 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Can You Learn from Your Muscles? Learning Visual Representation from Human Interactions
Oct 16, 2020



Learning effective representations of visual data that generalize to a variety of downstream tasks has been a long quest for computer vision. Most representation learning approaches rely solely on visual data such as images or videos. In this paper, we explore a novel approach, where we use human interaction and attention cues to investigate whether we can learn better representations compared to visual-only representations. For this study, we collect a dataset of human interactions capturing body part movements and gaze in their daily lives. Our experiments show that our self-supervised representation that encodes interaction and attention cues outperforms a visual-only state-of-the-art method MoCo (He et al., 2020), on a variety of target tasks: scene classification (semantic), action recognition (temporal), depth estimation (geometric), dynamics prediction (physics) and walkable surface estimation (affordance).
Watching the World Go By: Representation Learning from Unlabeled Videos
Mar 18, 2020


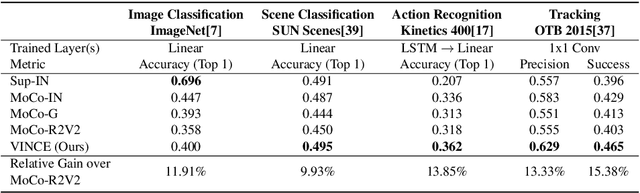
Recent single image unsupervised representation learning techniques show remarkable success on a variety of tasks. The basic principle in these works is instance discrimination: learning to differentiate between two augmented versions of the same image and a large batch of unrelated images. Networks learn to ignore the augmentation noise and extract semantically meaningful representations. Prior work uses artificial data augmentation techniques such as cropping, and color jitter which can only affect the image in superficial ways and are not aligned with how objects actually change e.g. occlusion, deformation, viewpoint change. In this paper, we argue that videos offer this natural augmentation for free. Videos can provide entirely new views of objects, show deformation, and even connect semantically similar but visually distinct concepts. We propose Video Noise Contrastive Estimation, a method for using unlabeled video to learn strong, transferable single image representations. We demonstrate improvements over recent unsupervised single image techniques, as well as over fully supervised ImageNet pretraining, across a variety of temporal and non-temporal tasks.
ALFRED: A Benchmark for Interpreting Grounded Instructions for Everyday Tasks
Dec 03, 2019
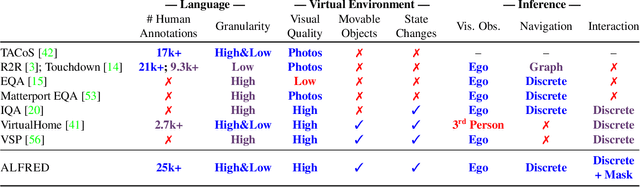
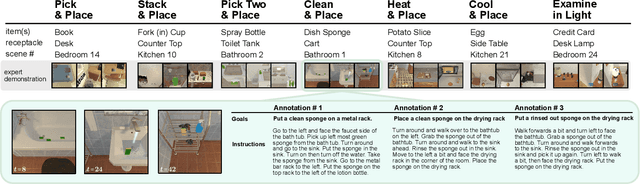
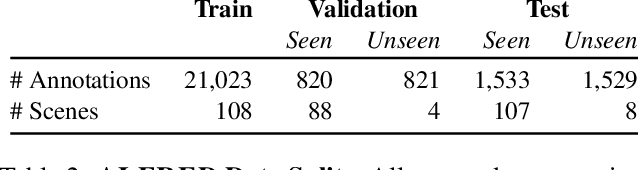
We present ALFRED (Action Learning From Realistic Environments and Directives), a benchmark for learning a mapping from natural language instructions and egocentric vision to sequences of actions for household tasks. Long composition rollouts with non-reversible state changes are among the phenomena we include to shrink the gap between research benchmarks and real-world applications. ALFRED consists of expert demonstrations in interactive visual environments for 25k natural language directives. These directives contain both high-level goals like "Rinse off a mug and place it in the coffee maker." and low-level language instructions like "Walk to the coffee maker on the right." ALFRED tasks are more complex in terms of sequence length, action space, and language than existing vision-and-language task datasets. We show that a baseline model designed for recent embodied vision-and-language tasks performs poorly on ALFRED, suggesting that there is significant room for developing innovative grounded visual language understanding models with this benchmark.
