 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Automatic Hands-on-Keyboard Attack Detection Using LLMs in EDR Solutions
Aug 04, 2024

Endpoint Detection and Remediation (EDR) platforms are essential for identifying and responding to cyber threats. This study presents a novel approach using Large Language Models (LLMs) to detect Hands-on-Keyboard (HOK) cyberattacks. Our method involves converting endpoint activity data into narrative forms that LLMs can analyze to distinguish between normal operations and potential HOK attacks. We address the challenges of interpreting endpoint data by segmenting narratives into windows and employing a dual training strategy. The results demonstrate that LLM-based models have the potential to outperform traditional machine learning methods, offering a promising direction for enhancing EDR capabilities and apply LLMs in cybersecurity.
QUIC-FL: Quick Unbiased Compression for Federated Learning
May 28, 2022
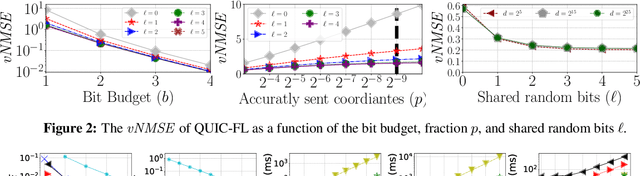
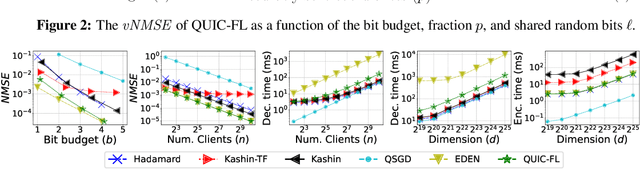
Distributed Mean Estimation (DME) is a fundamental building block in communication efficient federated learning. In DME, clients communicate their lossily compressed gradients to the parameter server, which estimates the average and updates the model. State of the art DME techniques apply either unbiased quantization methods, resulting in large estimation errors, or biased quantization methods, where unbiasing the result requires that the server decodes each gradient individually, which markedly slows the aggregation time. In this paper, we propose QUIC-FL, a DME algorithm that achieves the best of all worlds. QUIC-FL is unbiased, offers fast aggregation time, and is competitive with the most accurate (slow aggregation) DME techniques. To achieve this, we formalize the problem in a novel way that allows us to use standard solvers to design near-optimal unbiased quantization schemes.
SDR: Efficient Neural Re-ranking using Succinct Document Representation
Oct 03, 2021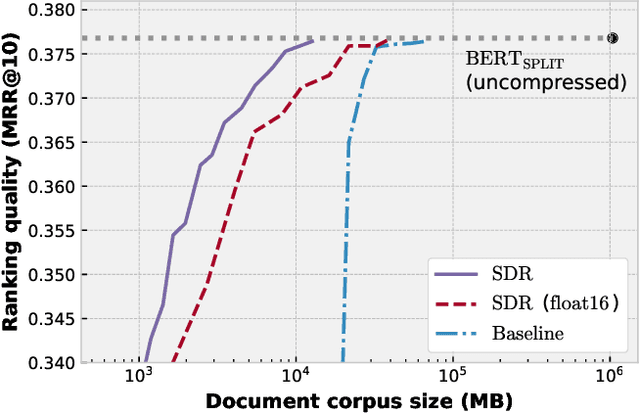
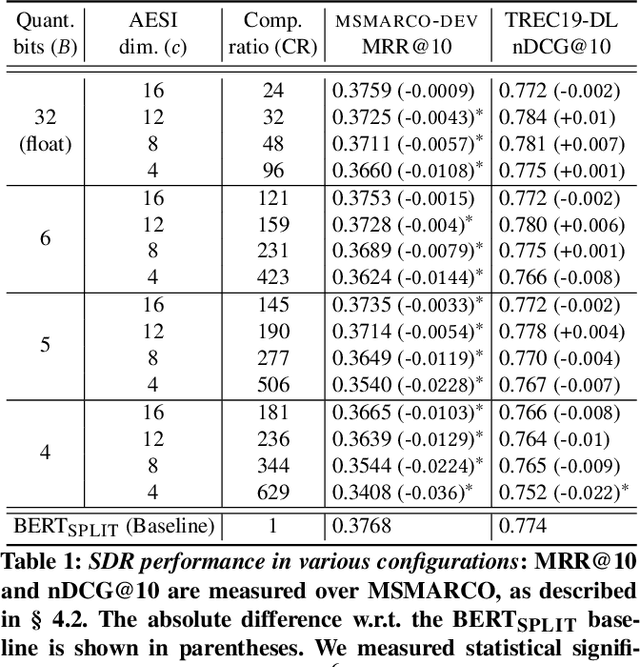
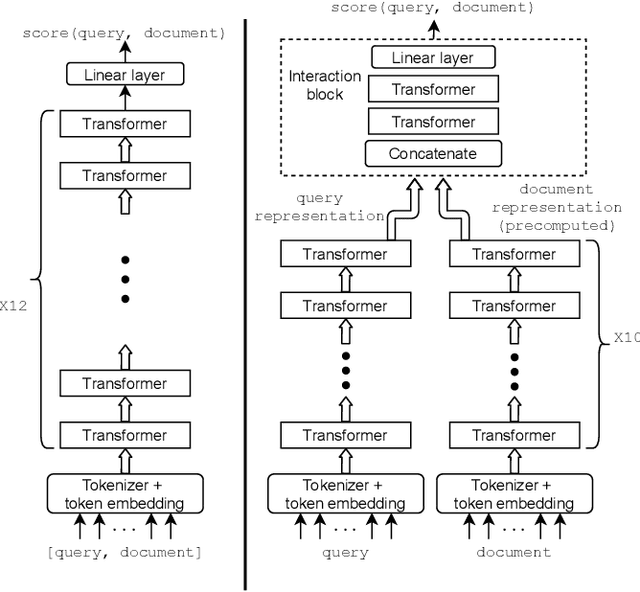
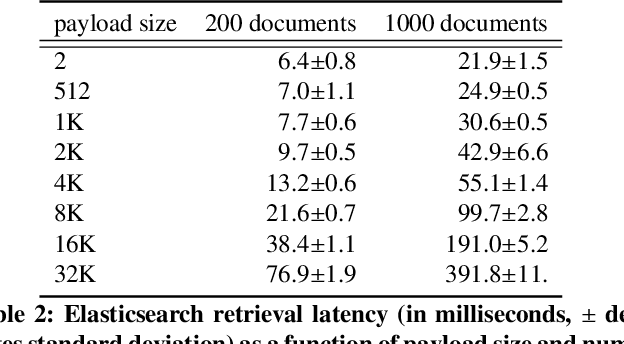
