 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSV3D: Novel Multi-view Synthesis and 3D Generation from a Single Image using Latent Video Diffusion
Mar 18, 2024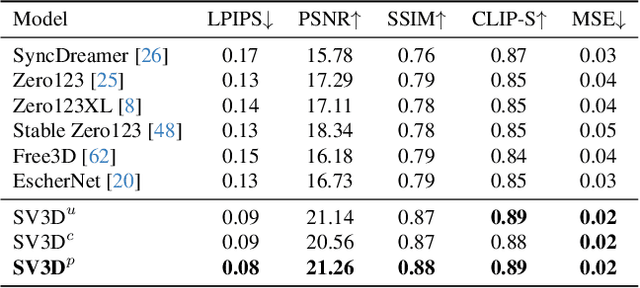
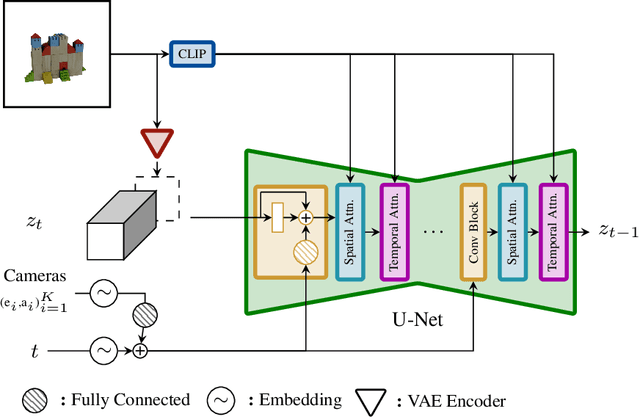
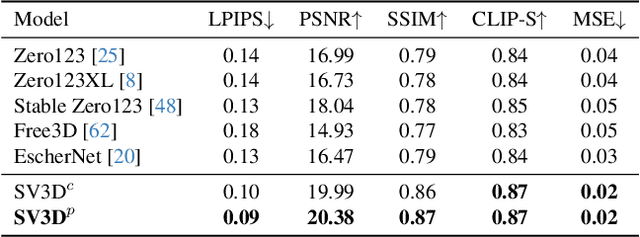
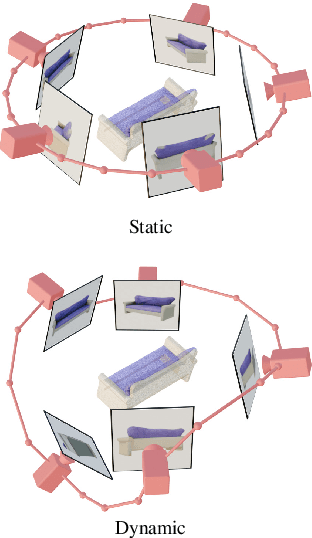
We present Stable Video 3D (SV3D) -- a latent video diffusion model for high-resolution, image-to-multi-view generation of orbital videos around a 3D object. Recent work on 3D generation propose techniques to adapt 2D generative models for novel view synthesis (NVS) and 3D optimization. However, these methods have several disadvantages due to either limited views or inconsistent NVS, thereby affecting the performance of 3D object generation. In this work, we propose SV3D that adapts image-to-video diffusion model for novel multi-view synthesis and 3D generation, thereby leveraging the generalization and multi-view consistency of the video models, while further adding explicit camera control for NVS. We also propose improved 3D optimization techniques to use SV3D and its NVS outputs for image-to-3D generation. Extensive experimental results on multiple datasets with 2D and 3D metrics as well as user study demonstrate SV3D's state-of-the-art performance on NVS as well as 3D reconstruction compared to prior works.
TripoSR: Fast 3D Object Reconstruction from a Single Image
Mar 04, 2024



This technical report introduces TripoSR, a 3D reconstruction model leveraging transformer architecture for fast feed-forward 3D generation, producing 3D mesh from a single image in under 0.5 seconds. Building upon the LRM network architecture, TripoSR integrates substantial improvements in data processing, model design, and training techniques. Evaluations on public datasets show that TripoSR exhibits superior performance, both quantitatively and qualitatively, compared to other open-source alternatives. Released under the MIT license, TripoSR is intended to empower researchers, developers, and creatives with the latest advancements in 3D generative AI.
Objaverse-XL: A Universe of 10M+ 3D Objects
Jul 11, 2023Natural language processing and 2D vision models have attained remarkable proficiency on many tasks primarily by escalating the scale of training data. However, 3D vision tasks have not seen the same progress, in part due to the challenges of acquiring high-quality 3D data. In this work, we present Objaverse-XL, a dataset of over 10 million 3D objects. Our dataset comprises deduplicated 3D objects from a diverse set of sources, including manually designed objects, photogrammetry scans of landmarks and everyday items, and professional scans of historic and antique artifacts. Representing the largest scale and diversity in the realm of 3D datasets, Objaverse-XL enables significant new possibilities for 3D vision. Our experiments demonstrate the improvements enabled with the scale provided by Objaverse-XL. We show that by training Zero123 on novel view synthesis, utilizing over 100 million multi-view rendered images, we achieve strong zero-shot generalization abilities. We hope that releasing Objaverse-XL will enable further innovations in the field of 3D vision at scale.