 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-Effective, Low Latency Vector Search with Azure Cosmos DB
May 09, 2025Vector indexing enables semantic search over diverse corpora and has become an important interface to databases for both users and AI agents. Efficient vector search requires deep optimizations in database systems. This has motivated a new class of specialized vector databases that optimize for vector search quality and cost. Instead, we argue that a scalable, high-performance, and cost-efficient vector search system can be built inside a cloud-native operational database like Azure Cosmos DB while leveraging the benefits of a distributed database such as high availability, durability, and scale. We do this by deeply integrating DiskANN, a state-of-the-art vector indexing library, inside Azure Cosmos DB NoSQL. This system uses a single vector index per partition stored in existing index trees, and kept in sync with underlying data. It supports < 20ms query latency over an index spanning 10 million of vectors, has stable recall over updates, and offers nearly 15x and 41x lower query cost compared to Zilliz and Pinecone serverless enterprise products. It also scales out to billions of vectors via automatic partitioning. This convergent design presents a point in favor of integrating vector indices into operational databases in the context of recent debates on specialized vector databases, and offers a template for vector indexing in other databases.
In-Place Updates of a Graph Index for Streaming Approximate Nearest Neighbor Search
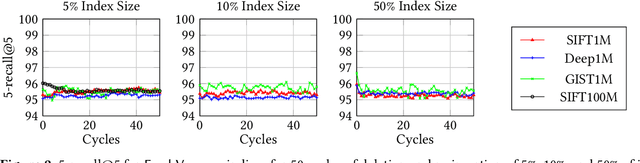
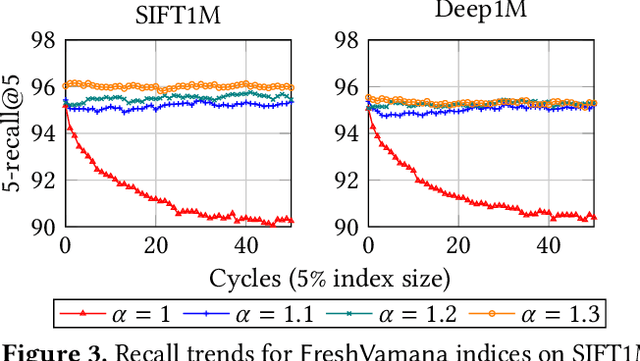
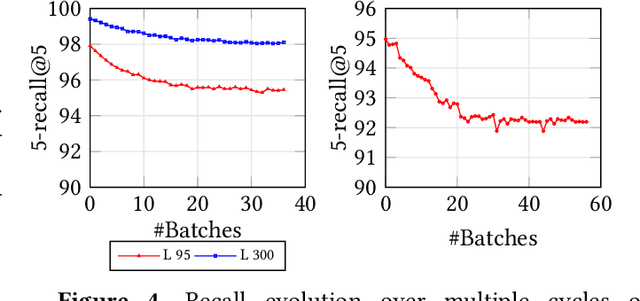
Feb 19, 2025Indices for approximate nearest neighbor search (ANNS) are a basic component for information retrieval and widely used in database, search, recommendation and RAG systems. In these scenarios, documents or other objects are inserted into and deleted from the working set at a high rate, requiring a stream of updates to the vector index. Algorithms based on proximity graph indices are the most efficient indices for ANNS, winning many benchmark competitions. However, it is challenging to update such graph index at a high rate, while supporting stable recall after many updates. Since the graph is singly-linked, deletions are hard because there is no fast way to find in-neighbors of a deleted vertex. Therefore, to update the graph, state-of-the-art algorithms such as FreshDiskANN accumulate deletions in a batch and periodically consolidate, removing edges to deleted vertices and modifying the graph to ensure recall stability. In this paper, we present IP-DiskANN (InPlaceUpdate-DiskANN), the first algorithm to avoid batch consolidation by efficiently processing each insertion and deletion in-place. Our experiments using standard benchmarks show that IP-DiskANN has stable recall over various lengthy update patterns in both high-recall and low-recall regimes. Further, its query throughput and update speed are better than using the batch consolidation algorithm and HNSW.