SplitNet: Sim2Sim and Task2Task Transfer for Embodied Visual Navigation
May 21, 2019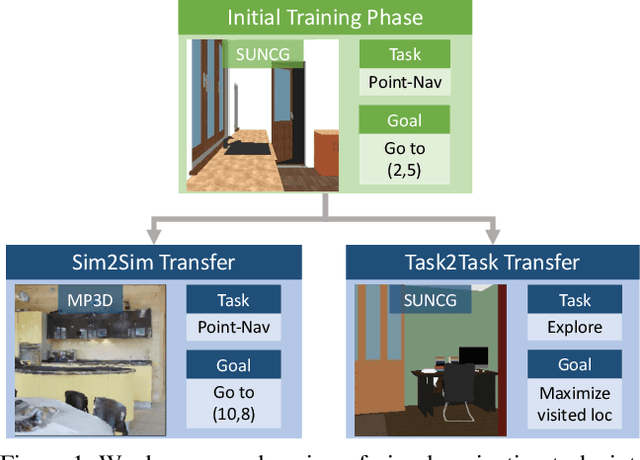
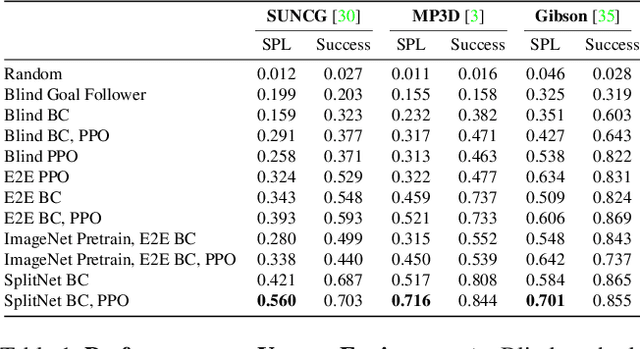
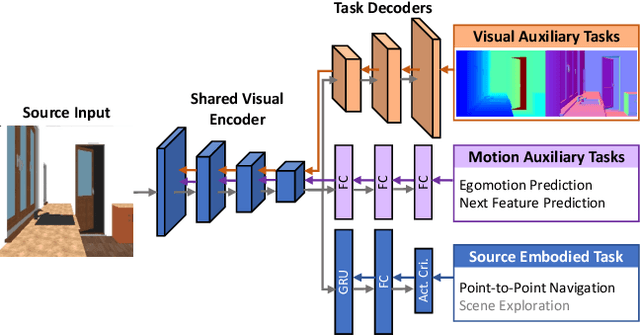
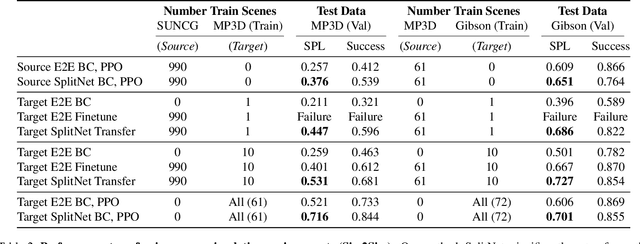
We propose SplitNet, a method for decoupling visual perception and policy learning. By incorporating auxiliary tasks and selective learning of portions of the model, we explicitly decompose the learning objectives for visual navigation into perceiving the world and acting on that perception. We show dramatic improvements over baseline models on transferring between simulators, an encouraging step towards Sim2Real. Additionally, SplitNet generalizes better to unseen environments from the same simulator and transfers faster and more effectively to novel embodied navigation tasks. Further, given only a small sample from a target domain, SplitNet can match the performance of traditional end-to-end pipelines which receive the entire dataset. Code and video are available at https://github.com/facebookresearch/splitnet and https://youtu.be/TJkZcsD2vrc
What Should I Do Now? Marrying Reinforcement Learning and Symbolic Planning
Jan 06, 2019
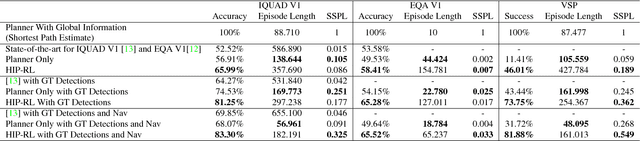
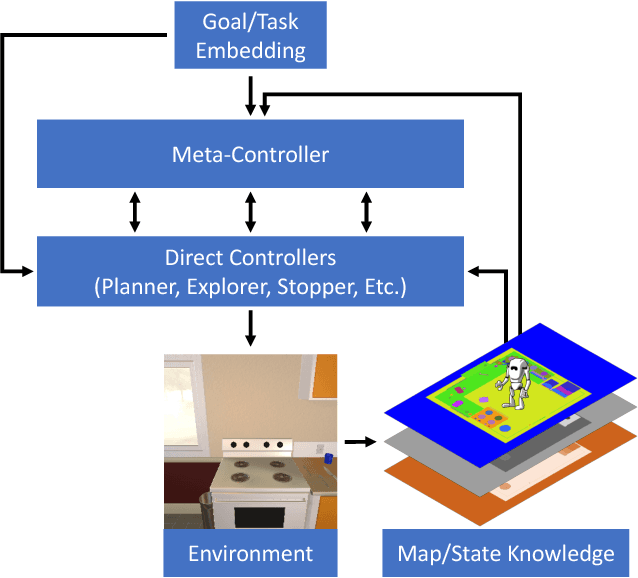
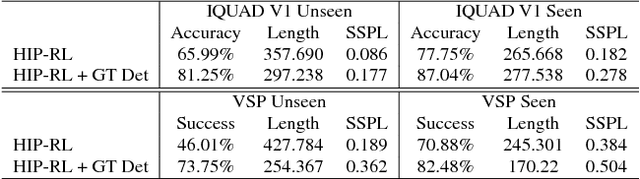
