 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Flow Matching for Sparse-View CT Reconstruction
Feb 27, 2026Generative models, particularly Diffusion Models (DM), have shown strong potential for Computed Tomography (CT) reconstruction serving as expressive priors for solving ill-posed inverse problems. However, diffusion-based reconstruction relies on Stochastic Differential Equations (SDEs) for forward diffusion and reverse denoising, where such stochasticity can interfere with repeated data consistency corrections in CT reconstruction. Since CT reconstruction is often time-critical in clinical and interventional scenarios, improving reconstruction efficiency is essential. In contrast, Flow Matching (FM) models sampling as a deterministic Ordinary Differential Equation (ODE), yielding smooth trajectories without stochastic noise injection. This deterministic formulation is naturally compatible with repeated data consistency operations. Furthermore, we observe that FM-predicted velocity fields exhibit strong correlations across adjacent steps. Motivated by this, we propose an FM-based CT reconstruction framework (FMCT) and an efficient variant (EFMCT) that reuses previously predicted velocity fields over consecutive steps to substantially reduce the number of Neural network Function Evaluations (NFEs), thereby improving inference efficiency. We provide theoretical analysis showing that the error introduced by velocity reuse is bounded when combined with data consistency operations. Extensive experiments demonstrate that FMCT/EFMCT achieve competitive reconstruction quality while significantly improving computational efficiency compared with diffusion-based methods. The codebase is open-sourced at https://github.com/EFMCT/EFMCT.
Fronthaul-Efficient Distributed Cooperative 3D Positioning with Quantized Latent CSI Embeddings
Jan 31, 2026High-precision three-dimensional (3D) positioning in dense urban non-line-of-sight (NLOS) environments benefits significantly from cooperation among multiple distributed base stations (BSs). However, forwarding raw CSI from multiple BSs to a central unit (CU) incurs prohibitive fronthaul overhead, which limits scalable cooperative positioning in practice. This paper proposes a learning-based edge-cloud cooperative positioning framework under limited-capacity fronthaul constraints. In the proposed architecture, a neural network is deployed at each BS to compress the locally estimated CSI into a quantized representation subject to a fixed fronthaul payload. The quantized CSI is transmitted to the CU, which performs cooperative 3D positioning by jointly processing the compressed CSI received from multiple BSs. The proposed framework adopts a two-stage training strategy consisting of self-supervised local training at the BSs and end-to-end joint training for positioning at the CU. Simulation results based on a 3.5~GHz 5G NR compliant urban ray-tracing scenario with six BSs and 20~MHz bandwidth show that the proposed method achieves a mean 3D positioning error of 0.48~m and a 90th-percentile error of 0.83~m, while reducing the fronthaul payload to 6.25% of lossless CSI forwarding. The achieved performance is close to that of cooperative positioning with full CSI exchange.
CMANet: Channel-Masked Attention Network for Cooperative Multi-Base-Station 3D Positioning
Jan 31, 2026Achieving ubiquitous high-accuracy localization is crucial for next-generation wireless systems, yet remains challenging in multipath-rich urban environments. By exploiting the fine-grained multipath characteristics embedded in channel state information (CSI), more reliable and precise localization can be achieved. To address this, we present CMANet, a multi-BS cooperative positioning architecture that performs feature-level fusion of raw CSI using the proposed Channel Masked Attention (CMA) mechanism. The CMA encoder injects a physically grounded prior--per-BS channel gain--into the attention weights, thus emphasizing reliable links and suppressing spurious multipath. A lightweight LSTM decoder then treats subcarriers as a sequence to accumulate frequency-domain evidence into a final 3D position estimate. In a typical 5G NR-compliant urban simulation, CMANet achieves less than 0.5m median error and 1.0m 90th-percentile error, outperforming state-of-the-art benchmarks. Ablations verify the necessity of CMA and frequency accumulation. CMANet is edge-deployable and exemplifies an Integrated Sensing and Communication (ISAC)-aligned, cooperative paradigm for multi-BS CSI positioning.
