 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMolmoAct: Action Reasoning Models that can Reason in Space
Aug 12, 2025



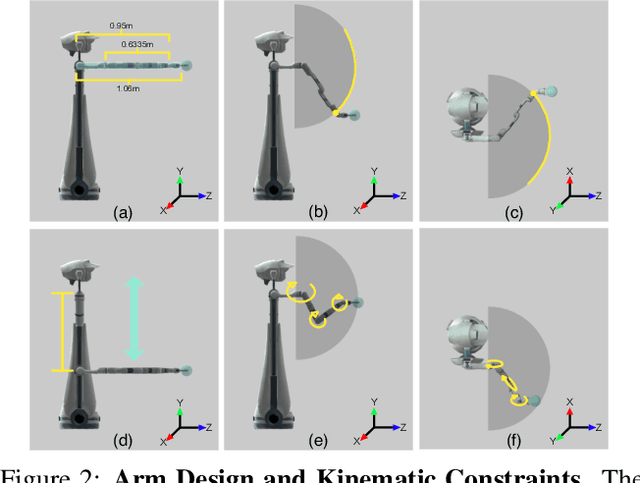
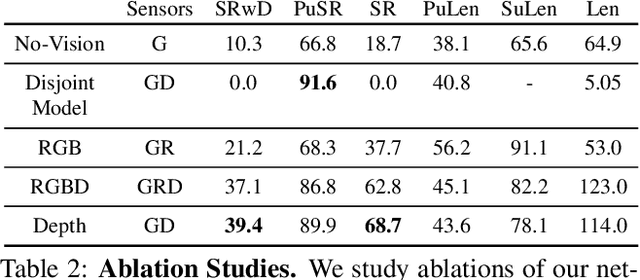
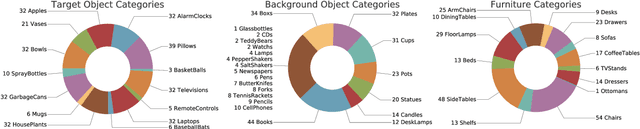
Reasoning is central to purposeful action, yet most robotic foundation models map perception and instructions directly to control, which limits adaptability, generalization, and semantic grounding. We introduce Action Reasoning Models (ARMs), a class of robotic foundation models that integrate perception, planning, and control through a structured three-stage pipeline. Our model, MolmoAct, encodes observations and instructions into depth-aware perception tokens, generates mid-level spatial plans as editable trajectory traces, and predicts precise low-level actions, enabling explainable and steerable behavior. MolmoAct-7B-D achieves strong performance across simulation and real-world settings: 70.5% zero-shot accuracy on SimplerEnv Visual Matching tasks, surpassing closed-source Pi-0 and GR00T N1; 86.6% average success on LIBERO, including an additional 6.3% gain over ThinkAct on long-horizon tasks; and in real-world fine-tuning, an additional 10% (single-arm) and an additional 22.7% (bimanual) task progression over Pi-0-FAST. It also outperforms baselines by an additional 23.3% on out-of-distribution generalization and achieves top human-preference scores for open-ended instruction following and trajectory steering. Furthermore, we release, for the first time, the MolmoAct Dataset -- a mid-training robot dataset comprising over 10,000 high quality robot trajectories across diverse scenarios and tasks. Training with this dataset yields an average 5.5% improvement in general performance over the base model. We release all model weights, training code, our collected dataset, and our action reasoning dataset, establishing MolmoAct as both a state-of-the-art robotics foundation model and an open blueprint for building ARMs that transform perception into purposeful action through structured reasoning. Blogpost: https://allenai.org/blog/molmoact
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Multimodal Models
Sep 25, 2024