Long-term planning poses a major difficulty to many reinforcement learning algorithms. This problem becomes even more pronounced in dynamic visual environments. In this work we propose Hierarchical Planning and Reinforcement Learning (HIP-RL), a method for merging the benefits and capabilities of Symbolic Planning with the learning abilities of Deep Reinforcement Learning. We apply HIPRL to the complex visual tasks of interactive question answering and visual semantic planning and achieve state-of-the-art results on three challenging datasets all while taking fewer steps at test time and training in fewer iterations. Sample results can be found at youtu.be/0TtWJ_0mPfI
IQA: Visual Question Answering in Interactive Environments
Sep 06, 2018
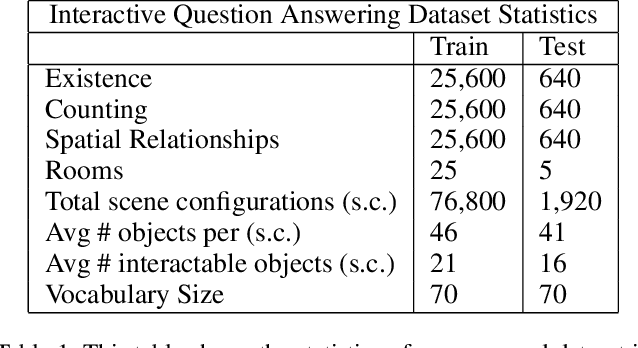
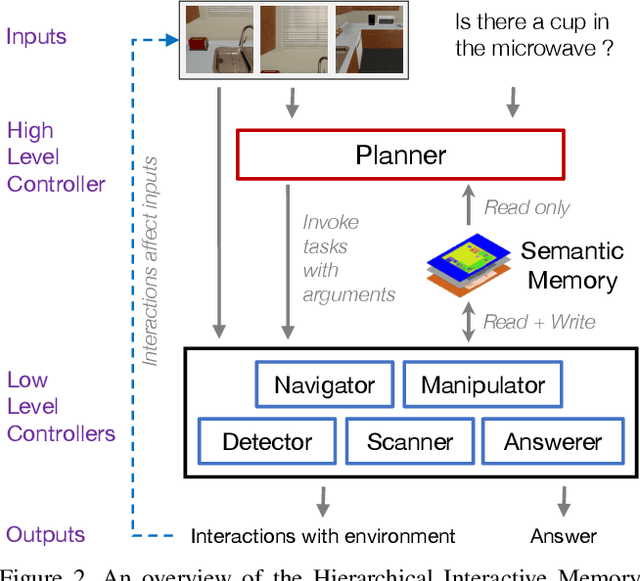

We introduce Interactive Question Answering (IQA), the task of answering questions that require an autonomous agent to interact with a dynamic visual environment. IQA presents the agent with a scene and a question, like: "Are there any apples in the fridge?" The agent must navigate around the scene, acquire visual understanding of scene elements, interact with objects (e.g. open refrigerators) and plan for a series of actions conditioned on the question. Popular reinforcement learning approaches with a single controller perform poorly on IQA owing to the large and diverse state space. We