Diffusion Models for Tabular Data: Challenges, Current Progress, and Future Directions
Feb 24, 2025In recent years, generative models have achieved remarkable performance across diverse applications, including image generation, text synthesis, audio creation, video generation, and data augmentation. Diffusion models have emerged as superior alternatives to Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs) by addressing their limitations, such as training instability, mode collapse, and poor representation of multimodal distributions. This success has spurred widespread research interest. In the domain of tabular data, diffusion models have begun to showcase similar advantages over GANs and VAEs, achieving significant performance breakthroughs and demonstrating their potential for addressing unique challenges in tabular data modeling. However, while domains like images and time series have numerous surveys summarizing advancements in diffusion models, there remains a notable gap in the literature for tabular data. Despite the increasing interest in diffusion models for tabular data, there has been little effort to systematically review and summarize these developments. This lack of a dedicated survey limits a clear understanding of the challenges, progress, and future directions in this critical area. This survey addresses this gap by providing a comprehensive review of diffusion models for tabular data. Covering works from June 2015, when diffusion models emerged, to December 2024, we analyze nearly all relevant studies, with updates maintained in a \href{https://github.com/Diffusion-Model-Leiden/awesome-diffusion-models-for-tabular-data}{GitHub repository}. Assuming readers possess foundational knowledge of statistics and diffusion models, we employ mathematical formulations to deliver a rigorous and detailed review, aiming to promote developments in this emerging and exciting area.
Results of the Big ANN: NeurIPS'23 competition
Sep 25, 2024


The 2023 Big ANN Challenge, held at NeurIPS 2023, focused on advancing the state-of-the-art in indexing data structures and search algorithms for practical variants of Approximate Nearest Neighbor (ANN) search that reflect the growing complexity and diversity of workloads. Unlike prior challenges that emphasized scaling up classical ANN search ~\cite{DBLP:conf/nips/SimhadriWADBBCH21}, this competition addressed filtered search, out-of-distribution data, sparse and streaming variants of ANNS. Participants developed and submitted innovative solutions that were evaluated on new standard datasets with constrained computational resources. The results showcased significant improvements in search accuracy and efficiency over industry-standard baselines, with notable contributions from both academic and industrial teams. This paper summarizes the competition tracks, datasets, evaluation metrics, and the innovative approaches of the top-performing submissions, providing insights into the current advancements and future directions in the field of approximate nearest neighbor search.
SR4ZCT: Self-supervised Through-plane Resolution Enhancement for CT Images with Arbitrary Resolution and Overlap
May 03, 2024Computed tomography (CT) is a widely used non-invasive medical imaging technique for disease diagnosis. The diagnostic accuracy is often affected by image resolution, which can be insufficient in practice. For medical CT images, the through-plane resolution is often worse than the in-plane resolution and there can be overlap between slices, causing difficulties in diagnoses. Self-supervised methods for through-plane resolution enhancement, which train on in-plane images and infer on through-plane images, have shown promise for both CT and MRI imaging. However, existing self-supervised methods either neglect overlap or can only handle specific cases with fixed combinations of resolution and overlap. To address these limitations, we propose a self-supervised method called SR4ZCT. It employs the same off-axis training approach while being capable of handling arbitrary combinations of resolution and overlap. Our method explicitly models the relationship between resolutions and voxel spacings of different planes to accurately simulate training images that match the original through-plane images. We highlight the significance of accurate modeling in self-supervised off-axis training and demonstrate the effectiveness of SR4ZCT using a real-world dataset.
