 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Realistic Byzantine-Robust Federated Learning
Paper and Code
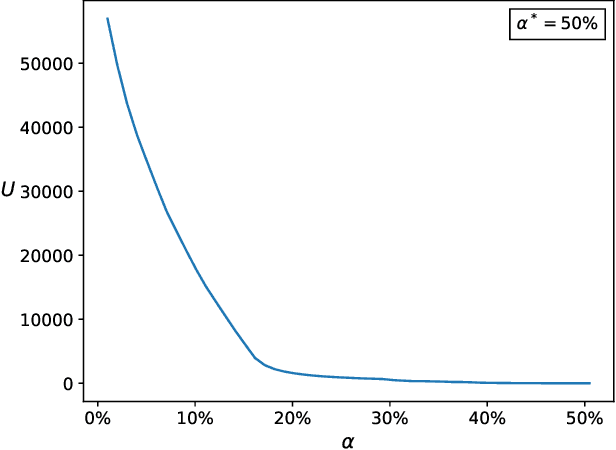

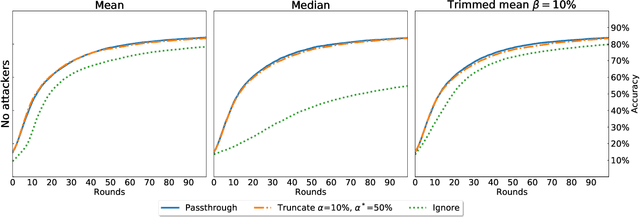
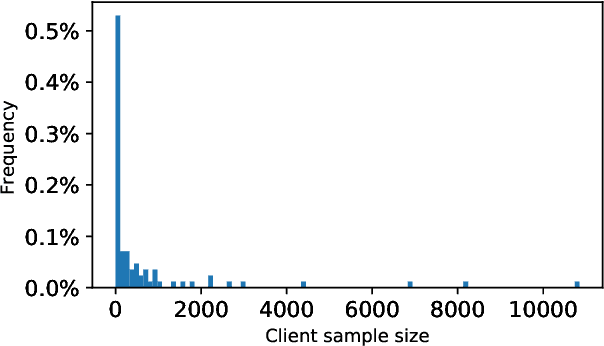
Federated Learning (FL) is a distributed machine learning paradigm where data is decentralized among clients who collaboratively train a model in a computation process coordinated by a central server. By assigning a weight to each client based on the proportion of data instances it possesses, the rate of convergence to an accurate joint model can be greatly accelerated. Some previous works studied FL in a Byzantine setting, where a fraction of the clients may send the server arbitrary or even malicious information regarding their model. However, these works either ignore the issue of data unbalancedness altogether or assume that client weights are known to the server a priori, whereas, in practice, it is likely that weights will be reported to the server by the clients themselves and therefore cannot be relied upon. We address this issue for the first time by proposing a practical weight-truncation-based preprocessing method and demonstrating empirically that it is able to strike a good balance between model quality and Byzantine-robustness. We also establish analytically that our method can be applied to a randomly-selected sample of client weights.