propose the Hierarchical Interactive Memory Network (HIMN), consisting of a factorized set of controllers, allowing the system to operate at multiple levels of temporal abstraction. To evaluate HIMN, we introduce IQUAD V1, a new dataset built upon AI2-THOR, a simulated photo-realistic environment of configurable indoor scenes with interactive objects (code and dataset available at https://github.com/danielgordon10/thor-iqa-cvpr-2018). IQUAD V1 has 75,000 questions, each paired with a unique scene configuration. Our experiments show that our proposed model outperforms popular single controller based methods on IQUAD V1. For sample questions and results, please view our video: https://youtu.be/pXd3C-1jr98
Re3 : Real-Time Recurrent Regression Networks for Visual Tracking of Generic Objects
Feb 26, 2018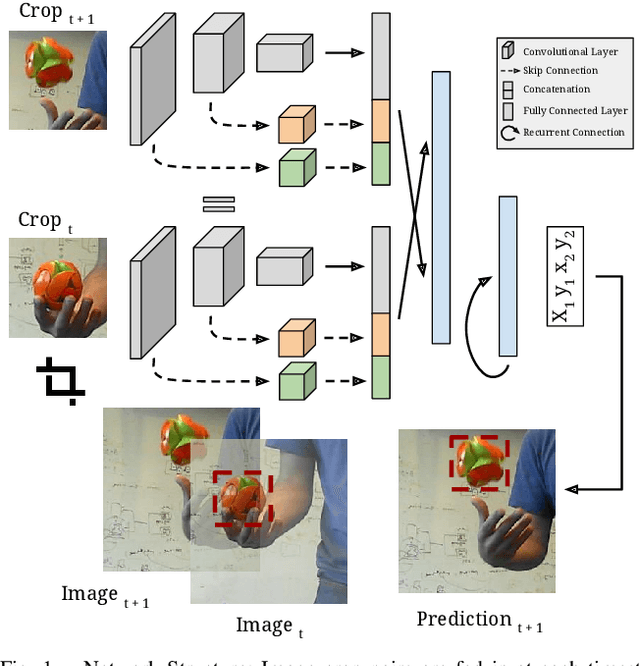
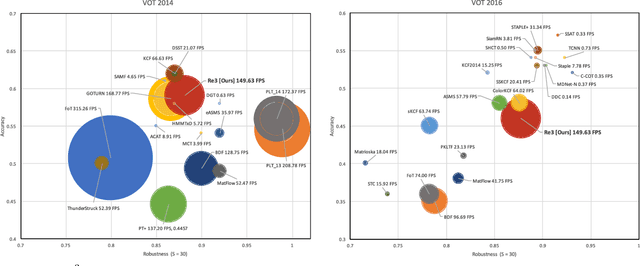
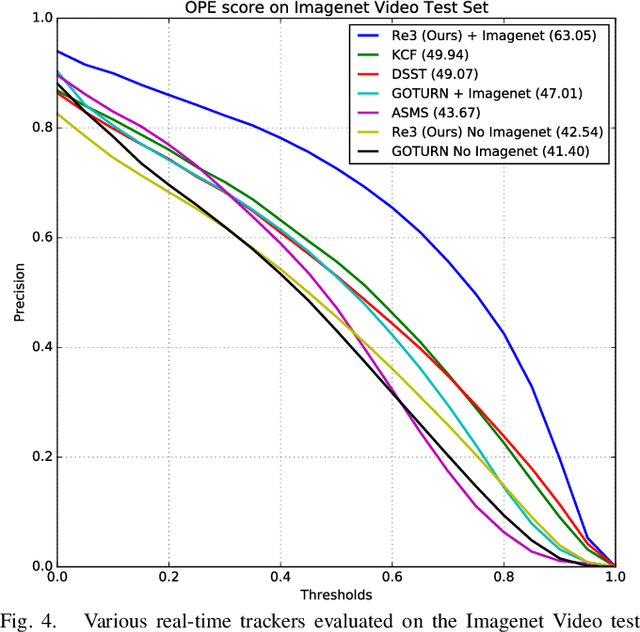
Robust object tracking requires knowledge and understanding of the object being tracked: its appearance, its motion, and how it changes over time. A tracker must be able to modify its underlying model and adapt to new observations. We present Re3, a real-time deep object tracker capable of incorporating temporal information into its model. Rather than focusing on a limited set of objects or training a model at test-time to track a