 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-Based Rhythm Quantization of Performance MIDI Using Beat Annotations
Apr 24, 2026Rhythm transcription is a key subtask of notation-level Automatic Music Transcription (AMT). While deep learning models have been extensively used for detecting the metrical grid in audio and MIDI performances, beat-based rhythm quantization remains largely unexplored. In this work, we introduce a novel deep learning approach for quantizing MIDI performances using a priori beat information. Our method leverages the transformer architecture to effectively process synchronized score and performance data for training a quantization model. Key components of our approach include dataset preparation, a beat-based pre-quantization method to align performance and score times within a unified framework, and a MIDI tokenizer tailored for this task. We adapt a transformer model based on the T5 architecture to meet the specific requirements of rhythm quantization. The model is evaluated using a set of score-level metrics designed for objective assessment of quantization performance. Through systematic evaluation, we optimize both data representation and model architecture. Additionally, we apply performance and score augmentations, such as transposition, note deletion, and performance-side time jitter, to enhance the model's robustness. Finally, a qualitative analysis compares our model's quantization performance against state-of-the-art probabilistic and deep-learning models on various example pieces. Our model achieves an onset F1-score of 97.3% and a note value accuracy of 83.3% on the ASAP dataset. It generalizes well across time signatures, including those not seen during training, and produces readable score output. Fine-tuning on instrument-specific datasets further improves performance by capturing characteristic rhythmic and melodic patterns. This work contributes a robust and flexible framework for beat-based MIDI quantization using transformer models.
Comprehensive Description of Uncertainty in Measurement for Representation and Propagation with Scalable Precision
Mar 20, 2026Probability theory has become the predominant framework for quantifying uncertainty across scientific and engineering disciplines, with a particular focus on measurement and control systems. However, the widespread reliance on simple Gaussian assumptions--particularly in control theory, manufacturing, and measurement systems--can result in incomplete representations and multistage lossy approximations of complex phenomena, including inaccurate propagation of uncertainty through multi stage processes. This work proposes a comprehensive yet computationally tractable framework for representing and propagating quantitative attributes arising in measurement systems using Probability Density Functions (PDFs). Recognizing the constraints imposed by finite memory in software systems, we advocate for the use of Gaussian Mixture Models (GMMs), a principled extension of the familiar Gaussian framework, as they are universal approximators of PDFs whose complexity can be tuned to trade off approximation accuracy against memory and computation. From both mathematical and computational perspectives, GMMs enable high performance and, in many cases, closed form solutions of essential operations in control and measurement. The paper presents practical applications within manufacturing and measurement contexts especially circular factory, demonstrating how the GMMs framework supports accurate representation and propagation of measurement uncertainty and offers improved accuracy--compared to the traditional Gaussian framework--while keeping the computations tractable.
Exploring Procedural Data Generation for Automatic Acoustic Guitar Fingerpicking Transcription
Aug 11, 2025Automatic transcription of acoustic guitar fingerpicking performances remains a challenging task due to the scarcity of labeled training data and legal constraints connected with musical recordings. This work investigates a procedural data generation pipeline as an alternative to real audio recordings for training transcription models. Our approach synthesizes training data through four stages: knowledge-based fingerpicking tablature composition, MIDI performance rendering, physical modeling using an extended Karplus-Strong algorithm, and audio augmentation including reverb and distortion. We train and evaluate a CRNN-based note-tracking model on both real and synthetic datasets, demonstrating that procedural data can be used to achieve reasonable note-tracking results. Finetuning with a small amount of real data further enhances transcription accuracy, improving over models trained exclusively on real recordings. These results highlight the potential of procedurally generated audio for data-scarce music information retrieval tasks.