Results of the Big ANN: NeurIPS'23 competition
Sep 25, 2024

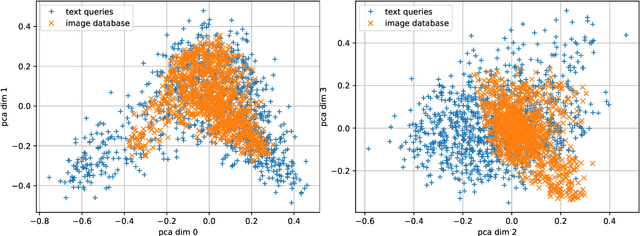

The 2023 Big ANN Challenge, held at NeurIPS 2023, focused on advancing the state-of-the-art in indexing data structures and search algorithms for practical variants of Approximate Nearest Neighbor (ANN) search that reflect the growing complexity and diversity of workloads. Unlike prior challenges that emphasized scaling up classical ANN search ~\cite{DBLP:conf/nips/SimhadriWADBBCH21}, this competition addressed filtered search, out-of-distribution data, sparse and streaming variants of ANNS. Participants developed and submitted innovative solutions that were evaluated on new standard datasets with constrained computational resources. The results showcased significant improvements in search accuracy and efficiency over industry-standard baselines, with notable contributions from both academic and industrial teams. This paper summarizes the competition tracks, datasets, evaluation metrics, and the innovative approaches of the top-performing submissions, providing insights into the current advancements and future directions in the field of approximate nearest neighbor search.
MS MARCO Web Search: a Large-scale Information-rich Web Dataset with Millions of Real Click Labels
May 13, 2024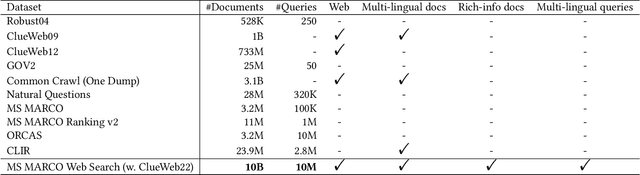
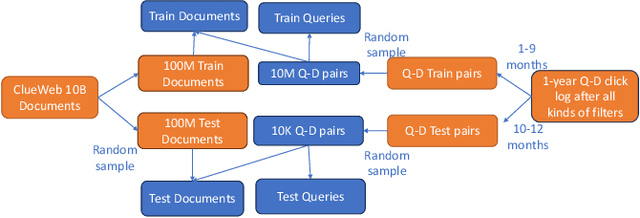
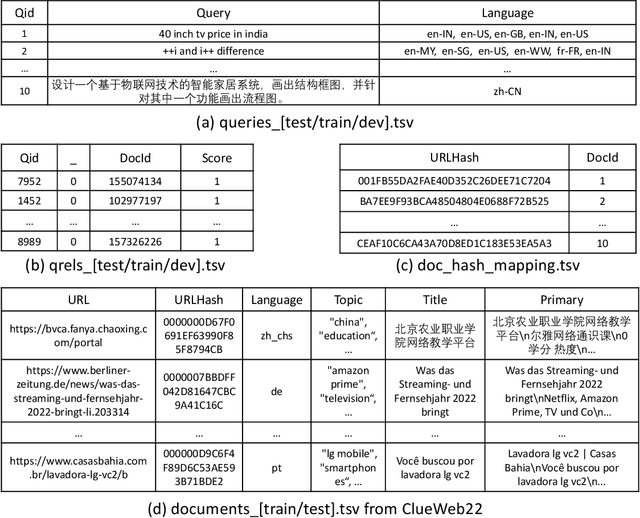
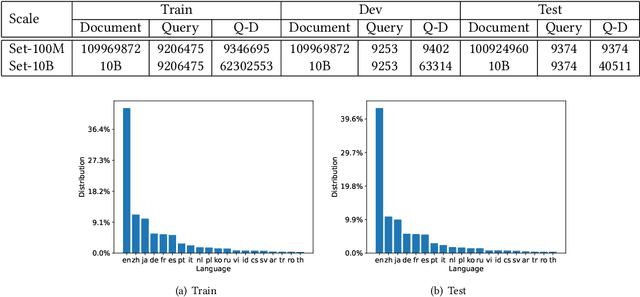
Recent breakthroughs in large models have highlighted the critical significance of data scale, labels and modals. In this paper, we introduce MS MARCO Web Search, the first large-scale information-rich web dataset, featuring millions of real clicked query-document labels. This dataset closely mimics real-world web document and query distribution, provides rich information for various kinds of downstream tasks and encourages research in various areas, such as generic end-to-end neural indexer models, generic embedding models, and next generation information access system with large language models. MS MARCO Web Search offers a retrieval benchmark with three web retrieval challenge tasks that demand innovations in both machine learning and information retrieval system research domains. As the first dataset that meets large, real and rich data requirements, MS MARCO Web Search paves the way for future advancements in AI and system research. MS MARCO Web Search dataset is available at: https://github.com/microsoft/MS-MARCO-Web-Search.
