 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMolmoMotion: Forecasting Point Trajectories in 3D with Language Instruction
Jun 17, 2026Motion forecasting is central to visual intelligence: agents must anticipate how objects will move in order to plan actions, reason about physical interactions, and synthesize realistic futures. We argue that 3D points in world coordinates provide a general representation that is class-agnostic, view-stable, compact, and directly useful for downstream tasks. We formalize the task of goal-conditioned 3D point motion forecasting: given a short visual history, a set of 3D query points on an object of interest, and a language description of the intended goal, the model predicts the future 3D trajectory of each point. We introduce a full stack to study this task at scale: (1) MolmoMotion-1M is a large corpus of action-described, object-grounded 3D point trajectories annotated from 1.16M unconstrained videos; (2) PointMotionBench is a human-verified benchmark spanning 111 object categories and 61 motion types; and (3) MolmoMotion is a general motion forecasting model that supports both autoregressive coordinate prediction and flow-matching-based trajectory generation. MolmoMotion accurately predicts diverse motion patterns with different language instructions, and significantly outperforms existing motion prediction baselines on PointMotionBench. Finally, we show that the learned 3D motion prior transfers well to downstream applications: it improves training efficiency and generalization for robot manipulation, and its predicted trajectories provide effective motion guidance for generative models to synthesize videos with more realistic object motion.
MolmoAct2: Action Reasoning Models for Real-world Deployment
May 04, 2026Vision-Language-Action (VLA) models aim to provide a single generalist controller for robots, but today's systems fall short on the criteria that matter for real-world deployment. Frontier models are closed, open-weight alternatives are tied to expensive hardware, reasoning-augmented policies pay prohibitive latency for their grounding, and fine-tuned success rates remain below the threshold for dependable use. We present MolmoAct2, a fully open action reasoning model built for practical deployment, advancing its predecessor along five axes. We introduce MolmoER, a VLM backbone specialized for spatial and embodied reasoning, trained on a 3.3M-sample corpus with a specialize-then-rehearse recipe. We release three new datasets spanning low-to-medium cost platforms, including MolmoAct2-BimanualYAM, 720 hours of teleoperated bimanual trajectories that constitute the largest open bimanual dataset to date, together with quality-filtered Franka (DROID) and SO100/101 subsets. We provide OpenFAST, an open-weight, open-data action tokenizer trained on millions of trajectories across five embodiments. We redesign the architecture to graft a flow-matching continuous-action expert onto a discrete-token VLM via per-layer KV-cache conditioning. Finally, we propose MolmoThink, an adaptive-depth reasoning variant that re-predicts depth tokens only for scene regions that change between timesteps, retaining geometric grounding at a fraction of prior latency. In the most extensive empirical study of any open VLA to date, spanning 7 simulation and real-world benchmarks, MolmoAct2 outperforms strong baselines including Pi-05, while MolmoER surpasses GPT-5 and Gemini Robotics ER-1.5 across 13 embodied-reasoning benchmarks. We release model weights, training code, and complete training data. Project page: https://allenai.org/blog/molmoact2
MolmoWeb: Open Visual Web Agent and Open Data for the Open Web
Apr 09, 2026Web agents--autonomous systems that navigate and execute tasks on the web on behalf of users--have the potential to transform how people interact with the digital world. However, the most capable web agents today rely on proprietary models with undisclosed training data and recipes, limiting scientific understanding, reproducibility, and community-driven progress. We believe agents for the open web should be built in the open. To this end, we introduce (1) MolmoWebMix, a large and diverse mixture of browser task demonstrations and web-GUI perception data and (2) MolmoWeb, a family of fully open multimodal web agents. Specifically, MolmoWebMix combines over 100K synthetic task trajectories from multiple complementary generation pipelines with 30K+ human demonstrations, atomic web-skill trajectories, and GUI perception data, including referring expression grounding and screenshot question answering. MolmoWeb agents operate as instruction-conditioned visual-language action policies: given a task instruction and a webpage screenshot, they predict the next browser action, requiring no access to HTML, accessibility trees, or specialized APIs. Available in 4B and 8B size, on browser-use benchmarks like WebVoyager, Online-Mind2Web, and DeepShop, MolmoWeb agents achieve state-of-the-art results outperforming similar scale open-weight-only models such as Fara-7B, UI-Tars-1.5-7B, and Holo1-7B. MolmoWeb-8B also surpasses set-of-marks (SoM) agents built on much larger closed frontier models like GPT-4o. We further demonstrate consistent gains through test-time scaling via parallel rollouts with best-of-N selection, achieving 94.7% and 60.5% pass@4 (compared to 78.2% and 35.3% pass@1) on WebVoyager and Online-Mind2Web respectively. We will release model checkpoints, training data, code, and a unified evaluation harness to enable reproducibility and accelerate open research on web agents.