Joint Transcription of Acoustic Guitar Strumming Directions and Chords
Aug 11, 2025Automatic transcription of guitar strumming is an underrepresented and challenging task in Music Information Retrieval (MIR), particularly for extracting both strumming directions and chord progressions from audio signals. While existing methods show promise, their effectiveness is often hindered by limited datasets. In this work, we extend a multimodal approach to guitar strumming transcription by introducing a novel dataset and a deep learning-based transcription model. We collect 90 min of real-world guitar recordings using an ESP32 smartwatch motion sensor and a structured recording protocol, complemented by a synthetic dataset of 4h of labeled strumming audio. A Convolutional Recurrent Neural Network (CRNN) model is trained to detect strumming events, classify their direction, and identify the corresponding chords using only microphone audio. Our evaluation demonstrates significant improvements over baseline onset detection algorithms, with a hybrid method combining synthetic and real-world data achieving the highest accuracy for both strumming action detection and chord classification. These results highlight the potential of deep learning for robust guitar strumming transcription and open new avenues for automatic rhythm guitar analysis.
Fretting-Transformer: Encoder-Decoder Model for MIDI to Tablature Transcription
Jun 17, 2025

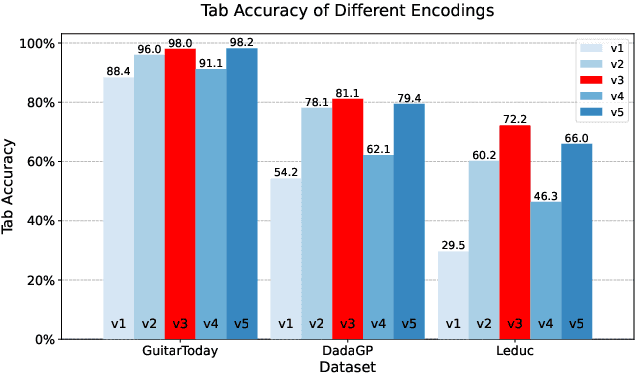

Music transcription plays a pivotal role in Music Information Retrieval (MIR), particularly for stringed instruments like the guitar, where symbolic music notations such as MIDI lack crucial playability information. This contribution introduces the Fretting-Transformer, an encoderdecoder model that utilizes a T5 transformer architecture to automate the transcription of MIDI sequences into guitar tablature. By framing the task as a symbolic translation problem, the model addresses key challenges, including string-fret ambiguity and physical playability. The proposed system leverages diverse datasets, including DadaGP, GuitarToday, and Leduc, with novel data pre-processing and tokenization strategies. We have developed metrics for tablature accuracy and playability to quantitatively evaluate the performance. The experimental results demonstrate that the Fretting-Transformer surpasses baseline methods like A* and commercial applications like Guitar Pro. The integration of context-sensitive processing and tuning/capo conditioning further enhances the model's performance, laying a robust foundation for future developments in automated guitar transcription.
6D Pose Estimation on Point Cloud Data through Prior Knowledge Integration: A Case Study in Autonomous Disassembly
May 30, 2025The accurate estimation of 6D pose remains a challenging task within the computer vision domain, even when utilizing 3D point cloud data. Conversely, in the manufacturing domain, instances arise where leveraging prior knowledge can yield advancements in this endeavor. This study focuses on the disassembly of starter motors to augment the engineering of product life cycles. A pivotal objective in this context involves the identification and 6D pose estimation of bolts affixed to the motors, facilitating automated disassembly within the manufacturing workflow. Complicating matters, the presence of occlusions and the limitations of single-view data acquisition, notably when motors are placed in a clamping system, obscure certain portions and render some bolts imperceptible. Consequently, the development of a comprehensive pipeline capable of acquiring complete bolt information is imperative to avoid oversight in bolt detection. In this paper, employing the task of bolt detection within the scope of our project as a pertinent use case, we introduce a meticulously devised pipeline. This multi-stage pipeline effectively captures the 6D information with regard to all bolts on the motor, thereby showcasing the effective utilization of prior knowledge in handling this challenging task. The proposed methodology not only contributes to the field of 6D pose estimation but also underscores the viability of integrating domain-specific insights to tackle complex problems in manufacturing and automation.