specific instance, we pretrain our generic tracker on a large variety of objects and efficiently update on the fly; Re3 simultaneously tracks and updates the appearance model with a single forward pass. This lightweight model is capable of tracking objects at 150 FPS, while attaining competitive results on challenging benchmarks. We also show that our method handles temporary occlusion better than other comparable trackers using experiments that directly measure performance on sequences with occlusion.
* Presented at ICRA 2018
AI2-THOR: An Interactive 3D Environment for Visual AI
Dec 14, 2017

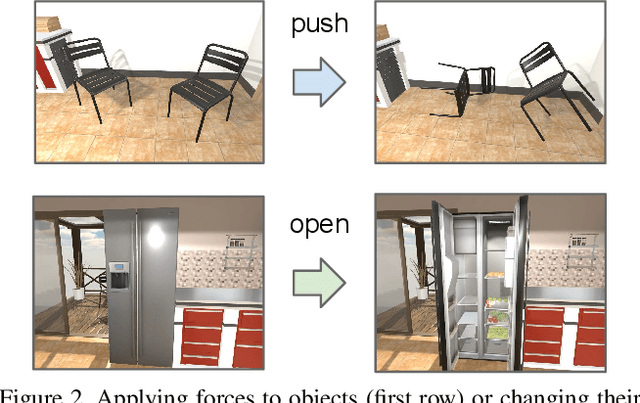
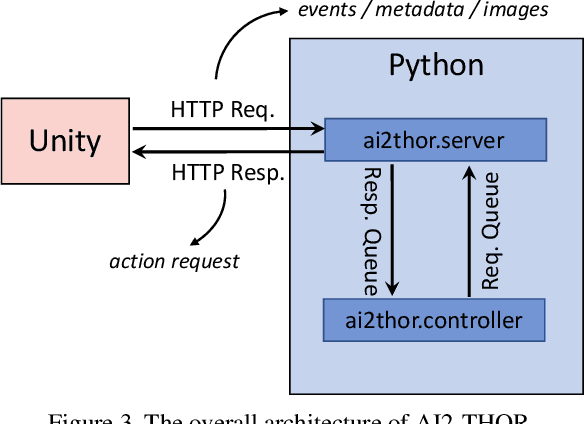
We introduce The House Of inteRactions (THOR), a framework for visual AI research, available at http://ai2thor.allenai.org. AI2-THOR consists of near photo-realistic 3D indoor scenes, where AI agents can navigate in the scenes and interact with objects to perform tasks. AI2-THOR enables research in many different domains including but not limited to deep reinforcement learning, imitation learning, learning by interaction, planning, visual question answering, unsupervised representation learning, object detection and segmentation, and learning models of cognition. The goal of AI2-THOR is to facilitate building visually intelligent models and push the research forward in this domain.