WildDet3D: Scaling Promptable 3D Detection in the Wild
Apr 09, 2026Understanding objects in 3D from a single image is a cornerstone of spatial intelligence. A key step toward this goal is monocular 3D object detection--recovering the extent, location, and orientation of objects from an input RGB image. To be practical in the open world, such a detector must generalize beyond closed-set categories, support diverse prompt modalities, and leverage geometric cues when available. Progress is hampered by two bottlenecks: existing methods are designed for a single prompt type and lack a mechanism to incorporate additional geometric cues, and current 3D datasets cover only narrow categories in controlled environments, limiting open-world transfer. In this work we address both gaps. First, we introduce WildDet3D, a unified geometry-aware architecture that natively accepts text, point, and box prompts and can incorporate auxiliary depth signals at inference time. Second, we present WildDet3D-Data, the largest open 3D detection dataset to date, constructed by generating candidate 3D boxes from existing 2D annotations and retaining only human-verified ones, yielding over 1M images across 13.5K categories in diverse real-world scenes. WildDet3D establishes a new state-of-the-art across multiple benchmarks and settings. In the open-world setting, it achieves 22.6/24.8 AP3D on our newly introduced WildDet3D-Bench with text and box prompts. On Omni3D, it reaches 34.2/36.4 AP3D with text and box prompts, respectively. In zero-shot evaluation, it achieves 40.3/48.9 ODS on Argoverse 2 and ScanNet. Notably, incorporating depth cues at inference time yields substantial additional gains (+20.7 AP on average across settings).
MolmoPoint: Better Pointing for VLMs with Grounding Tokens
Mar 30, 2026Grounding has become a fundamental capability of vision-language models (VLMs). Most existing VLMs point by generating coordinates as part of their text output, which requires learning a complicated coordinate system and results in a high token count. Instead, we propose a more intuitive pointing mechanism that directly selects the visual tokens that contain the target concept. Our model generates a special pointing token that cross-attends to the input image or video tokens and selects the appropriate one. To make this model more fine-grained, we follow these pointing tokens with an additional special token that selects a fine-grained subpatch within the initially selected region, and then a third token that specifies a location within that subpatch. We further show that performance improves by generating points sequentially in a consistent order, encoding the relative position of the previously selected point, and including a special no-more-points class when selecting visual tokens. Using this method, we set a new state-of-the-art on image pointing (70.7% on PointBench), set a new state-of-the-art among fully open models on GUI pointing (61.1% on ScreenSpotPro), and improve video pointing (59.1% human preference win rate vs. a text coordinate baseline) and tracking (+6.3% gain on Molmo2Track). We additionally show that our method achieves much higher sample efficiency and discuss the qualitative differences that emerge from this design change.
Unified Spatio-Temporal Token Scoring for Efficient Video VLMs
Mar 18, 2026Token pruning is essential for enhancing the computational efficiency of vision-language models (VLMs), particularly for video-based tasks where temporal redundancy is prevalent. Prior approaches typically prune tokens either (1) within the vision transformer (ViT) exclusively for unimodal perception tasks such as action recognition and object segmentation, without adapting to downstream vision-language tasks; or (2) only within the LLM while leaving the ViT output intact, often requiring complex text-conditioned token selection mechanisms. In this paper, we introduce Spatio-Temporal Token Scoring (STTS), a simple and lightweight module that prunes vision tokens across both the ViT and the LLM without text conditioning or token merging, and is fully compatible with end-to-end training. By learning how to score temporally via an auxiliary loss and spatially via LLM downstream gradients, aided by our efficient packing algorithm, STTS prunes 50% of vision tokens throughout the entire architecture, resulting in a 62% improvement in efficiency during both training and inference with only a 0.7% drop in average performance across 13 short and long video QA tasks. Efficiency gains increase with more sampled frames per video. Applying test-time scaling for long-video QA further yields performance gains of 0.5-1% compared to the baseline. Overall, STTS represents a novel, simple yet effective technique for unified, architecture-wide vision token pruning.