Scaling Graph-Based ANNS Algorithms to Billion-Size Datasets: A Comparative Analysis
May 07, 2023



Algorithms for approximate nearest-neighbor search (ANNS) have been the topic of significant recent interest in the research community. However, evaluations of such algorithms are usually restricted to a small number of datasets with millions or tens of millions of points, whereas real-world applications require algorithms that work on the scale of billions of points. Furthermore, existing evaluations of ANNS algorithms are typically heavily focused on measuring and optimizing for queries-per second (QPS) at a given accuracy, which can be hardware-dependent and ignores important metrics such as build time. In this paper, we propose a set of principled measures for evaluating ANNS algorithms which refocuses on their scalability to billion-size datasets. These measures include ability to be efficiently parallelized, build times, and scaling relationships as dataset size increases. We also expand on the QPS measure with machine-agnostic measures such as the number of distance computations per query, and we evaluate ANNS data structures on their accuracy in more demanding settings required in modern applications, such as evaluating range queries and running on out-of-distribution data. We optimize four graph-based algorithms for the billion-scale setting, and in the process provide a general framework for making many incremental ANNS graph algorithms lock-free. We use our framework to evaluate the aforementioned graph-based ANNS algorithms as well as two alternative approaches.
Results of the NeurIPS'21 Challenge on Billion-Scale Approximate Nearest Neighbor Search
May 08, 2022
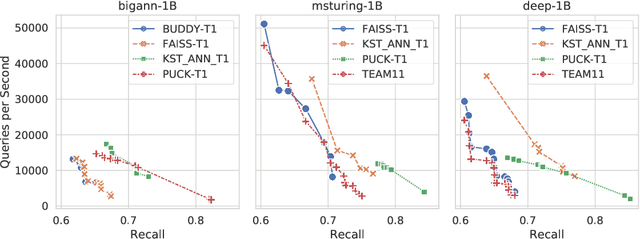
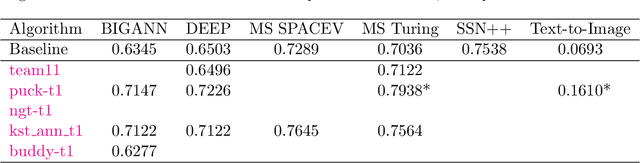
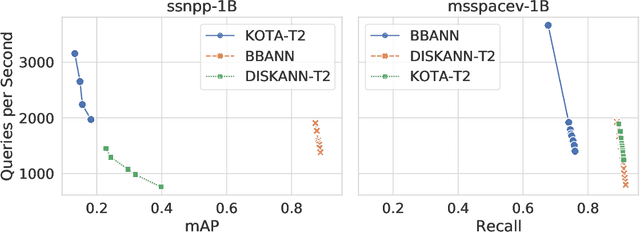
Despite the broad range of algorithms for Approximate Nearest Neighbor Search, most empirical evaluations of algorithms have focused on smaller datasets, typically of 1 million points~\citep{Benchmark}. However, deploying recent advances in embedding based techniques for search, recommendation and ranking at scale require ANNS indices at billion, trillion or larger scale. Barring a few recent papers, there is limited consensus on which algorithms are effective at this scale vis-\`a-vis their hardware cost. This competition compares ANNS algorithms at billion-scale by hardware cost, accuracy and performance. We set up an open source evaluation framework and leaderboards for both standardized and specialized hardware. The competition involves three tracks. The standard hardware track T1 evaluates algorithms on an Azure VM with limited DRAM, often the bottleneck in serving billion-scale indices, where the embedding data can be hundreds of GigaBytes in size. It uses FAISS~\citep{Faiss17} as the baseline. The standard hardware track T2 additional allows inexpensive SSDs in addition to the limited DRAM and uses DiskANN~\citep{DiskANN19} as the baseline. The specialized hardware track T3 allows any hardware configuration, and again uses FAISS as the baseline. We compiled six diverse billion-scale datasets, four newly released for this competition, that span a variety of modalities, data types, dimensions, deep learning models, distance functions and sources. The outcome of the competition was ranked leaderboards of algorithms in each track based on recall at a query throughput threshold. Additionally, for track T3, separate leaderboards were created based on recall as well as cost-normalized and power-normalized query throughput.