BERT based ranking models have achieved superior performance on various information retrieval tasks. However, the large number of parameters and complex self-attention operation come at a significant latency overhead. To remedy this, recent works propose late-interaction architectures, which allow pre-computation of intermediate document representations, thus reducing the runtime latency. Nonetheless, having solved the immediate latency issue, these methods now introduce storage costs and network fetching latency, which limits their adoption in real-life production systems. In this work, we propose the Succinct Document Representation (SDR) scheme that computes highly compressed intermediate document representations, mitigating the storage/network issue. Our approach first reduces the dimension of token representations by encoding them using a novel autoencoder architecture that uses the document's textual content in both the encoding and decoding phases. After this token encoding step, we further reduce the size of entire document representations using a modern quantization technique. Extensive evaluations on passage re-reranking on the MSMARCO dataset show that compared to existing approaches using compressed document representations, our method is highly efficient, achieving 4x-11.6x better compression rates for the same ranking quality.
Communication-Efficient Federated Learning via Robust Distributed Mean Estimation
Aug 19, 2021
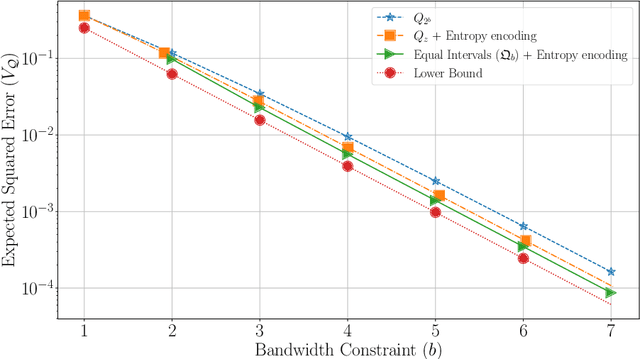
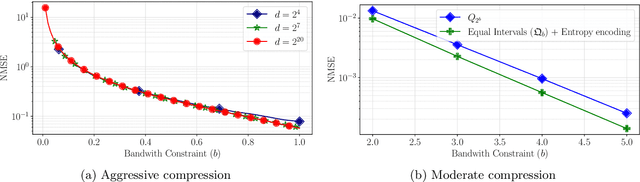
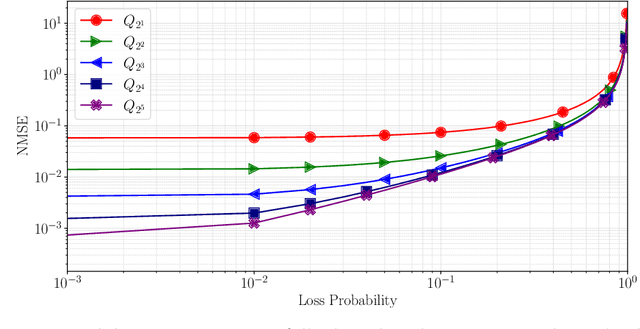
Federated learning commonly relies on algorithms such as distributed (mini-batch) SGD, where multiple clients compute their gradients and send them to a central coordinator for averaging and updating the model. To optimize the transmission time and the scalability of the training process, clients often use lossy compression to reduce the message sizes. DRIVE is a recent state of the art algorithm that compresses gradients using one bit per coordinate (with some lower-order overhead). In this technical report, we generalize DRIVE to support any bandwidth constraint as well as extend it to support heterogeneous client resources and make it robust to packet loss.
