 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResults of the Big ANN: NeurIPS'23 competition
Sep 25, 2024


The 2023 Big ANN Challenge, held at NeurIPS 2023, focused on advancing the state-of-the-art in indexing data structures and search algorithms for practical variants of Approximate Nearest Neighbor (ANN) search that reflect the growing complexity and diversity of workloads. Unlike prior challenges that emphasized scaling up classical ANN search ~\cite{DBLP:conf/nips/SimhadriWADBBCH21}, this competition addressed filtered search, out-of-distribution data, sparse and streaming variants of ANNS. Participants developed and submitted innovative solutions that were evaluated on new standard datasets with constrained computational resources. The results showcased significant improvements in search accuracy and efficiency over industry-standard baselines, with notable contributions from both academic and industrial teams. This paper summarizes the competition tracks, datasets, evaluation metrics, and the innovative approaches of the top-performing submissions, providing insights into the current advancements and future directions in the field of approximate nearest neighbor search.
Bridging Dense and Sparse Maximum Inner Product Search
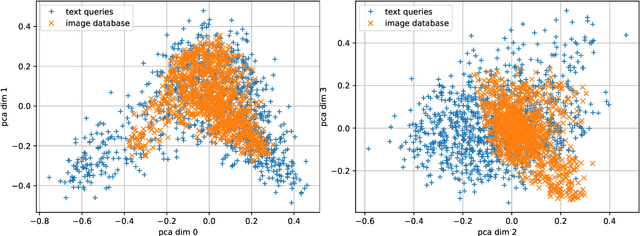
Sep 16, 2023Maximum inner product search (MIPS) over dense and sparse vectors have progressed independently in a bifurcated literature for decades; the latter is better known as top-$k$ retrieval in Information Retrieval. This duality exists because sparse and dense vectors serve different end goals. That is despite the fact that they are manifestations of the same mathematical problem. In this work, we ask if algorithms for dense vectors could be applied effectively to sparse vectors, particularly those that violate the assumptions underlying top-$k$ retrieval methods. We study IVF-based retrieval where vectors are partitioned into clusters and only a fraction of clusters are searched during retrieval. We conduct a comprehensive analysis of dimensionality reduction for sparse vectors, and examine standard and spherical KMeans for partitioning. Our experiments demonstrate that IVF serves as an efficient solution for sparse MIPS. As byproducts, we identify two research opportunities and demonstrate their potential. First, we cast the IVF paradigm as a dynamic pruning technique and turn that insight into a novel organization of the inverted index for approximate MIPS for general sparse vectors. Second, we offer a unified regime for MIPS over vectors that have dense and sparse subspaces, and show its robustness to query distributions.
An Approximate Algorithm for Maximum Inner Product Search over Streaming Sparse Vectors
Jan 25, 2023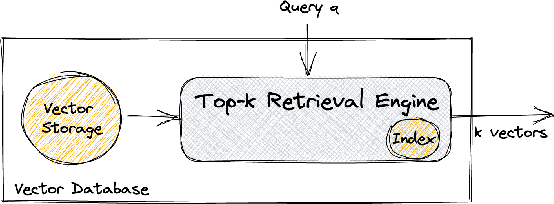


Maximum Inner Product Search or top-k retrieval on sparse vectors is well-understood in information retrieval, with a number of mature algorithms that solve it exactly. However, all existing algorithms are tailored to text and frequency-based similarity measures. To achieve optimal memory footprint and query latency, they rely on the near stationarity of documents and on laws governing natural languages. We consider, instead, a setup in which collections are streaming -- necessitating dynamic indexing -- and where indexing and retrieval must work with arbitrarily distributed real-valued vectors. As we show, existing algorithms are no longer competitive in this setup, even against naive solutions. We investigate this gap and present a novel approximate solution, called Sinnamon, that can efficiently retrieve the top-k results for sparse real valued vectors drawn from arbitrary distributions. Notably, Sinnamon offers levers to trade-off memory consumption, latency, and accuracy, making the algorithm suitable for constrained applications and systems. We give theoretical results on the error introduced by the approximate nature of the algorithm, and present an empirical evaluation of its performance on two hardware platforms and synthetic and real-valued datasets. We conclude by laying out concrete directions for future research on this general top-k retrieval problem over sparse vectors.