FreshDiskANN: A Fast and Accurate Graph-Based ANN Index for Streaming Similarity Search
May 20, 2021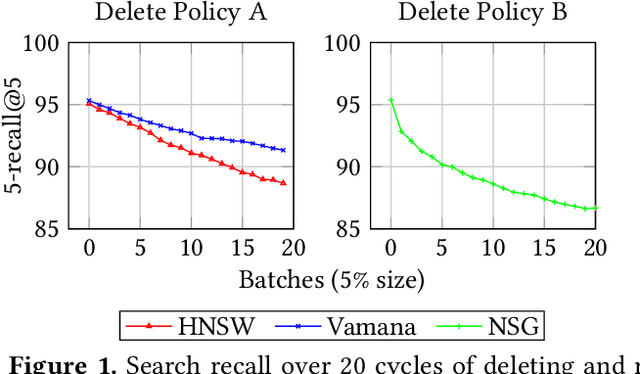
Approximate nearest neighbor search (ANNS) is a fundamental building block in information retrieval with graph-based indices being the current state-of-the-art and widely used in the industry. Recent advances in graph-based indices have made it possible to index and search billion-point datasets with high recall and millisecond-level latency on a single commodity machine with an SSD. However, existing graph algorithms for ANNS support only static indices that cannot reflect real-time changes to the corpus required by many key real-world scenarios (e.g. index of sentences in documents, email, or a news index). To overcome this drawback, the current industry practice for manifesting updates into such indices is to periodically re-build these indices, which can be prohibitively expensive. In this paper, we present the first graph-based ANNS index that reflects corpus updates into the index in real-time without compromising on search performance. Using update rules for this index, we design FreshDiskANN, a system that can index over a billion points on a workstation with an SSD and limited memory, and support thousands of concurrent real-time inserts, deletes and searches per second each, while retaining $>95\%$ 5-recall@5. This represents a 5-10x reduction in the cost of maintaining freshness in indices when compared to existing methods.
DROCC: Deep Robust One-Class Classification
Feb 28, 2020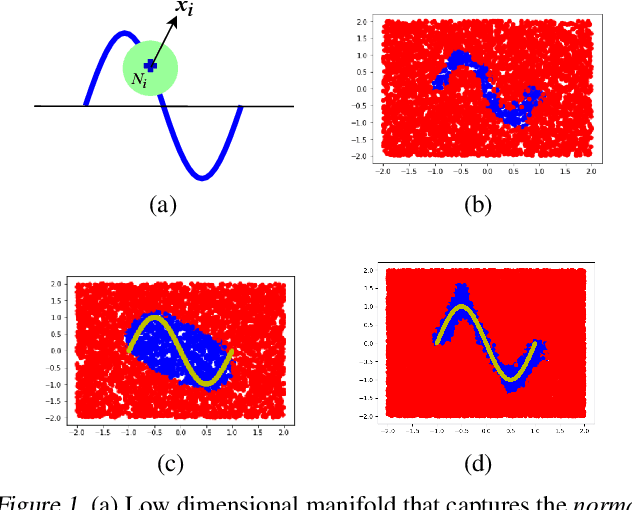
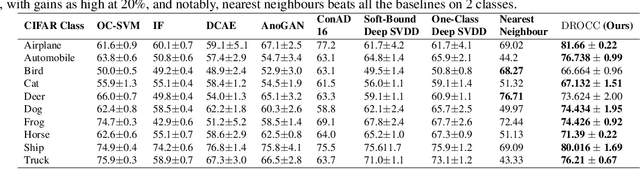
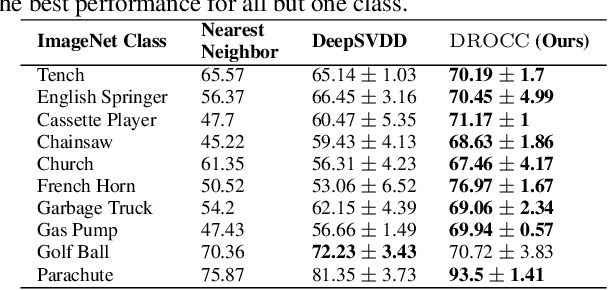
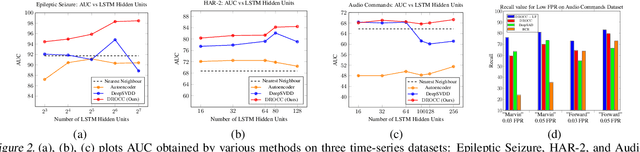
Classical approaches for one-class problems such as one-class SVM (Scholkopf et al., 1999) and isolation forest (Liu et al., 2008) require careful feature engineering when applied to structured domains like images. To alleviate this concern, state-of-the-art methods like DeepSVDD (Ruff et al., 2018) consider the natural alternative of minimizing a classical one-class loss applied to the learned final layer representations. However, such an approach suffers from the fundamental drawback that a representation that simply collapses all the inputs minimizes the one class loss; heuristics to mitigate collapsed representations provide limited benefits. In this work, we propose Deep Robust One Class Classification (DROCC) method that is robust to such a collapse by training the network to distinguish the training points from their perturbations, generated adversarially. DROCC is motivated by the assumption that the interesting class lies on a locally linear low dimensional manifold. Empirical evaluation demonstrates DROCC's effectiveness on two different one-class problem settings and on a range of real-world datasets across different domains - images(CIFAR and ImageNet), audio and timeseries, offering up to 20% increase in accuracy over the state-of-the-art in anomaly detection.
