 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine-Learning Based Objective Function Selection for Community Detection
Mar 25, 2022



NECTAR, a Node-centric ovErlapping Community deTection AlgoRithm, presented in 2016 by Cohen et. al, chooses dynamically between two objective functions which function to optimize, based on the network on which it is invoked. This approach, as shown by Cohen et al., outperforms six state-of-the-art algorithms for overlapping community detection. In this work, we present NECTAR-ML, an extension of the NECTAR algorithm that uses a machine-learning based model for automating the selection of the objective function, trained and evaluated on a dataset of 15,755 synthetic and 7 real-world networks. Our analysis shows that in approximately 90% of the cases our model was able to successfully select the correct objective function. We conducted a competitive analysis of NECTAR and NECTAR-ML. NECTAR-ML was shown to significantly outperform NECTAR's ability to select the best objective function. We also conducted a competitive analysis of NECTAR-ML and two additional state-of-the-art multi-objective community detection algorithms. NECTAR-ML outperformed both algorithms in terms of average detection quality. Multiobjective EAs (MOEAs) are considered to be the most popular approach to solve MOP and the fact that NECTAR-ML significantly outperforms them demonstrates the effectiveness of ML-based objective function selection.
Early Detection of In-Memory Malicious Activity based on Run-time Environmental Features
Mar 30, 2021



In recent years malware has become increasingly sophisticated and difficult to detect prior to exploitation. While there are plenty of approaches to malware detection, they all have shortcomings when it comes to identifying malware correctly prior to exploitation. The trade-off is usually between false positives, causing overhead, preventing normal usage and the risk of letting the malware execute and cause damage to the target. We present a novel end-to-end solution for in-memory malicious activity detection done prior to exploitation by leveraging machine learning capabilities based on data from unique run-time logs, which are carefully curated in order to detect malicious activity in the memory of protected processes. This solution achieves reduced overhead and false positives as well as deployment simplicity. We implemented our solution for Windows-based systems, employing multi disciplinary knowledge from malware research, machine learning, and operating system internals. Our experimental evaluation yielded promising results. As we expect future sophisticated malware may try to bypass it, we also discuss how our solution can be extended to thwart such bypassing attempts.
DAEMON: Dataset-Agnostic Explainable Malware Classification Using Multi-Stage Feature Mining
Aug 04, 2020

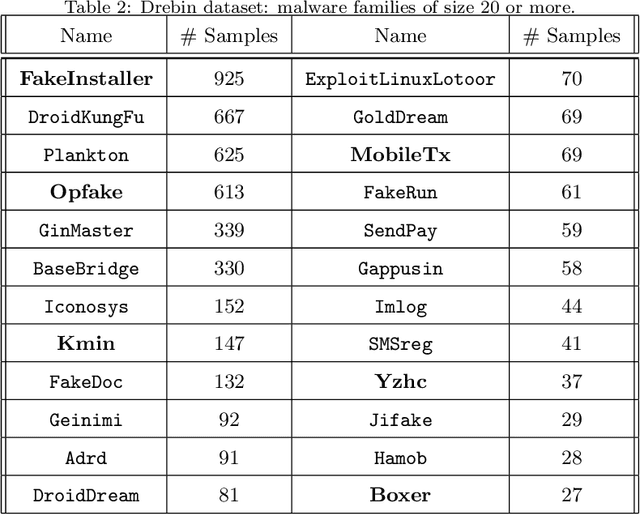

Numerous metamorphic and polymorphic malicious variants are generated automatically on a daily basis by mutation engines that transform the code of a malicious program while retaining its functionality, in order to evade signature-based detection. These automatic processes have greatly increased the number of malware variants, deeming their fully-manual analysis impossible. Malware classification is the task of determining to which family a new malicious variant belongs. Variants of the same malware family show similar behavioral patterns. Thus, classifying newly discovered variants helps assess the risks they pose and determine which of them should undergo manual analysis by a security expert. This motivated intense research in recent years of how to devise high-accuracy automatic tools for malware classification. In this paper, we present DAEMON - a novel dataset-agnostic and even platform-agnostic malware classifier. We've optimized DAEMON using a large-scale dataset of x86 binaries, belonging to a mix of several malware families targeting computers running Windows. We then applied it, without any algorithmic change, features re-engineering or parameter tuning, to two other large-scale datasets of malicious Android applications of numerous malware families. DAEMON obtained top-notch classification results on all datasets, making it the first provably dataset-agnostic malware classifier to date. An important byproduct of the type of features used by DAEMON and the manner in which they are mined is that its classification results are explainable.
Towards Realistic Byzantine-Robust Federated Learning
Apr 10, 2020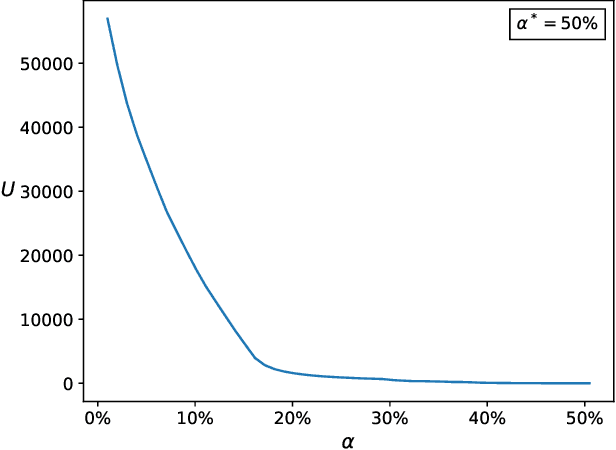

