numerous predefined relations. To overcome this issue, we propose an LLM-based \underline{H}ierarchical \underline{C}lassification model for cross-document \underline{RE} (HCRE), which consists of two core components: 1) an LLM for relation prediction and 2) a \textit{hierarchical relation tree} derived from the predefined relation set. This tree enables the LLM to perform hierarchical classification, where the target relation is inferred level by level. Since the number of child nodes is much smaller than the size of the entire predefined relation set, the hierarchical relation tree significantly reduces the number of relation options that LLM needs to consider during inference. However, hierarchical classification introduces the risk of error propagation across levels. To mitigate this, we propose a \textit{prediction-then-verification} inference strategy that improves prediction reliability through multi-view verification at each level. Extensive experiments show that HCRE outperforms existing baselines, validating its effectiveness.
PRISM: A Principled Framework for Multi-Agent Reasoning via Gain Decomposition
Feb 09, 2026Multi-agent collaboration has emerged as a promising paradigm for enhancing reasoning capabilities of Large Language Models (LLMs). However, existing approaches remain largely heuristic, lacking principled guidance on what drives performance gains and how to systematically optimize multi-agent reasoning. Specifically, it remains unclear why multi-agent collaboration outperforms single-agent reasoning and which design choices contribute most to these gains, making it difficult to build better systems. We address this gap by introducing a unified theoretical framework that decomposes multi-agent reasoning gains into three conceptually independent dimensions: Exploration for diverse solution coverage, Information for high-fidelity feedback, and Aggregation for principled consensus. Through this lens, existing methods can be understood as special cases that optimize only subsets of these dimensions. Building upon this decomposition, a novel framework called PRISM (Propose-Review-Integrate Synthesis for Multi-agent Reasoning) is proposed, which jointly maximizes all three dimensions through role-based diversity, execution-grounded feedback with evidence-based cross-evaluation, and iterative synthesis with closed-loop validation. Extensive experiments across mathematical reasoning, code generation, and function calling benchmarks demonstrate that PRISM achieves state-of-the-art performance with superior compute-efficiency compared to methods optimizing partial dimensions. The theoretical framework provides actionable design principles for future multi-agent reasoning systems.
Intrinsic-Motivation Multi-Robot Social Formation Navigation with Coordinated Exploration
Dec 16, 2025This paper investigates the application of reinforcement learning (RL) to multi-robot social formation navigation, a critical capability for enabling seamless human-robot coexistence. While RL offers a promising paradigm, the inherent unpredictability and often uncooperative dynamics of pedestrian behavior pose substantial challenges, particularly concerning the efficiency of coordinated exploration among robots. To address this, we propose a novel coordinated-exploration multi-robot RL algorithm introducing an intrinsic motivation exploration. Its core component is a self-learning intrinsic reward mechanism designed to collectively alleviate policy conservatism. Moreover, this algorithm incorporates a dual-sampling mode within the centralized training and decentralized execution framework to enhance the representation of both the navigation policy and the intrinsic reward, leveraging a two-time-scale update rule to decouple parameter updates. Empirical results on social formation navigation benchmarks demonstrate the proposed algorithm's superior performance over existing state-of-the-art methods across crucial metrics. Our code and video demos are available at: https://github.com/czxhunzi/CEMRRL.
SPAN: Benchmarking and Improving Cross-Calendar Temporal Reasoning of Large Language Models
Nov 13, 2025We introduce SPAN, a cross-calendar temporal reasoning benchmark, which requires LLMs to perform intra-calendar temporal reasoning and inter-calendar temporal conversion. SPAN features ten cross-calendar temporal reasoning directions, two reasoning types, and two question formats across six calendars. To enable time-variant and contamination-free evaluation, we propose a template-driven protocol for dynamic instance generation that enables assessment on a user-specified Gregorian date. We conduct extensive experiments on both open- and closed-source state-of-the-art (SOTA) LLMs over a range of dates spanning 100 years from 1960 to 2060. Our evaluations show that these LLMs achieve an average accuracy of only 34.5%, with none exceeding 80%, indicating that this task remains challenging. Through in-depth analysis of reasoning types, question formats, and temporal reasoning directions, we identify two key obstacles for LLMs: Future-Date Degradation and Calendar Asymmetry Bias. To strengthen LLMs' cross-calendar temporal reasoning capability, we further develop an LLM-powered Time Agent that leverages tool-augmented code generation. Empirical results show that Time Agent achieves an average accuracy of 95.31%, outperforming several competitive baselines, highlighting the potential of tool-augmented code generation to advance cross-calendar temporal reasoning. We hope this work will inspire further efforts toward more temporally and culturally adaptive LLMs.