Today's most advanced multimodal models remain proprietary. The strongest open-weight models rely heavily on synthetic data from proprietary VLMs to achieve good performance, effectively distilling these closed models into open ones. As a result, the community is still missing foundational knowledge about how to build performant VLMs from scratch. We present Molmo, a new family of VLMs that are state-of-the-art in their class of openness. Our key innovation is a novel, highly detailed image caption dataset collected entirely from human annotators using speech-based descriptions. To enable a wide array of user interactions, we also introduce a diverse dataset mixture for fine-tuning that includes in-the-wild Q&A and innovative 2D pointing data. The success of our approach relies on careful choices for the model architecture details, a well-tuned training pipeline, and, most critically, the quality of our newly collected datasets, all of which will be released. The best-in-class 72B model within the Molmo family not only outperforms others in the class of open weight and data models but also compares favorably against proprietary systems like GPT-4o, Claude 3.5, and Gemini 1.5 on both academic benchmarks and human evaluation. We will be releasing all of our model weights, captioning and fine-tuning data, and source code in the near future. Select model weights, inference code, and demo are available at https://molmo.allenai.org.
Holodeck: Language Guided Generation of 3D Embodied AI Environments
Dec 14, 20233D simulated environments play a critical role in Embodied AI, but their creation requires expertise and extensive manual effort, restricting their diversity and scope. To mitigate this limitation, we present Holodeck, a system that generates 3D environments to match a user-supplied prompt fully automatedly. Holodeck can generate diverse scenes, e.g., arcades, spas, and museums, adjust the designs for styles, and can capture the semantics of complex queries such as "apartment for a researcher with a cat" and "office of a professor who is a fan of Star Wars". Holodeck leverages a large language model (GPT-4) for common sense knowledge about what the scene might look like and uses a large collection of 3D assets from Objaverse to populate the scene with diverse objects. To address the challenge of positioning objects correctly, we prompt GPT-4 to generate spatial relational constraints between objects and then optimize the layout to satisfy those constraints. Our large-scale human evaluation shows that annotators prefer Holodeck over manually designed procedural baselines in residential scenes and that Holodeck can produce high-quality outputs for diverse scene types. We also demonstrate an exciting application of Holodeck in Embodied AI, training agents to navigate in novel scenes like music rooms and daycares without human-constructed data, which is a significant step forward in developing general-purpose embodied agents.
Imitating Shortest Paths in Simulation Enables Effective Navigation and Manipulation in the Real World
Dec 05, 2023



Reinforcement learning (RL) with dense rewards and imitation learning (IL) with human-generated trajectories are the most widely used approaches for training modern embodied agents. RL requires extensive reward shaping and auxiliary losses and is often too slow and ineffective for long-horizon tasks. While IL with human supervision is effective, collecting human trajectories at scale is extremely expensive. In this work, we show that imitating shortest-path planners in simulation produces agents that, given a language instruction, can proficiently navigate, explore, and manipulate objects in both simulation and in the real world using only RGB sensors (no depth map or GPS coordinates). This surprising result is enabled by our end-to-end, transformer-based, SPOC architecture, powerful visual encoders paired with extensive image augmentation, and the dramatic scale and diversity of our training data: millions of frames of shortest-path-expert trajectories collected inside approximately 200,000 procedurally generated houses containing 40,000 unique 3D assets. Our models, data, training code, and newly proposed 10-task benchmarking suite CHORES will be open-sourced.
OBJECT 3DIT: Language-guided 3D-aware Image Editing
Jul 20, 2023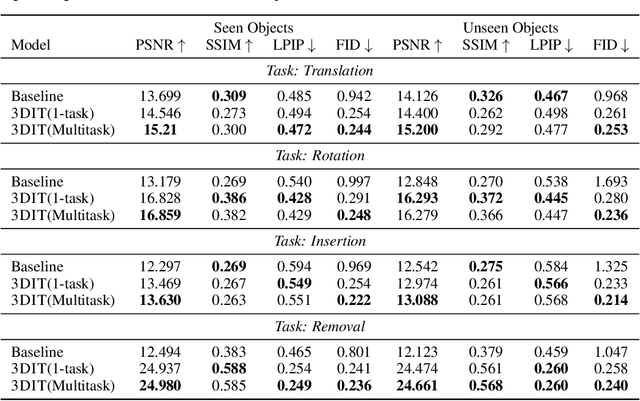