MolmoB0T: Large-Scale Simulation Enables Zero-Shot Manipulation
Mar 17, 2026A prevailing view in robot learning is that simulation alone is not enough; effective sim-to-real transfer is widely believed to require at least some real-world data collection or task-specific fine-tuning to bridge the gap between simulated and physical environments. We challenge that assumption. With sufficiently large-scale and diverse simulated synthetic training data, we show that zero-shot transfer to the real world is not only possible, but effective for both static and mobile manipulation. We introduce MolmoBot-Engine, a fully open-source pipeline for procedural data generation across robots, tasks, and diverse simulated environments in MolmoSpaces. With it, we release MolmoBot-Data, a dataset of 1.8 million expert trajectories for articulated object manipulation and pick-and-place tasks. We train three policy classes: MolmoBot, a Molmo2-based multi-frame vision-language model with a flow-matching action head; MolmoBot-Pi0, which replicates the $π_0$ architecture to enable direct comparison; and MolmoBot-SPOC, a lightweight policy suitable for edge deployment and amenable to RL fine-tuning. We evaluate on two robotic platforms: the Franka FR3 for tabletop manipulation tasks and the Rainbow Robotics RB-Y1 mobile manipulator for door opening, drawer manipulation, cabinet interaction, and mobile pick-and-place. Without any real-world fine-tuning, our policies achieve zero-shot transfer to unseen objects and environments. On tabletop pick-and-place, MolmoBot achieves a success rate of 79.2% in real world evaluations across 4 settings, outperforming $π_{0.5}$ at 39.2%. Our results demonstrate that procedural environment generation combined with diverse articulated assets can produce robust manipulation policies that generalize broadly to the real world. Technical Blog: https://allenai.org/blog/molmobot-robot-manipulation
MolmoSpaces: A Large-Scale Open Ecosystem for Robot Navigation and Manipulation
Feb 11, 2026Deploying robots at scale demands robustness to the long tail of everyday situations. The countless variations in scene layout, object geometry, and task specifications that characterize real environments are vast and underrepresented in existing robot benchmarks. Measuring this level of generalization requires infrastructure at a scale and diversity that physical evaluation alone cannot provide. We introduce MolmoSpaces, a fully open ecosystem to support large-scale benchmarking of robot policies. MolmoSpaces consists of over 230k diverse indoor environments, ranging from handcrafted household scenes to procedurally generated multiroom houses, populated with 130k richly annotated object assets, including 48k manipulable objects with 42M stable grasps. Crucially, these environments are simulator-agnostic, supporting popular options such as MuJoCo, Isaac, and ManiSkill. The ecosystem supports the full spectrum of embodied tasks: static and mobile manipulation, navigation, and multiroom long-horizon tasks requiring coordinated perception, planning, and interaction across entire indoor environments. We also design MolmoSpaces-Bench, a benchmark suite of 8 tasks in which robots interact with our diverse scenes and richly annotated objects. Our experiments show MolmoSpaces-Bench exhibits strong sim-to-real correlation (R = 0.96, \r{ho} = 0.98), confirm newer and stronger zero-shot policies outperform earlier versions in our benchmarks, and identify key sensitivities to prompt phrasing, initial joint positions, and camera occlusion. Through MolmoSpaces and its open-source assets and tooling, we provide a foundation for scalable data generation, policy training, and benchmark creation for robot learning research.
