 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSV3D: Novel Multi-view Synthesis and 3D Generation from a Single Image using Latent Video Diffusion
Mar 18, 2024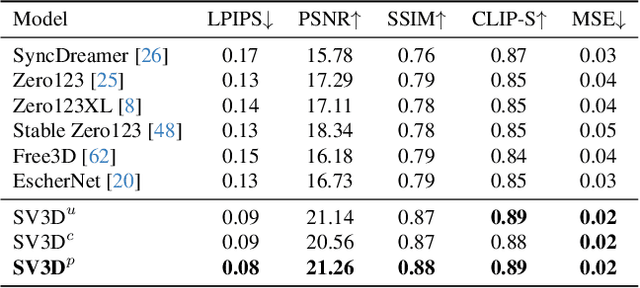
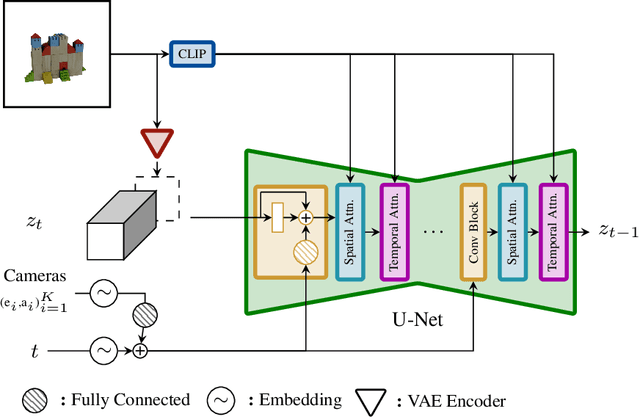
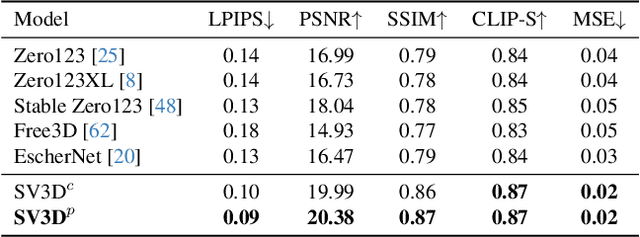
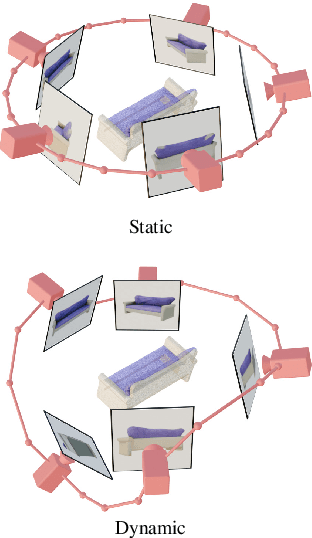
We present Stable Video 3D (SV3D) -- a latent video diffusion model for high-resolution, image-to-multi-view generation of orbital videos around a 3D object. Recent work on 3D generation propose techniques to adapt 2D generative models for novel view synthesis (NVS) and 3D optimization. However, these methods have several disadvantages due to either limited views or inconsistent NVS, thereby affecting the performance of 3D object generation. In this work, we propose SV3D that adapts image-to-video diffusion model for novel multi-view synthesis and 3D generation, thereby leveraging the generalization and multi-view consistency of the video models, while further adding explicit camera control for NVS. We also propose improved 3D optimization techniques to use SV3D and its NVS outputs for image-to-3D generation. Extensive experimental results on multiple datasets with 2D and 3D metrics as well as user study demonstrate SV3D's state-of-the-art performance on NVS as well as 3D reconstruction compared to prior works.
TripoSR: Fast 3D Object Reconstruction from a Single Image
Mar 04, 2024



This technical report introduces TripoSR, a 3D reconstruction model leveraging transformer architecture for fast feed-forward 3D generation, producing 3D mesh from a single image in under 0.5 seconds. Building upon the LRM network architecture, TripoSR integrates substantial improvements in data processing, model design, and training techniques. Evaluations on public datasets show that TripoSR exhibits superior performance, both quantitatively and qualitatively, compared to other open-source alternatives. Released under the MIT license, TripoSR is intended to empower researchers, developers, and creatives with the latest advancements in 3D generative AI.
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Nov 25, 2023



We present Stable Video Diffusion - a latent video diffusion model for high-resolution, state-of-the-art text-to-video and image-to-video generation. Recently, latent diffusion models trained for 2D image synthesis have been turned into generative video models by inserting temporal layers and finetuning them on small, high-quality video datasets. However, training methods in the literature vary widely, and the field has yet to agree on a unified strategy for curating video data. In this paper, we identify and evaluate three different stages for successful training of video LDMs: text-to-image pretraining, video pretraining, and high-quality video finetuning. Furthermore, we demonstrate the necessity of a well-curated pretraining dataset for generating high-quality videos and present a systematic curation process to train a strong base model, including captioning and filtering strategies. We then explore the impact of finetuning our base model on high-quality data and train a text-to-video model that is competitive with closed-source video generation. We also show that our base model provides a powerful motion representation for downstream tasks such as image-to-video generation and adaptability to camera motion-specific LoRA modules. Finally, we demonstrate that our model provides a strong multi-view 3D-prior and can serve as a base to finetune a multi-view diffusion model that jointly generates multiple views of objects in a feedforward fashion, outperforming image-based methods at a fraction of their compute budget. We release code and model weights at https://github.com/Stability-AI/generative-models .