SDR: Efficient Neural Re-ranking using Succinct Document Representation
Oct 03, 2021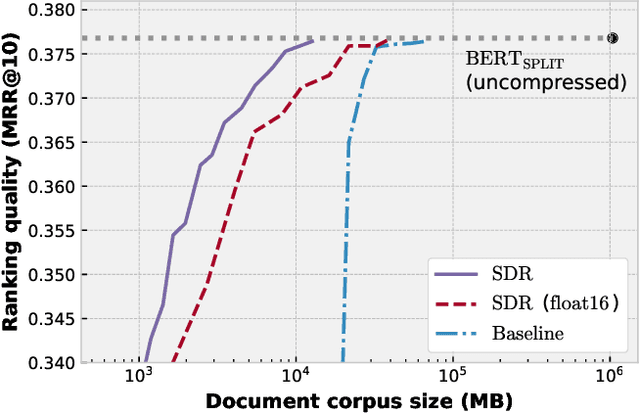
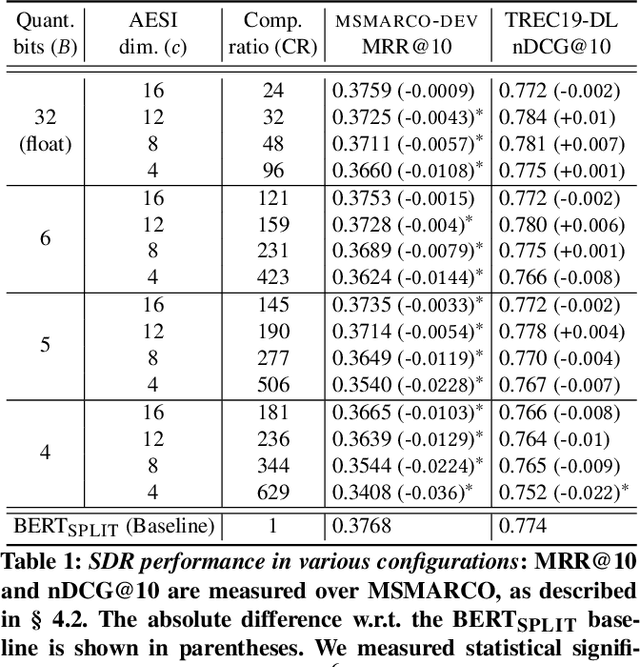
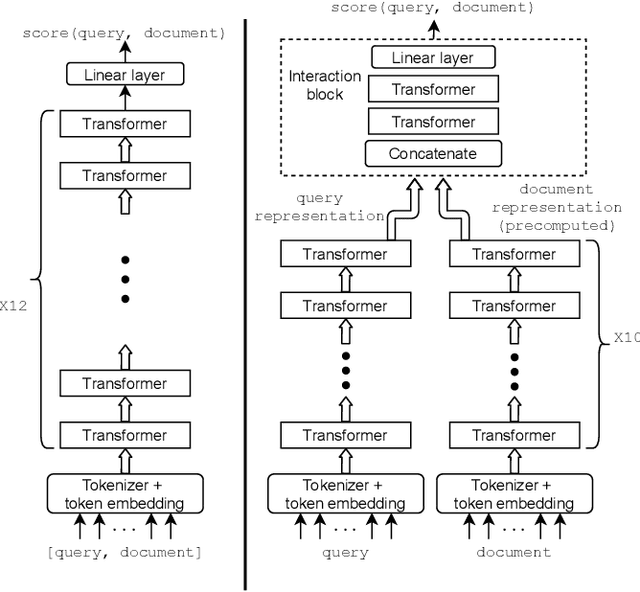
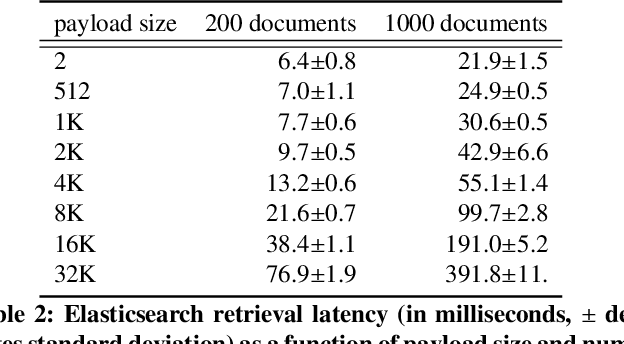
BERT based ranking models have achieved superior performance on various information retrieval tasks. However, the large number of parameters and complex self-attention operation come at a significant latency overhead. To remedy this, recent works propose late-interaction architectures, which allow pre-computation of intermediate document representations, thus reducing the runtime latency. Nonetheless, having solved the immediate latency issue, these methods now introduce storage costs and network fetching latency, which limits their adoption in real-life production systems. In this work, we propose the Succinct Document Representation (SDR) scheme that computes highly compressed intermediate document representations, mitigating the storage/network issue. Our approach first reduces the dimension of token representations by encoding them using a novel autoencoder architecture that uses the document's textual content in both the encoding and decoding phases. After this token encoding step, we further reduce the size of entire document representations using a modern quantization technique. Extensive evaluations on passage re-reranking on the MSMARCO dataset show that compared to existing approaches using compressed document representations, our method is highly efficient, achieving 4x-11.6x better compression rates for the same ranking quality.