Integrating Offline Pre-Training with Online Fine-Tuning: A Reinforcement Learning Approach for Robot Social Navigation
Oct 01, 2025Offline reinforcement learning (RL) has emerged as a promising framework for addressing robot social navigation challenges. However, inherent uncertainties in pedestrian behavior and limited environmental interaction during training often lead to suboptimal exploration and distributional shifts between offline training and online deployment. To overcome these limitations, this paper proposes a novel offline-to-online fine-tuning RL algorithm for robot social navigation by integrating Return-to-Go (RTG) prediction into a causal Transformer architecture. Our algorithm features a spatiotem-poral fusion model designed to precisely estimate RTG values in real-time by jointly encoding temporal pedestrian motion patterns and spatial crowd dynamics. This RTG prediction framework mitigates distribution shift by aligning offline policy training with online environmental interactions. Furthermore, a hybrid offline-online experience sampling mechanism is built to stabilize policy updates during fine-tuning, ensuring balanced integration of pre-trained knowledge and real-time adaptation. Extensive experiments in simulated social navigation environments demonstrate that our method achieves a higher success rate and lower collision rate compared to state-of-the-art baselines. These results underscore the efficacy of our algorithm in enhancing navigation policy robustness and adaptability. This work paves the way for more reliable and adaptive robotic navigation systems in real-world applications.
6D Pose Estimation on Point Cloud Data through Prior Knowledge Integration: A Case Study in Autonomous Disassembly
May 30, 2025The accurate estimation of 6D pose remains a challenging task within the computer vision domain, even when utilizing 3D point cloud data. Conversely, in the manufacturing domain, instances arise where leveraging prior knowledge can yield advancements in this endeavor. This study focuses on the disassembly of starter motors to augment the engineering of product life cycles. A pivotal objective in this context involves the identification and 6D pose estimation of bolts affixed to the motors, facilitating automated disassembly within the manufacturing workflow. Complicating matters, the presence of occlusions and the limitations of single-view data acquisition, notably when motors are placed in a clamping system, obscure certain portions and render some bolts imperceptible. Consequently, the development of a comprehensive pipeline capable of acquiring complete bolt information is imperative to avoid oversight in bolt detection. In this paper, employing the task of bolt detection within the scope of our project as a pertinent use case, we introduce a meticulously devised pipeline. This multi-stage pipeline effectively captures the 6D information with regard to all bolts on the motor, thereby showcasing the effective utilization of prior knowledge in handling this challenging task. The proposed methodology not only contributes to the field of 6D pose estimation but also underscores the viability of integrating domain-specific insights to tackle complex problems in manufacturing and automation.
SAMBLE: Shape-Specific Point Cloud Sampling for an Optimal Trade-Off Between Local Detail and Global Uniformity
Apr 28, 2025Driven by the increasing demand for accurate and efficient representation of 3D data in various domains, point cloud sampling has emerged as a pivotal research topic in 3D computer vision. Recently, learning-to-sample methods have garnered growing interest from the community, particularly for their ability to be jointly trained with downstream tasks. However, previous learning-based sampling methods either lead to unrecognizable sampling patterns by generating a new point cloud or biased sampled results by focusing excessively on sharp edge details. Moreover, they all overlook the natural variations in point distribution across different shapes, applying a similar sampling strategy to all point clouds. In this paper, we propose a Sparse Attention Map and Bin-based Learning method (termed SAMBLE) to learn shape-specific sampling strategies for point cloud shapes. SAMBLE effectively achieves an improved balance between sampling edge points for local details and preserving uniformity in the global shape, resulting in superior performance across multiple common point cloud downstream tasks, even in scenarios with few-point sampling.