Randomized 3D Scene Generation for Generalizable Self-supervised Pre-training
Jun 07, 2023Capturing and labeling real-world 3D data is laborious and time-consuming, which makes it costly to train strong 3D models. To address this issue, previous works generate randomized 3D scenes and pre-train models on generated data. Although the pre-trained models gain promising performance boosts, previous works have two major shortcomings. First, they focus on only one downstream task (i.e., object detection). Second, a fair comparison of generated data is still lacking. In this work, we systematically compare data generation methods using a unified setup. To clarify the generalization of the pre-trained models, we evaluate their performance in multiple tasks (e.g., object detection and semantic segmentation) and with different pre-training methods (e.g., masked autoencoder and contrastive learning). Moreover, we propose a new method to generate 3D scenes with spherical harmonics. It surpasses the previous formula-driven method with a clear margin and achieves on-par results with methods using real-world scans and CAD models.
Tinto: Multisensor Benchmark for 3D Hyperspectral Point Cloud Segmentation in the Geosciences
May 17, 2023



The increasing use of deep learning techniques has reduced interpretation time and, ideally, reduced interpreter bias by automatically deriving geological maps from digital outcrop models. However, accurate validation of these automated mapping approaches is a significant challenge due to the subjective nature of geological mapping and the difficulty in collecting quantitative validation data. Additionally, many state-of-the-art deep learning methods are limited to 2D image data, which is insufficient for 3D digital outcrops, such as hyperclouds. To address these challenges, we present Tinto, a multi-sensor benchmark digital outcrop dataset designed to facilitate the development and validation of deep learning approaches for geological mapping, especially for non-structured 3D data like point clouds. Tinto comprises two complementary sets: 1) a real digital outcrop model from Corta Atalaya (Spain), with spectral attributes and ground-truth data, and 2) a synthetic twin that uses latent features in the original datasets to reconstruct realistic spectral data (including sensor noise and processing artifacts) from the ground-truth. The point cloud is dense and contains 3,242,964 labeled points. We used these datasets to explore the abilities of different deep learning approaches for automated geological mapping. By making Tinto publicly available, we hope to foster the development and adaptation of new deep learning tools for 3D applications in Earth sciences. The dataset can be accessed through this link: https://doi.org/10.14278/rodare.2256.
Applying Plain Transformers to Real-World Point Clouds
Mar 04, 2023Due to the lack of inductive bias, transformer-based models usually require a large amount of training data. The problem is especially concerning in 3D vision, as 3D data are harder to acquire and annotate. To overcome this problem, previous works modify the architecture of transformers to incorporate inductive biases by applying, e.g., local attention and down-sampling. Although they have achieved promising results, earlier works on transformers for point clouds have two issues. First, the power of plain transformers is still under-explored. Second, they focus on simple and small point clouds instead of complex real-world ones. This work revisits the plain transformers in real-world point cloud understanding. We first take a closer look at some fundamental components of plain transformers, e.g., patchifier and positional embedding, for both efficiency and performance. To close the performance gap due to the lack of inductive bias and annotated data, we investigate self-supervised pre-training with masked autoencoder (MAE). Specifically, we propose drop patch, which prevents information leakage and significantly improves the effectiveness of MAE. Our models achieve SOTA results in semantic segmentation on the S3DIS dataset and object detection on the ScanNet dataset with lower computational costs. Our work provides a new baseline for future research on transformers for point clouds.
MotorFactory: A Blender Add-on for Large Dataset Generation of Small Electric Motors
Jan 11, 2023



To enable automatic disassembly of different product types with uncertain conditions and degrees of wear in remanufacturing, agile production systems that can adapt dynamically to changing requirements are needed. Machine learning algorithms can be employed due to their generalization capabilities of learning from various types and variants of products. However, in reality, datasets with a diversity of samples that can be used to train models are difficult to obtain in the initial period. This may cause bad performances when the system tries to adapt to new unseen input data in the future. In order to generate large datasets for different learning purposes, in our project, we present a Blender add-on named MotorFactory to generate customized mesh models of various motor instances. MotorFactory allows to create mesh models which, complemented with additional add-ons, can be further used to create synthetic RGB images, depth images, normal images, segmentation ground truth masks, and 3D point cloud datasets with point-wise semantic labels. The created synthetic datasets may be used for various tasks including motor type classification, object detection for decentralized material transfer tasks, part segmentation for disassembly and handling tasks, or even reinforcement learning-based robotics control or view-planning.