Existing image editing tools, while powerful, typically disregard the underlying 3D geometry from which the image is projected. As a result, edits made using these tools may become detached from the geometry and lighting conditions that are at the foundation of the image formation process. In this work, we formulate the newt ask of language-guided 3D-aware editing, where objects in an image should be edited according to a language instruction in context of the underlying 3D scene. To promote progress towards this goal, we release OBJECT: a dataset consisting of 400K editing examples created from procedurally generated 3D scenes. Each example consists of an input image, editing instruction in language, and the edited image. We also introduce 3DIT : single and multi-task models for four editing tasks. Our models show impressive abilities to understand the 3D composition of entire scenes, factoring in surrounding objects, surfaces, lighting conditions, shadows, and physically-plausible object configurations. Surprisingly, training on only synthetic scenes from OBJECT, editing capabilities of 3DIT generalize to real-world images.
Objaverse-XL: A Universe of 10M+ 3D Objects
Jul 11, 2023Natural language processing and 2D vision models have attained remarkable proficiency on many tasks primarily by escalating the scale of training data. However, 3D vision tasks have not seen the same progress, in part due to the challenges of acquiring high-quality 3D data. In this work, we present Objaverse-XL, a dataset of over 10 million 3D objects. Our dataset comprises deduplicated 3D objects from a diverse set of sources, including manually designed objects, photogrammetry scans of landmarks and everyday items, and professional scans of historic and antique artifacts. Representing the largest scale and diversity in the realm of 3D datasets, Objaverse-XL enables significant new possibilities for 3D vision. Our experiments demonstrate the improvements enabled with the scale provided by Objaverse-XL. We show that by training Zero123 on novel view synthesis, utilizing over 100 million multi-view rendered images, we achieve strong zero-shot generalization abilities. We hope that releasing Objaverse-XL will enable further innovations in the field of 3D vision at scale.
Objaverse: A Universe of Annotated 3D Objects
Dec 15, 2022Massive data corpora like WebText, Wikipedia, Conceptual Captions, WebImageText, and LAION have propelled recent dramatic progress in AI. Large neural models trained on such datasets produce impressive results and top many of today's benchmarks. A notable omission within this family of large-scale datasets is 3D data. Despite considerable interest and potential applications in 3D vision, datasets of high-fidelity 3D models continue to be mid-sized with limited diversity of object categories. Addressing this gap, we present Objaverse 1.0, a large dataset of objects with 800K+ (and growing) 3D models with descriptive captions, tags, and animations. Objaverse improves upon present day 3D repositories in terms of scale, number of categories, and in the visual diversity of instances within a category. We demonstrate the large potential of Objaverse via four diverse applications: training generative 3D models, improving tail category segmentation on the LVIS benchmark, training open-vocabulary object-navigation models for Embodied AI, and creating a new benchmark for robustness analysis of vision models. Objaverse can open new directions for research and enable new applications across the field of AI.
ProcTHOR: Large-Scale Embodied AI Using Procedural Generation
Jun 14, 2022