DRIVE: One-bit Distributed Mean Estimation
Jun 02, 2021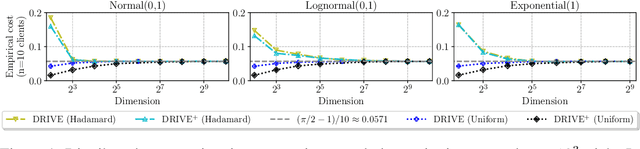
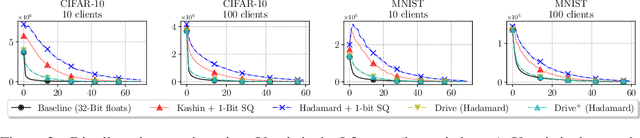
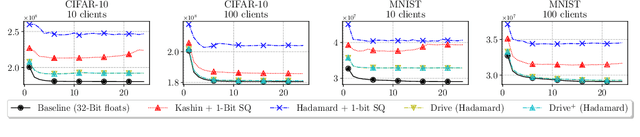
We consider the problem where $n$ clients transmit $d$-dimensional real-valued vectors using $d(1+o(1))$ bits each, in a manner that allows the receiver to approximately reconstruct their mean. Such compression problems naturally arise in distributed and federated learning. We provide novel mathematical results and derive computationally efficient algorithms that are more accurate than previous compression techniques. We evaluate our methods on a collection of distributed and federated learning tasks, using a variety of datasets, and show a consistent improvement over the state of the art.
Towards Realistic Byzantine-Robust Federated Learning
Apr 10, 2020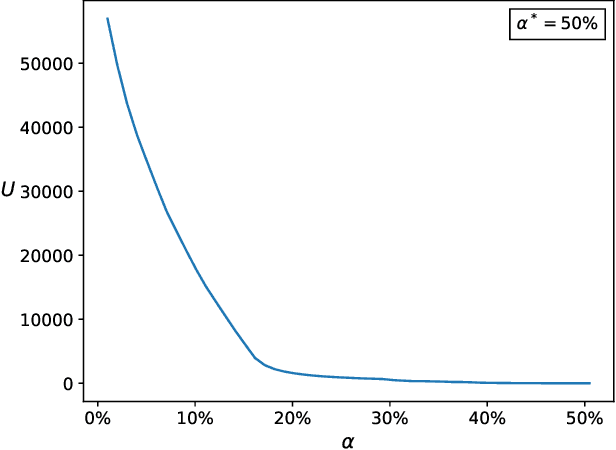

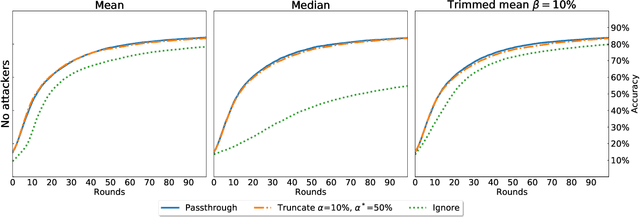
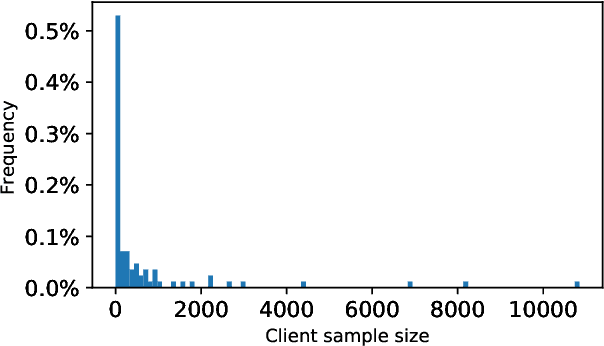
Federated Learning (FL) is a distributed machine learning paradigm where data is decentralized among clients who collaboratively train a model in a computation process coordinated by a central server. By assigning a weight to each client based on the proportion of data instances it possesses, the rate of convergence to an accurate joint model can be greatly accelerated. Some previous works studied FL in a Byzantine setting, where a fraction of the clients may send the server arbitrary or even malicious information regarding their model. However, these works either ignore the issue of data unbalancedness altogether or assume that client weights are known to the server a priori, whereas, in practice, it is likely that weights will be reported to the server by the clients themselves and therefore cannot be relied upon. We address this issue for the first time by proposing a practical weight-truncation-based preprocessing method and demonstrating empirically that it is able to strike a good balance between model quality and Byzantine-robustness. We also establish analytically that our method can be applied to a randomly-selected sample of client weights.