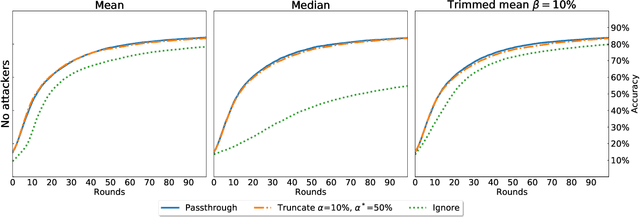
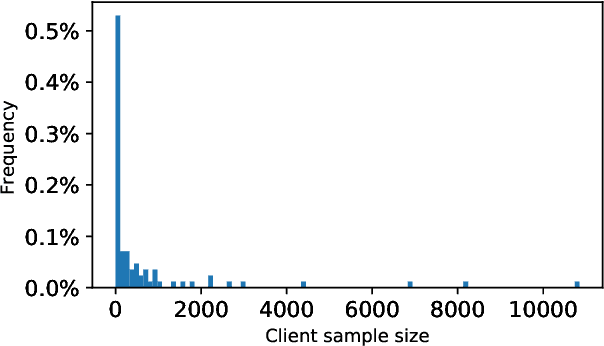
Federated Learning (FL) is a distributed machine learning paradigm where data is decentralized among clients who collaboratively train a model in a computation process coordinated by a central server. By assigning a weight to each client based on the proportion of data instances it possesses, the rate of convergence to an accurate joint model can be greatly accelerated. Some previous works studied FL in a Byzantine setting, where a fraction of the clients may send the server arbitrary or even malicious information regarding their model. However, these works either ignore the issue of data unbalancedness altogether or assume that client weights are known to the server a priori, whereas, in practice, it is likely that weights will be reported to the server by the clients themselves and therefore cannot be relied upon. We address this issue for the first time by proposing a practical weight-truncation-based preprocessing method and demonstrating empirically that it is able to strike a good balance between model quality and Byzantine-robustness. We also establish analytically that our method can be applied to a randomly-selected sample of client weights.
Detecting Malicious PowerShell Scripts Using Contextual Embeddings
May 23, 2019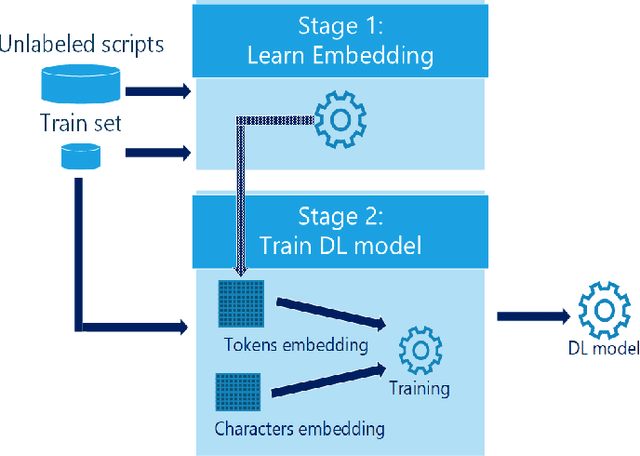