Implicit Neural Representations for Robust Joint Sparse-View CT Reconstruction
May 03, 2024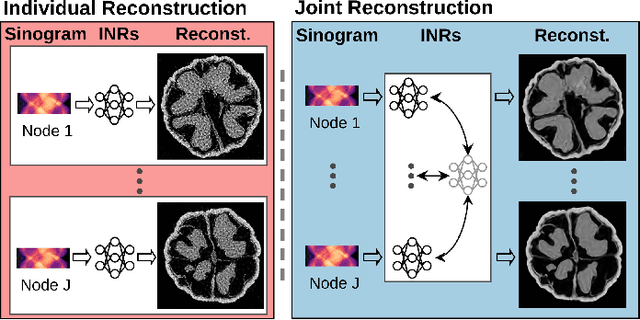
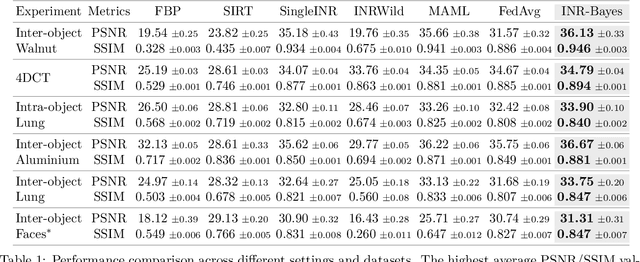
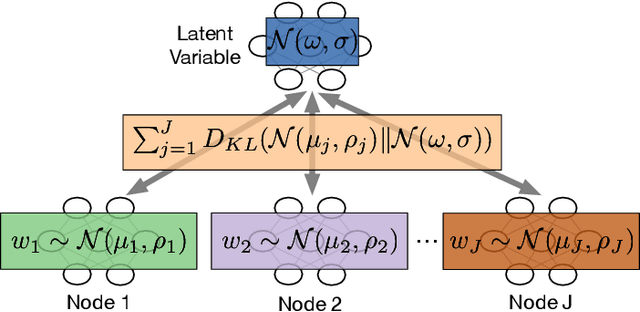
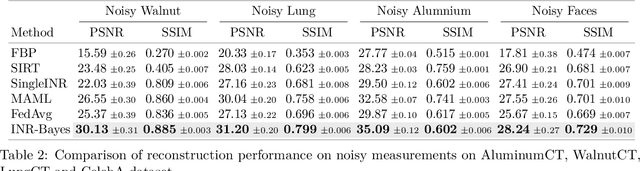
Computed Tomography (CT) is pivotal in industrial quality control and medical diagnostics. Sparse-view CT, offering reduced ionizing radiation, faces challenges due to its under-sampled nature, leading to ill-posed reconstruction problems. Recent advancements in Implicit Neural Representations (INRs) have shown promise in addressing sparse-view CT reconstruction. Recognizing that CT often involves scanning similar subjects, we propose a novel approach to improve reconstruction quality through joint reconstruction of multiple objects using INRs. This approach can potentially leverage both the strengths of INRs and the statistical regularities across multiple objects. While current INR joint reconstruction techniques primarily focus on accelerating convergence via meta-initialization, they are not specifically tailored to enhance reconstruction quality. To address this gap, we introduce a novel INR-based Bayesian framework integrating latent variables to capture the inter-object relationships. These variables serve as a dynamic reference throughout the optimization, thereby enhancing individual reconstruction fidelity. Our extensive experiments, which assess various key factors such as reconstruction quality, resistance to overfitting, and generalizability, demonstrate significant improvements over baselines in common numerical metrics. This underscores a notable advancement in CT reconstruction methods.
Multi-stage Deep Learning Artifact Reduction for Computed Tomography
Sep 01, 2023



In Computed Tomography (CT), an image of the interior structure of an object is computed from a set of acquired projection images. The quality of these reconstructed images is essential for accurate analysis, but this quality can be degraded by a variety of imaging artifacts. To improve reconstruction quality, the acquired projection images are often processed by a pipeline consisting of multiple artifact-removal steps applied in various image domains (e.g., outlier removal on projection images and denoising of reconstruction images). These artifact-removal methods exploit the fact that certain artifacts are easier to remove in a certain domain compared with other domains. Recently, deep learning methods have shown promising results for artifact removal for CT images. However, most existing deep learning methods for CT are applied as a post-processing method after reconstruction. Therefore, artifacts that are relatively difficult to remove in the reconstruction domain may not be effectively removed by these methods. As an alternative, we propose a multi-stage deep learning method for artifact removal, in which neural networks are applied to several domains, similar to a classical CT processing pipeline. We show that the neural networks can be effectively trained in succession, resulting in easy-to-use and computationally efficient training. Experiments on both simulated and real-world experimental datasets show that our method is effective in reducing artifacts and superior to deep learning-based post-processing.
Graph Neural Network based Log Anomaly Detection and Explanation
Jul 02, 2023



Event logs are widely used to record the status of high-tech systems, making log anomaly detection important for monitoring those systems. Most existing log anomaly detection methods take a log event count matrix or log event sequences as input, exploiting quantitative and/or sequential relationships between log events to detect anomalies. Unfortunately, only considering quantitative or sequential relationships may result in many false positives and/or false negatives. To alleviate this problem, we propose a graph-based method for unsupervised log anomaly detection, dubbed Logs2Graphs, which first converts event logs into attributed, directed, and weighted graphs, and then leverages graph neural networks to perform graph-level anomaly detection. Specifically, we introduce One-Class Digraph Inception Convolutional Networks, abbreviated as OCDiGCN, a novel graph neural network model for detecting graph-level anomalies in a collection of attributed, directed, and weighted graphs. By coupling the graph representation and anomaly detection steps, OCDiGCN can learn a representation that is especially suited for anomaly detection, resulting in a high detection accuracy. Importantly, for each identified anomaly, we additionally provide a small subset of nodes that play a crucial role in OCDiGCN's prediction as explanations, which can offer valuable cues for subsequent root cause diagnosis. Experiments on five benchmark datasets show that Logs2Graphs performs at least on par state-of-the-art log anomaly detection methods on simple datasets while largely outperforming state-of-the-art log anomaly detection methods on complicated datasets.