RNNPool: Efficient Non-linear Pooling for RAM Constrained Inference
Feb 27, 2020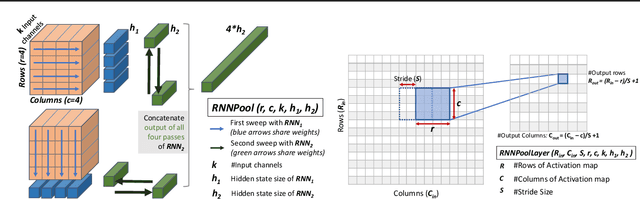
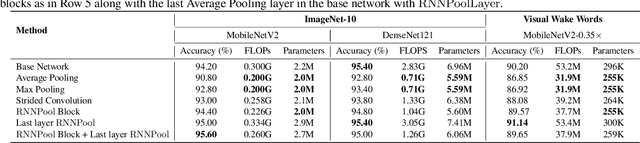
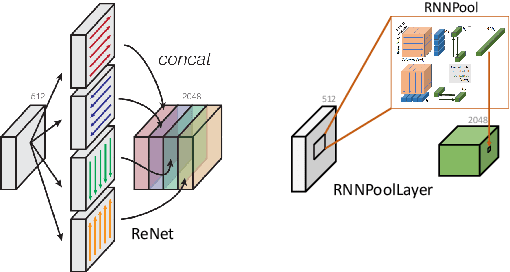
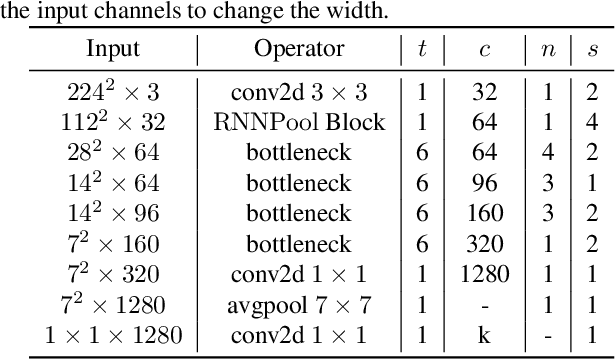
Pooling operators are key components in most Convolutional Neural Networks (CNNs) as they serve to downsample images, aggregate feature information, and increase receptive field. However, standard pooling operators reduce the feature size gradually to avoid significant loss in information via gross aggregation. Consequently, CNN architectures tend to be deep, computationally expensive and challenging to deploy on RAM constrained devices. We introduce RNNPool, a novel pooling operator based on Recurrent Neural Networks (RNNs), that efficiently aggregate features over large patches of an image and rapidly downsamples its size. Our empirical evaluation indicates that an RNNPool layer(s) can effectively replace multiple blocks in a variety of architectures such as MobileNets (Sandler et al., 2018), DenseNet (Huang et al., 2017) and can be used for several vision tasks like image classification and face detection. That is, RNNPool can significantly decrease computational complexity and peak RAM usage for inference, while retaining comparable accuracy. Further, we use RNNPool to construct a novel real-time face detection method that achieves state-of-the-art MAP within computational budget afforded by a tiny Cortex M4 microcontroller with ~256 KB RAM.