PowerShell is a command line shell, that is widely used in organizations for configuration management and task automation. Unfortunately, PowerShell is also increasingly used by cybercriminals for launching cyber attacks against organizations, mainly because it is pre-installed on Windows machines and it exposes strong functionality that may be leveraged by attackers. This makes the problem of detecting malicious PowerShell scripts both urgent and challenging. We address this important problem by presenting several novel deep learning based detectors of malicious PowerShell scripts. Our best model obtains a true positive rate of nearly 90% while maintaining a low false positive rate of less than 0.1%, indicating that it can be of practical value. Our models employ pre-trained contextual embeddings of words from the PowerShell "language". A contextual word embedding is able to project semantically similar words to proximate vectors in the embedding space. A known problem in the cybersecurity domain is that labeled data is relatively scarce in comparison with unlabeled data, making it difficult to devise effective supervised detection of malicious activity of many types. This is also the case with PowerShell scripts. Our work shows that this problem can be largely mitigated by learning a pre-trained contextual embedding based on unlabeled data. We trained our models' embedding layer using a scripts dataset that was enriched by a large corpus of unlabeled PowerShell scripts collected from public repositories. As established by our performance analysis, the use of unlabeled data for the embedding significantly improved the performance of our detectors. We estimate that the usage of pre-trained contextual embeddings based on unlabeled data for improved classification accuracy will find additional applications in the cybersecurity domain.
Detecting Malicious PowerShell Commands using Deep Neural Networks
Apr 14, 2018


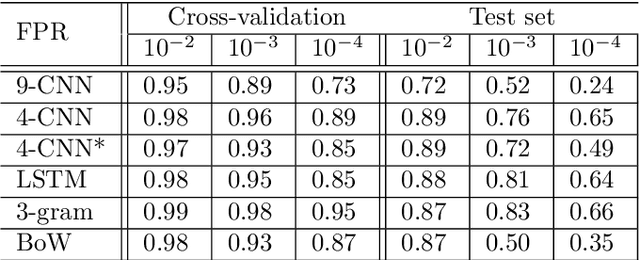
Microsoft's PowerShell is a command-line shell and scripting language that is installed by default on Windows machines. While PowerShell can be configured by administrators for restricting access and reducing vulnerabilities, these restrictions can be bypassed. Moreover, PowerShell commands can be easily generated dynamically, executed from memory, encoded and obfuscated, thus making the logging and forensic analysis of code executed by PowerShell challenging.For all these reasons, PowerShell is increasingly used by cybercriminals as part of their attacks' tool chain, mainly for downloading malicious contents and for lateral movement. Indeed, a recent comprehensive technical report by Symantec dedicated to PowerShell's abuse by cybercrimials reported on a sharp increase in the number of malicious PowerShell samples they received and in the number of penetration tools and frameworks that use PowerShell. This highlights the urgent need of developing effective methods for detecting malicious PowerShell commands.In this work, we address this challenge by implementing several novel detectors of malicious PowerShell commands and evaluating their performance. We implemented both "traditional" natural language processing (NLP) based detectors and detectors based on character-level convolutional neural networks (CNNs). Detectors' performance was evaluated using a large real-world dataset.Our evaluation results show that, although our detectors individually yield high performance, an ensemble detector that combines an NLP-based classifier with a CNN-based classifier provides the best performance, since the latter classifier is able to detect malicious commands that succeed in evading the former. Our analysis of these evasive commands reveals that some obfuscation patterns automatically detected by the CNN classifier are intrinsically difficult to detect using the NLP techniques we applied.
Fast Randomized Model Generation for Shapelet-Based Time Series Classification
Sep 23, 2012


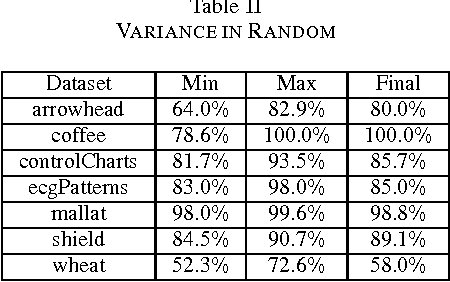
Time series classification is a field which has drawn much attention over the past decade. A new approach for classification of time series uses classification trees based on shapelets. A shapelet is a subsequence extracted from one of the time series in the dataset. A disadvantage of this approach is the time required for building the shapelet-based classification tree. The search for the best shapelet requires examining all subsequences of all lengths from all time series in the training set. A key goal of this work was to find an evaluation order of the shapelets space which enables fast convergence to an accurate model. The comparative analysis we conducted clearly indicates that a random evaluation order yields the best results. Our empirical analysis of the distribution of high-quality shapelets within the shapelets space provides insights into why randomized shapelets sampling is superior to alternative evaluation orders. We present an algorithm for randomized model generation for shapelet-based classification that converges extremely quickly to a model with surprisingly high accuracy after evaluating only an exceedingly small fraction of the shapelets space.