Spectral Reconstruction and Disparity from Spatio-Spectrally Coded Light Fields via Multi-Task Deep Learning
Mar 18, 2021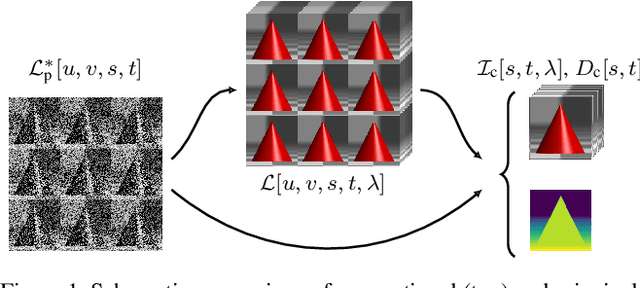
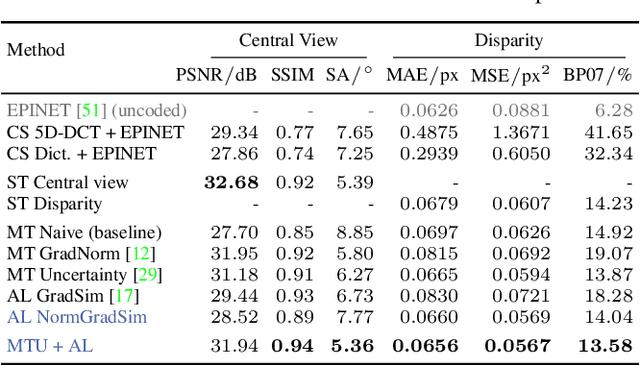
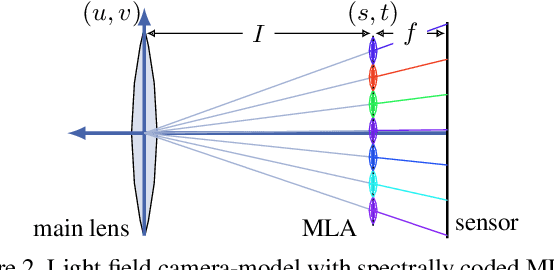
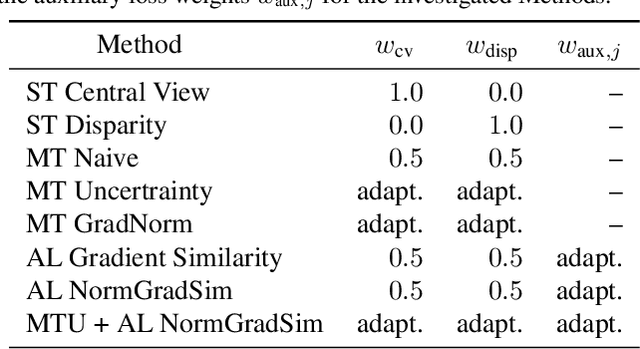
We present a novel method to reconstruct a spectral central view and its aligned disparity map from spatio-spectrally coded light fields. Since we do not reconstruct an intermediate full light field from the coded measurement, we refer to this as principal reconstruction. The coded light fields correspond to those captured by a light field camera in the unfocused design with a spectrally coded microlens array. In this application, the spectrally coded light field camera can be interpreted as a single-shot spectral depth camera. We investigate several multi-task deep learning methods and propose a new auxiliary loss-based training strategy to enhance the reconstruction performance. The results are evaluated using a synthetic as well as a new real-world spectral light field dataset that we captured using a custom-built camera. The results are compared to state-of-the art compressed sensing reconstruction and disparity estimation. We achieve a high reconstruction quality for both synthetic and real-world coded light fields. The disparity estimation quality is on par with or even outperforms state-of-the-art disparity estimation from uncoded RGB light fields.