Molmo2: Open Weights and Data for Vision-Language Models with Video Understanding and Grounding
Jan 15, 2026Today's strongest video-language models (VLMs) remain proprietary. The strongest open-weight models either rely on synthetic data from proprietary VLMs, effectively distilling from them, or do not disclose their training data or recipe. As a result, the open-source community lacks the foundations needed to improve on the state-of-the-art video (and image) language models. Crucially, many downstream applications require more than just high-level video understanding; they require grounding -- either by pointing or by tracking in pixels. Even proprietary models lack this capability. We present Molmo2, a new family of VLMs that are state-of-the-art among open-source models and demonstrate exceptional new capabilities in point-driven grounding in single image, multi-image, and video tasks. Our key contribution is a collection of 7 new video datasets and 2 multi-image datasets, including a dataset of highly detailed video captions for pre-training, a free-form video Q&A dataset for fine-tuning, a new object tracking dataset with complex queries, and an innovative new video pointing dataset, all collected without the use of closed VLMs. We also present a training recipe for this data utilizing an efficient packing and message-tree encoding scheme, and show bi-directional attention on vision tokens and a novel token-weight strategy improves performance. Our best-in-class 8B model outperforms others in the class of open weight and data models on short videos, counting, and captioning, and is competitive on long-videos. On video-grounding Molmo2 significantly outperforms existing open-weight models like Qwen3-VL (35.5 vs 29.6 accuracy on video counting) and surpasses proprietary models like Gemini 3 Pro on some tasks (38.4 vs 20.0 F1 on video pointing and 56.2 vs 41.1 J&F on video tracking).
Visual Representations inside the Language Model
Oct 06, 2025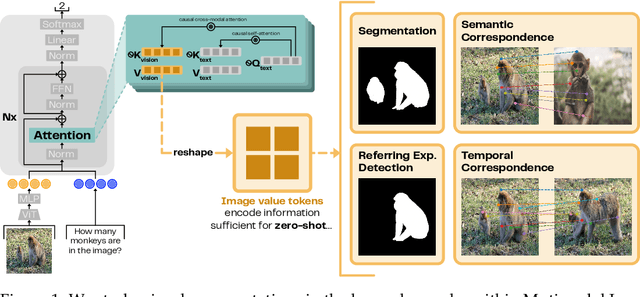

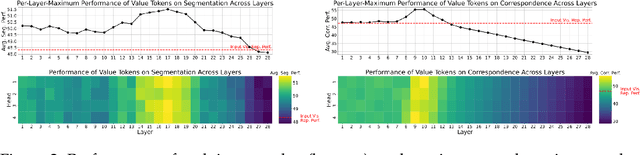
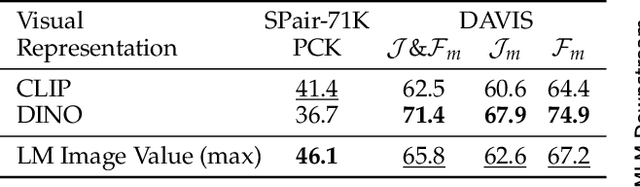
Despite interpretability work analyzing VIT encoders and transformer activations, we don't yet understand why Multimodal Language Models (MLMs) struggle on perception-heavy tasks. We offer an under-studied perspective by examining how popular MLMs (LLaVA-OneVision, Qwen2.5-VL, and Llama-3-LLaVA-NeXT) process their visual key-value tokens. We first study the flow of visual information through the language model, finding that image value tokens encode sufficient information to perform several perception-heavy tasks zero-shot: segmentation, semantic correspondence, temporal correspondence, and referring expression detection. We find that while the language model does augment the visual information received from the projection of input visual encodings-which we reveal correlates with overall MLM perception capability-it contains less visual information on several tasks than the equivalent visual encoder (SigLIP) that has not undergone MLM finetuning. Further, we find that the visual information corresponding to input-agnostic image key tokens in later layers of language models contains artifacts which reduce perception capability of the overall MLM. Next, we discuss controlling visual information in the language model, showing that adding a text prefix to the image input improves perception capabilities of visual representations. Finally, we reveal that if language models were able to better control their visual information, their perception would significantly improve; e.g., in 33.3% of Art Style questions in the BLINK benchmark, perception information present in the language model is not surfaced to the output! Our findings reveal insights into the role of key-value tokens in multimodal systems, paving the way for deeper mechanistic interpretability of MLMs and suggesting new directions for training their visual encoder and language model components.