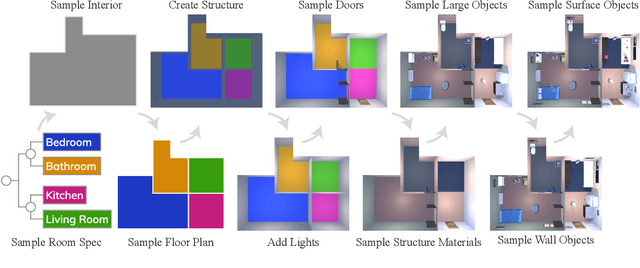
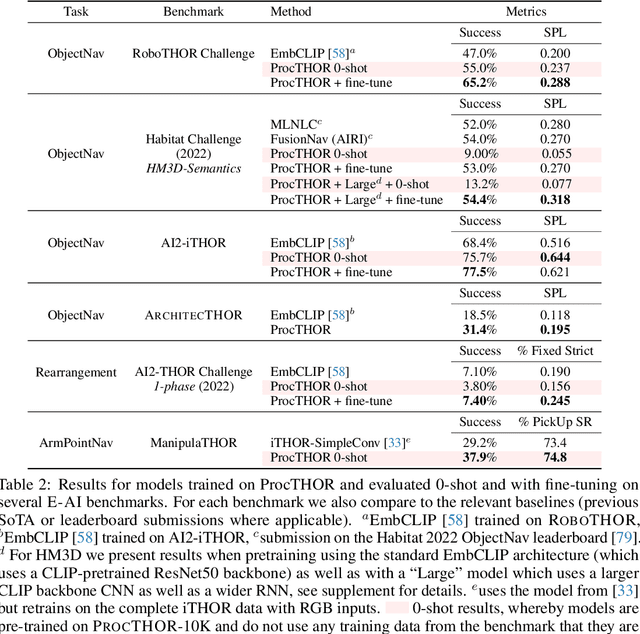
Massive datasets and high-capacity models have driven many recent advancements in computer vision and natural language understanding. This work presents a platform to enable similar success stories in Embodied AI. We propose ProcTHOR, a framework for procedural generation of Embodied AI environments. ProcTHOR enables us to sample arbitrarily large datasets of diverse, interactive, customizable, and performant virtual environments to train and evaluate embodied agents across navigation, interaction, and manipulation tasks. We demonstrate the power and potential of ProcTHOR via a sample of 10,000 generated houses and a simple neural model. Models trained using only RGB images on ProcTHOR, with no explicit mapping and no human task supervision produce state-of-the-art results across 6 embodied AI benchmarks for navigation, rearrangement, and arm manipulation, including the presently running Habitat 2022, AI2-THOR Rearrangement 2022, and RoboTHOR challenges. We also demonstrate strong 0-shot results on these benchmarks, via pre-training on ProcTHOR with no fine-tuning on the downstream benchmark, often beating previous state-of-the-art systems that access the downstream training data.
ManipulaTHOR: A Framework for Visual Object Manipulation
Apr 22, 2021

The domain of Embodied AI has recently witnessed substantial progress, particularly in navigating agents within their environments. These early successes have laid the building blocks for the community to tackle tasks that require agents to actively interact with objects in their environment. Object manipulation is an established research domain within the robotics community and poses several challenges including manipulator motion, grasping and long-horizon planning, particularly when dealing with oft-overlooked practical setups involving visually rich and complex scenes, manipulation using mobile agents (as opposed to tabletop manipulation), and generalization to unseen environments and objects. We propose a framework for object manipulation built upon the physics-enabled, visually rich AI2-THOR framework and present a new challenge to the Embodied AI community known as ArmPointNav. This task extends the popular point navigation task to object manipulation and offers new challenges including 3D obstacle avoidance, manipulating objects in the presence of occlusion, and multi-object manipulation that necessitates long term planning. Popular learning paradigms that are successful on PointNav challenges show promise, but leave a large room for improvement.
RoboTHOR: An Open Simulation-to-Real Embodied AI Platform
Apr 14, 2020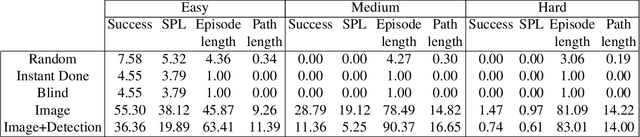

Visual recognition ecosystems (e.g. ImageNet, Pascal, COCO) have undeniably played a prevailing role in the evolution of modern computer vision. We argue that interactive and embodied visual AI has reached a stage of development similar to visual recognition prior to the advent of these ecosystems. Recently, various synthetic environments have been introduced to facilitate research in embodied AI. Notwithstanding this progress, the crucial question of how well models trained in simulation generalize to reality has remained largely unanswered. The creation of a comparable ecosystem for simulation-to-real embodied AI presents many challenges: (1) the inherently interactive nature of the problem, (2) the need for tight alignments between real and simulated worlds, (3) the difficulty of replicating physical conditions for repeatable experiments, (4) and the associated cost. In this paper, we introduce RoboTHOR to democratize research in interactive and embodied visual AI. RoboTHOR offers a framework of simulated environments paired with physical counterparts to systematically explore and overcome the challenges of simulation-to-real transfer, and a platform where researchers across the globe can remotely test their embodied models in the physical world. As a first benchmark, our experiments show there exists a significant gap between the performance of models trained in simulation when they are tested in both simulations and their carefully constructed physical analogs. We hope that RoboTHOR will spur the next stage of evolution in embodied computer vision. RoboTHOR can be accessed at the following link: https://ai2thor.allenai.org/robothor