 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Randomized Model Generation for Shapelet-Based Time Series Classification
Paper and Code
Sep 23, 2012


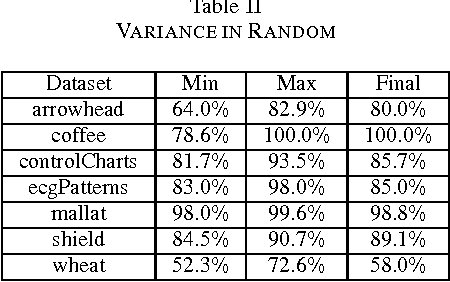
Time series classification is a field which has drawn much attention over the past decade. A new approach for classification of time series uses classification trees based on shapelets. A shapelet is a subsequence extracted from one of the time series in the dataset. A disadvantage of this approach is the time required for building the shapelet-based classification tree. The search for the best shapelet requires examining all subsequences of all lengths from all time series in the training set. A key goal of this work was to find an evaluation order of the shapelets space which enables fast convergence to an accurate model. The comparative analysis we conducted clearly indicates that a random evaluation order yields the best results. Our empirical analysis of the distribution of high-quality shapelets within the shapelets space provides insights into why randomized shapelets sampling is superior to alternative evaluation orders. We present an algorithm for randomized model generation for shapelet-based classification that converges extremely quickly to a model with surprisingly high accuracy after evaluating only an exceedingly small fraction of the shapelets space.