IAP: Improving Continual Learning of Vision-Language Models via Instance-Aware Prompting
Mar 26, 2025
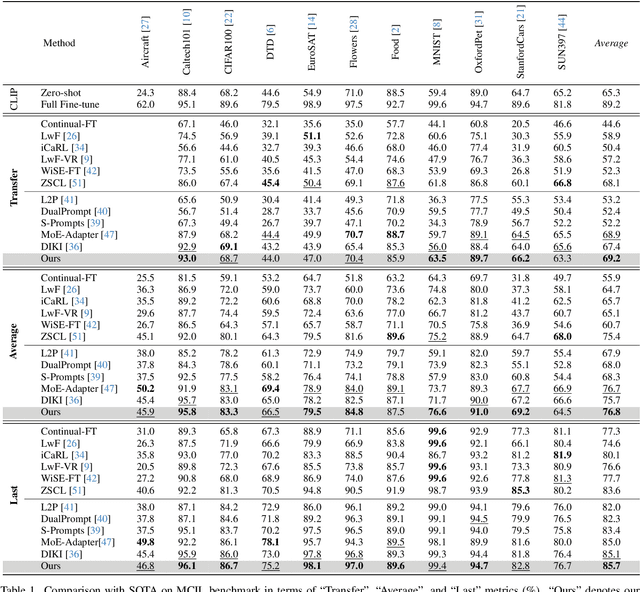
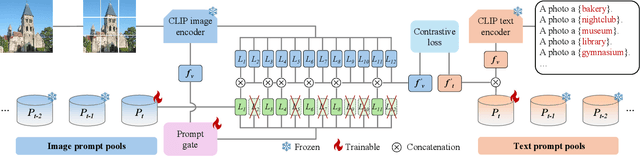
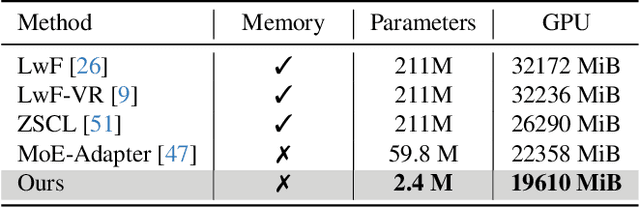
Recent pre-trained vision-language models (PT-VLMs) often face a Multi-Domain Class-Incremental Learning (MCIL) scenario in practice, where several classes and domains of multi-modal tasks are incrementally arrived. Without access to previously learned tasks and unseen tasks, memory-constrained MCIL suffers from forward and backward forgetting. To alleviate the above challenges, parameter-efficient fine-tuning techniques (PEFT), such as prompt tuning, are employed to adapt the PT-VLM to the diverse incrementally learned tasks. To achieve effective new task adaptation, existing methods only consider the effect of PEFT strategy selection, but neglect the influence of PEFT parameter setting (e.g., prompting). In this paper, we tackle the challenge of optimizing prompt designs for diverse tasks in MCIL and propose an Instance-Aware Prompting (IAP) framework. Specifically, our Instance-Aware Gated Prompting (IA-GP) module enhances adaptation to new tasks while mitigating forgetting by dynamically assigning prompts across transformer layers at the instance level. Our Instance-Aware Class-Distribution-Driven Prompting (IA-CDDP) improves the task adaptation process by determining an accurate task-label-related confidence score for each instance. Experimental evaluations across 11 datasets, using three performance metrics, demonstrate the effectiveness of our proposed method. Code can be found at https://github.com/FerdinandZJU/IAP.
Towards Automatic Continual Learning: A Self-Adaptive Framework for Continual Instruction Tuning
Mar 20, 2025


Continual instruction tuning enables large language models (LLMs) to learn incrementally while retaining past knowledge, whereas existing methods primarily focus on how to retain old knowledge rather than on selecting which new knowledge to learn. In domain-specific contexts, maintaining data quality and managing system constraints remain key challenges. To address these issues, we propose an automated continual instruction tuning framework that dynamically filters incoming data, which identify and reduce redundant data across successive updates. Our approach utilizes a small proxy model for efficient perplexity-based filtering, and updates the proxy to ensure that the filtering criteria remain aligned with the evolving state of the deployed model. Compared to existing static data selection methods, our framework can effectively handle incrementally acquired data and shifting distributions. Additionally, it addresses practical deployment challenges by enabling seamless model updates, supporting version rollback and incorporating automatic checkpoint evaluation. We evaluated the system in real-world medical scenarios. It reduced computational costs by 66.7% and improved model performance, and achieved autonomous updates, thus demonstrating its effectiveness for automatic continual instruction tuning.