Visual Semantic Planning using Deep Successor Representations
Aug 15, 2017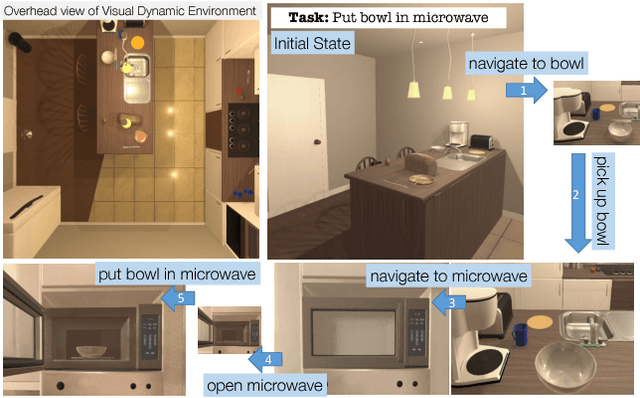
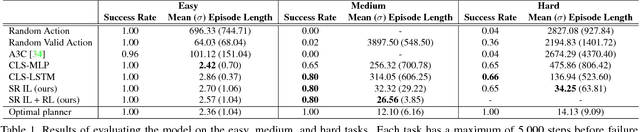

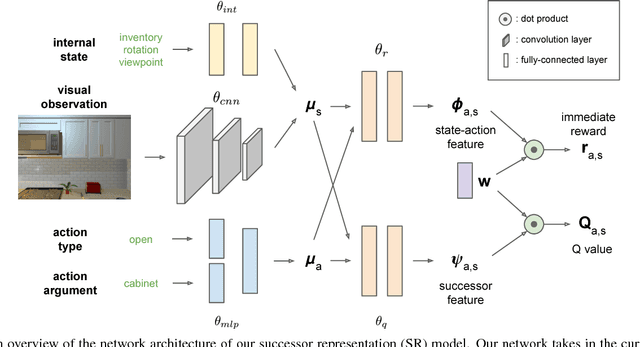
A crucial capability of real-world intelligent agents is their ability to plan a sequence of actions to achieve their goals in the visual world. In this work, we address the problem of visual semantic planning: the task of predicting a sequence of actions from visual observations that transform a dynamic environment from an initial state to a goal state. Doing so entails knowledge about objects and their affordances, as well as actions and their preconditions and effects. We propose learning these through interacting with a visual and dynamic environment. Our proposed solution involves bootstrapping reinforcement learning with imitation learning. To ensure cross task generalization, we develop a deep predictive model based on successor representations. Our experimental results show near optimal results across a wide range of tasks in the challenging THOR environment.
Fast Randomized Model Generation for Shapelet-Based Time Series Classification
Sep 23, 2012


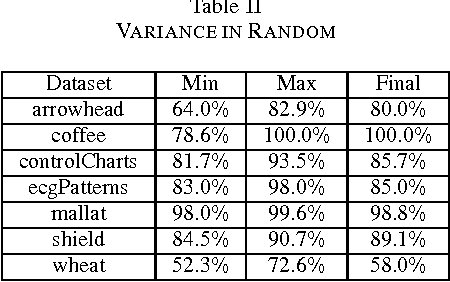
Time series classification is a field which has drawn much attention over the past decade. A new approach for classification of time series uses classification trees based on shapelets. A shapelet is a subsequence extracted from one of the time series in the dataset. A disadvantage of this approach is the time required for building the shapelet-based classification tree. The search for the best shapelet requires examining all subsequences of all lengths from all time series in the training set. A key goal of this work was to find an evaluation order of the shapelets space which enables fast convergence to an accurate model. The comparative analysis we conducted clearly indicates that a random evaluation order yields the best results. Our empirical analysis of the distribution of high-quality shapelets within the shapelets space provides insights into why randomized shapelets sampling is superior to alternative evaluation orders. We present an algorithm for randomized model generation for shapelet-based classification that converges extremely quickly to a model with surprisingly high accuracy after evaluating only an exceedingly small fraction of the shapelets space.